因果学习在用户增长中的实践

分享嘉宾:李翱博士 快手
编辑整理:陈妃君 深圳大学
出品平台:DataFunTalk
导读:将因果推理与机器学习相结合,可以帮助我们解决在大量数据集当中检测到细微相关性,并判断其预测准确性的问题。我们将探索因果机器学习在用户增长中是如何应用的,采用了什么分析方法。
本文将围绕下面四点展开:
基础概念介绍
因果分析
因果机器学习
因果归因
1. 用户增长指标
在用户增长模型中,最显著的一个指标便是DAU(日活跃用户)的增长,在用户生命周期中主要体现在留存和活跃两个环节。另一方面是市场营销的增长,体现在用户付费、用户裂变等。
留存、活跃,在推荐系统中是比较简单的问题,因为它有明确的目标,即提升留存和活跃对应的指标。同时它又是复杂的,因为对于不同用户的标签具有延迟性,但在数学上是可解的。除此之外,它需要一定深度,需要通过层层剖析去间接优化其模型。
2. 因果分析应用方法
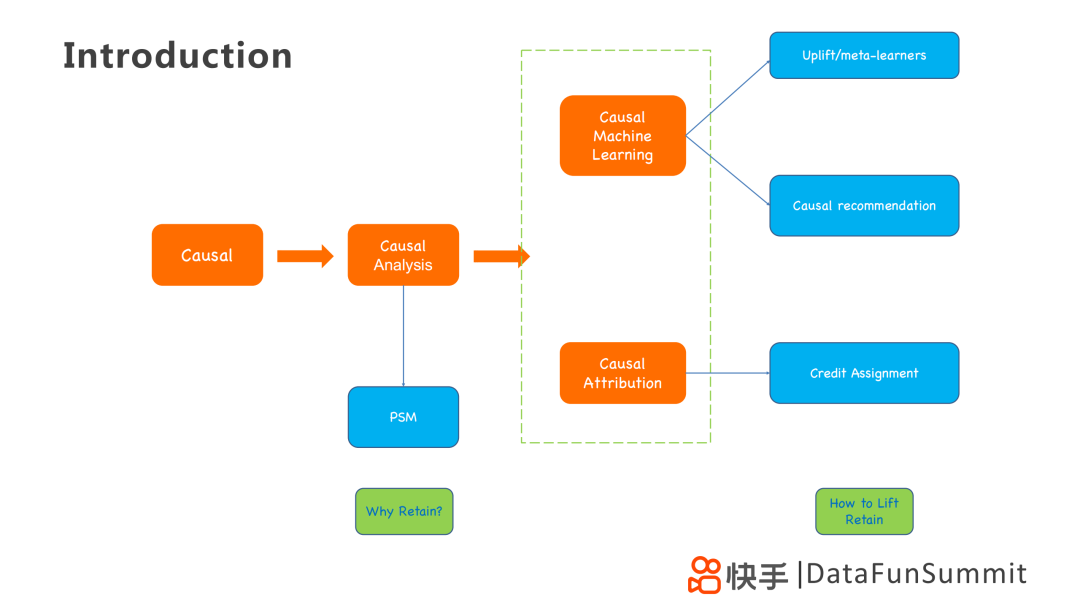
为解决上诉问题,可以从因果的角度出发,利用PSM(倾向评分匹配)统计方法进行因果分析,解决WHY的问题。
在其基础上,使用因果机器学习或者因果归因的技术手段去寻找提升指标的关键信息,例如Uplift / Meta-learner、Causal Recommendation和Credit Assignment模型,解决HOW的问题。
1. 相关性和因果性

在做因果分析之前,我们需要明确两个事件是存在相关性还是因果性,我们如何判断以及如何衡量呢?
第一个问题:一个回头率高的用户看了短视频,我们是否可以认为这些短视频促进了用户的留存?显然不是,这两者有性质上的偏差。
第二个问题:我们如何量化用户指标,例如用户点击、点赞、关注之类的指标,如何判断与留存指标之间是相关性的还是因果性的?
因此我们需要通过构造和去偏的思维方式去分析两个事件之间的关系,采用例如PSM的方法,以推进后续的因果分析。
下面我们就以考虑用户点击对留存的影响为例,介绍如何用因果分析和因果机器学习,解决用户增长的业务问题。
2. PSM倾向评分匹配统计方法

首先,利用PSM可以帮助我们研究用户点击和点赞行为对于用户的留存是否存在因果性。其检验方法如下:
第一步:通过倾向分数(propensity score),计算其实验模型,例如LR/XGBT处理模型(LR/XGBT Treatment Model)。
第二步:将两个对比实验组,通过算法的匹配,实现去偏。
第三步:采用KS-检验,计算P-value,核查协变量的平衡。
第四步:计算ATE(Average Treatment Effect),检验指标对最后结果的影响。

经过PSM之后,我们假设得到结论:点击会让留存率提升5%,意味着一个用户进行点击行为后,其留存可以提升5%,反映到相应的指标便是click_dau(点击日活跃人数)。例如click_dau提升了1%,那么整体留存率应该提升5%×1%=0.05%。

当treatment是连续的,例如点击不再是0→1的二元问题,而是从1变成更多的时候,我们会采取以下思路去解决问题:
得到回归模型后,去预测用户的点击数,但是这个方法比较复杂。
通过因果分析或其他一些match的方法解决。

在因果分析中,主要采用两种方法:
第一种:PSM,可以等价为带有权重的聚类。
第二种:Matching on Features,特征匹配,也是一种聚类,但是这个方法需要结合业务去挖掘有价值的特征和切合业务的指标进行匹配。
接下来介绍因果推荐的因果机器学习模型的一些应用。
1. 机器学习中的因果推理VS因果推理中的机器学习

机器学习中的因果推理和因果推理中的机器学习两个概念其实是不一样的,两者主要区别在于:
前者旨在把因果分析当做工具放到机器学习中去,后者旨在把机器学习当工具放到因果分析中去;
前者包含去偏算法和HTE非均匀处理效果模型,后者包含因果分析以及HTE非均匀处理效果模型。
2. 用户留存中的HTE分析
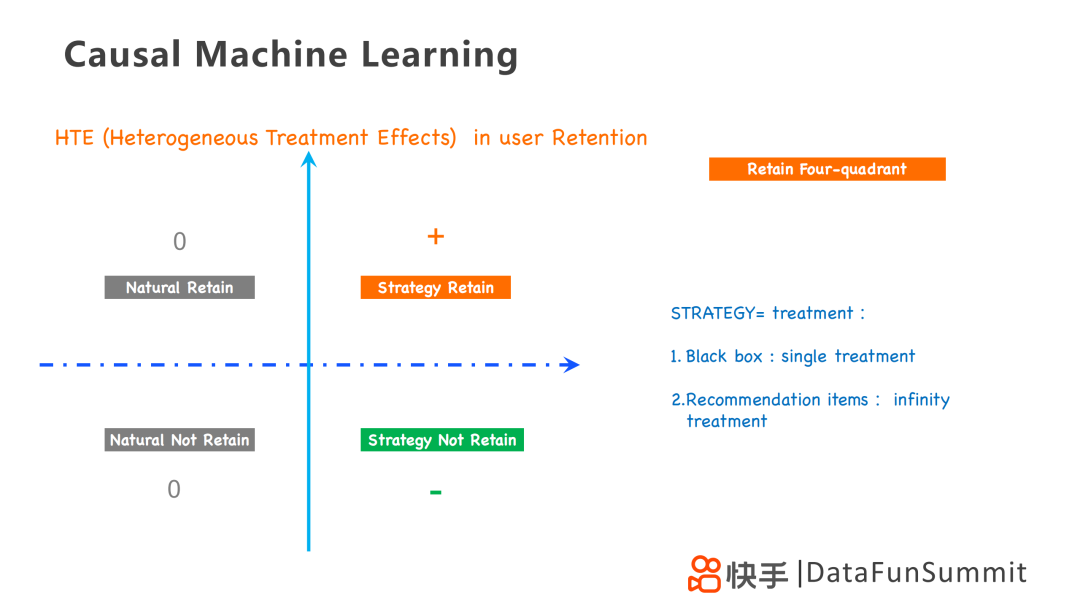
对于留存而言,HTE以是否采取策略和是否留存为维度划分为四个区域,其中采用的策略针对不同的业务问题,可以采用单一处理的黑盒策略,也可以采用无限处理的推荐策略。因此HTE是一个四象限问题,分别为:
第一象限为+1,采用策略的用户留存下来;
第二、三象限为0,自然用户,即不采用策略用户是否留存,其结果都为0;
第四象限为-1,采用策略的用户没有留存下来。

在自然模型中,采用打标签的方法,类似于现实生活中的AB test,但是可以对每个实验组设置一样的条件,就像“平行世界”一样,仅有是否treat和是否留存的标签,便可以直观的得到treatment对留存的影响。

在PML模型里,采用例如uplift模型,构造p_score相等的两个目标形成一组Pair,去寻找事实相反的配对,构建深度学习模型,简化深度学习网络,剔除一些无效样本,已形成有效的网络结构。
在这个基础上,我们有一些衍生的知识点:
Propensity dropout,即利用PSM去精简和修正机器学习网络。
将深度学习网络或神经网络中的一些网络节点去掉,不会影响最后的结果,甚至能提升其结果。
剔除无效网络的目的,是要保留有意义的部分,即使得lift的结果是正的或者是负的。
3. 用户活跃中的HTE分析

针对用户活跃,PML可以延伸为二元处理和连续处理的问题,然后基于可观测数据对HTE模型进行训练,使得模型更加稳健。

我们以0.5作为分水岭。指标active_days_sum为0-0.5的用户其活跃会减少0.1%,为0.5-1的用户其活跃会增加0.4%;指标duration_sum为0-0.5的用户其活跃会减少0.4%,为0.5-1的用户其活跃会增加0.5%。
得到这个结论,意味着当针对活跃天数的策略生效之后,dau的提升应该是0.2×0.4%=0.08%。
4. 数学模型:游戏币回收
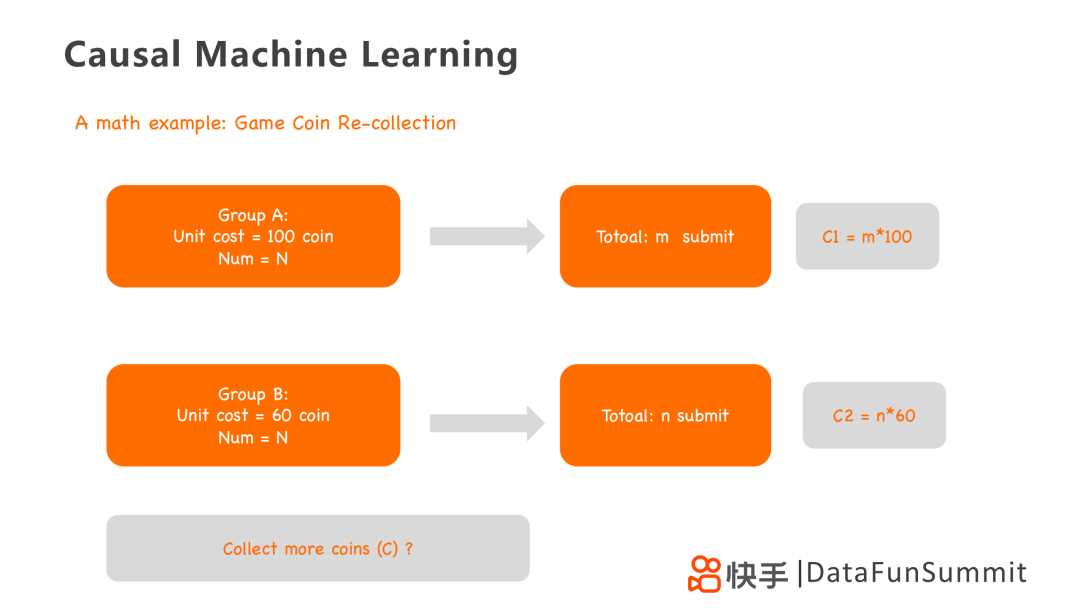
我们采用一个游戏币回收的数学模型来详细阐述采用Meta-learner和HTE模型来实现采取不同回收策略,以实现回收更多游戏币的方法。我们主要有两组回收策略:
A组:一次回收100个游戏币,总共设置N组。有m个玩家回收成功,总共回收C1=100×m个游戏币。
B组:一次回收60个游戏币,总共设置N组。有n个玩家回收成功,总共回收C2=60×n个游戏币。

可以采用的模型有Meta-learner、HTE和Online-learning,我们主要阐述前两种。可以从两个角度去评估我们的模型,一个是通过实验数据去评估收益的数据;一个是通过理论推导,精确地评估收益和涨幅。

第一个方法是Meta-learner,是T-learner模型的一个拓展,通过训练两个模型,并画出购买用户的累计分布曲线,找到两个策略最大的gap,在图中即为h。我们可以通过累计分布曲线去优化,得到第三个策略,是前两个策略的线性叠加。

累计分布曲线的计算方法如上图所示,计算得到两个策略在gap最大为h时,回收游戏币的差距为△=60×n(b-a)。
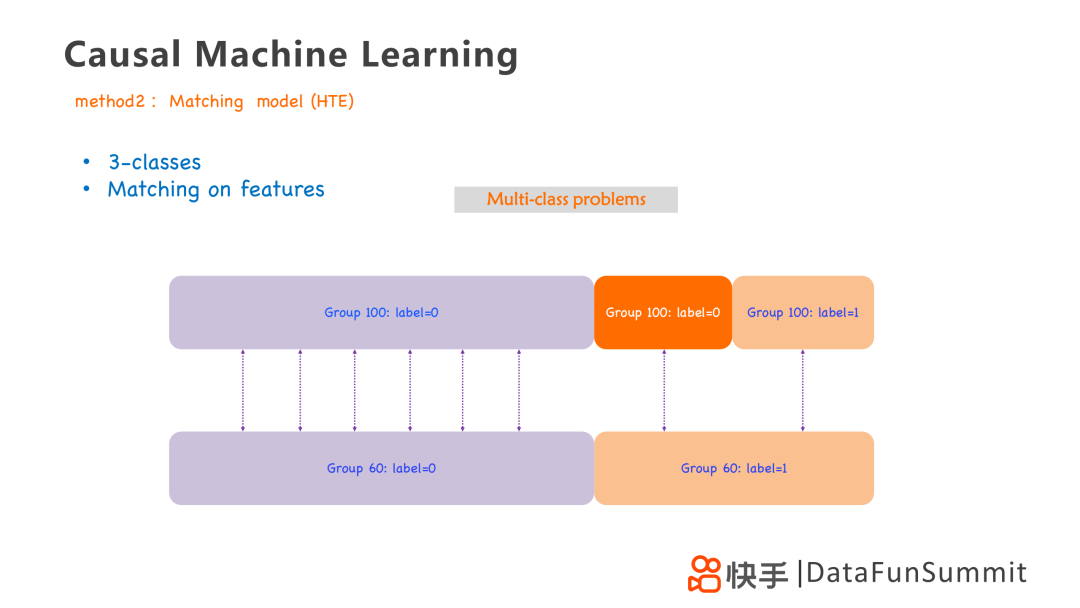
第二个方法是HTE匹配模型,它实际上是通过以两个策略为基础,贴上不同的标签,构造三组模型去构建模型,进行计算,主要分为以下三组:
第一组:Group 100,label=0 VS Group 60,label=0
第二组:Group 100,label=0 VS Group 60,label=1
第三组:Group 100,label=1 VS Group 60,label=1
这个模型的缺点在于计算过程中会有累积的误差,效果不是很稳定。但是利用这种方法,可以最大程度的简化目标,将最优化问题变成简单的三分类问题,得到更加简化的模型和明确的策略。

在做策略的时候,例如推荐,我们主要会遇到以下两个问题:
多组(无限)处理,我们无法训练太多的模型,如何简化我们的推荐treatment。
效果延迟问题,例如做留存策略时,关注用户点击ctr等即时反馈之外,如何制定更长远的指标策略。
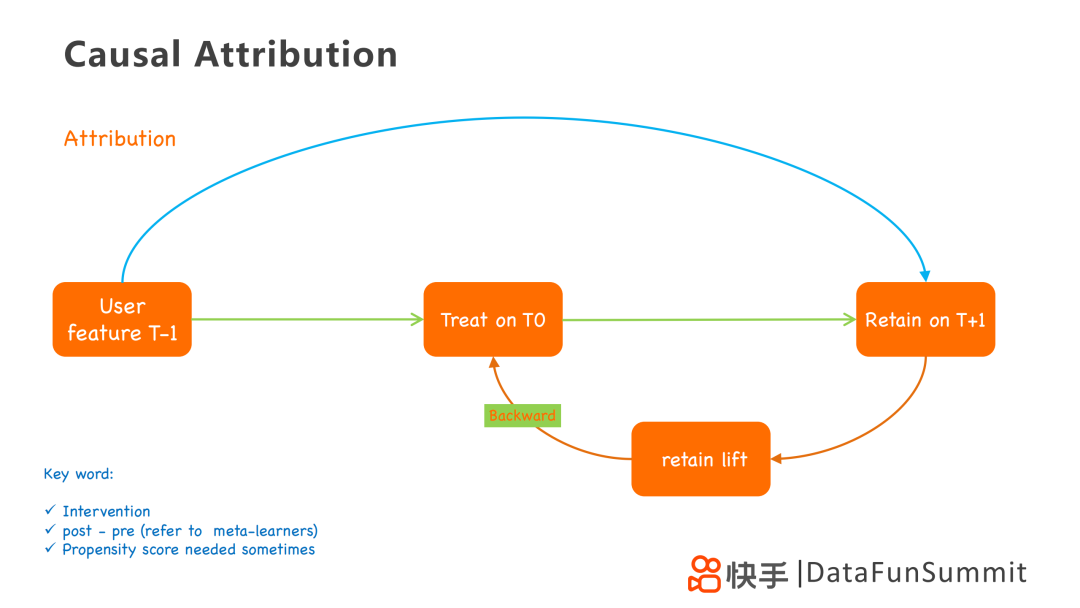
在这里我们再用这个框架图来讲解一下因果归因的思路,它用到了用户三个状态T-1,T0和T+1。T0状态即为用户受到无限处理的影响的状态。从T-1到T+1,是利用T-1状态的一些特征去预测T+1状态的留存情况,类似PSM倾向性得分。另一条路从T-1到T0再到T+1,是在经过treatment后,进行回溯。从T+1到T0,计算retain lift,这个lift可以认为是treatment带来的,然后采用backward或者credit assignment的方式归因到treatment上。
在因果分析里最主要的是解决去偏问题,在这个过程中我们解决了几个bias,在T0增加treatment时,高留存的用户未来留存也会高,因此会把用户留存的bias去掉,留下lift的留存。同时形成treatment时,也会只考虑当天用户的treatment带来的lift。但是在这个过程中treatment的数量很多,难以算出每个treatment对应的lift,可以采用平均处理计算。但是这个方法存在很大的误差,进一步可以采用权重,通过用户like或者follow的行为增加对应treatment的权重,提高归因的准确性。在有干预的情况下,去寻找干预带来的影响,可以通过post-pre去偏的方法实现。除此之外,想要映射无限多treatment到对应的lift,有时还需要采用propensity score,带有倾向得分计算,有助于帮助我们利用数学或matching的方法将bias消除掉。

最后总结一下因果分析,它源于一些传统科学例如社会科学、生物学等,如今在数据科学领域也有了很深的发展,也在公司广泛应用。它和机器学习、深度学习、推荐算法、强化学习和迁移学习是融合在一起的,其本质还是寻找有效的样本,解决更本质的问题。
Q1:因果分析的这套模型主要应用在整个推荐技术的哪个阶段?
A1:推荐系统主要经过召回→排序→重排阶段,在我个人的实际应用中,是将其应用到推荐的最后重排阶段,主要人类强干预增加的,进行一些结果的修正。常规情况,会将其应用到排序阶段,因果推断不是用于替代现有的资源系统,而是辅助现有系统,利用增加权重的方式进行改进,凸显出有效样本同时剔除无效样本。
Q2:在大量的item的情况下,会不会根据内容或者属性进行分类,减少归因的复杂度?
A2:会的,我们最希望解决的是每个item对于留存的贡献,但是这样做是很困难的,通过不同品类不同作者等属性分类,大致计算也可以获得一些相对粗略的结果,利用每个用户的policy推荐策略,将其从无限多treatment的问题变成多treatment的问题,使得这类问题可解。
Q3:中活和高活跃度用户比起新用户和低活用户,他们的treatment和用户行为数据是大量的,我们如何采用特征选择或者数据压缩等方法,将其应用到中活和高活跃度用户群体上?
A3:中活和高活跃度用户群体除了数据量上有区别以外,在收敛性质上也有区别。新用户的数据样本是具有一定随机性的,因为推荐系统还没有表现得特别好,相反高活用户在推荐数据表现上已经具有很强的倾向性。而因果推断就是要通过去偏,构造一个平均化的模型。因此根据因果推断的本质思想,可以将exposure bias或者偏好bias剔除,将其恢复到一个随机的分布,再用平均理论,反推其item的lift,理论上就可以实现。
Q4:如果在整个推荐系统中,增加一份1%的随机流量,会怎样利用这个随机流量去构建因果推断模型呢?
A4:随机流量本身不能去替代matching或者PSM的分析方法,它的作用是帮助我们更好理解用户本身的偏好。但拥有这个随机流量,在模型修复模块可以简单的归因到随机流量上。但是随机流量和非随机流量是共同作用在用户上的,会共同影响用户的留存,也得考虑随机和非随机的差异,通过matching或者反事实的理论实现去偏。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“因果推断” 就可以获取《因果推断专知资料合集》专知下载链接




