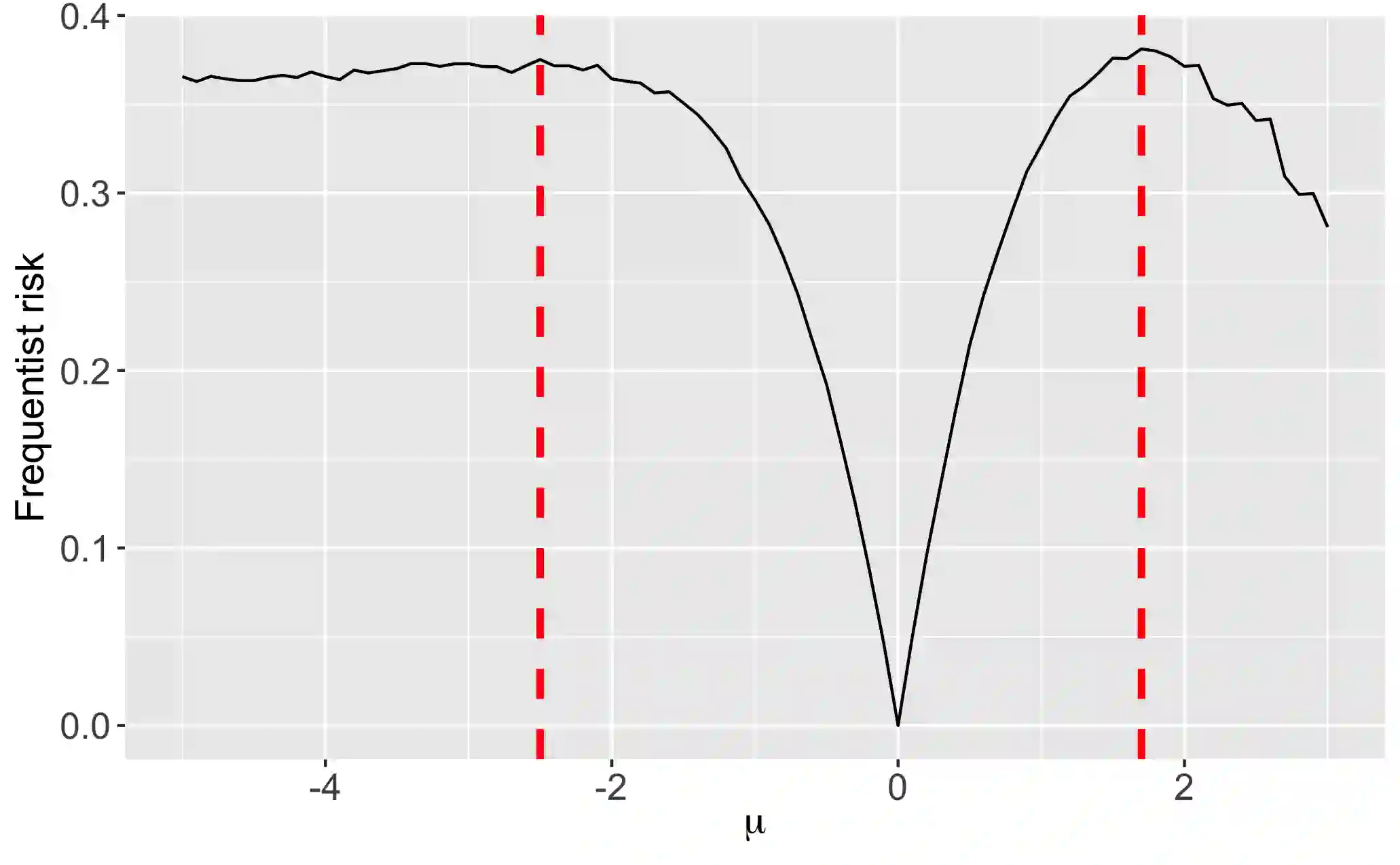
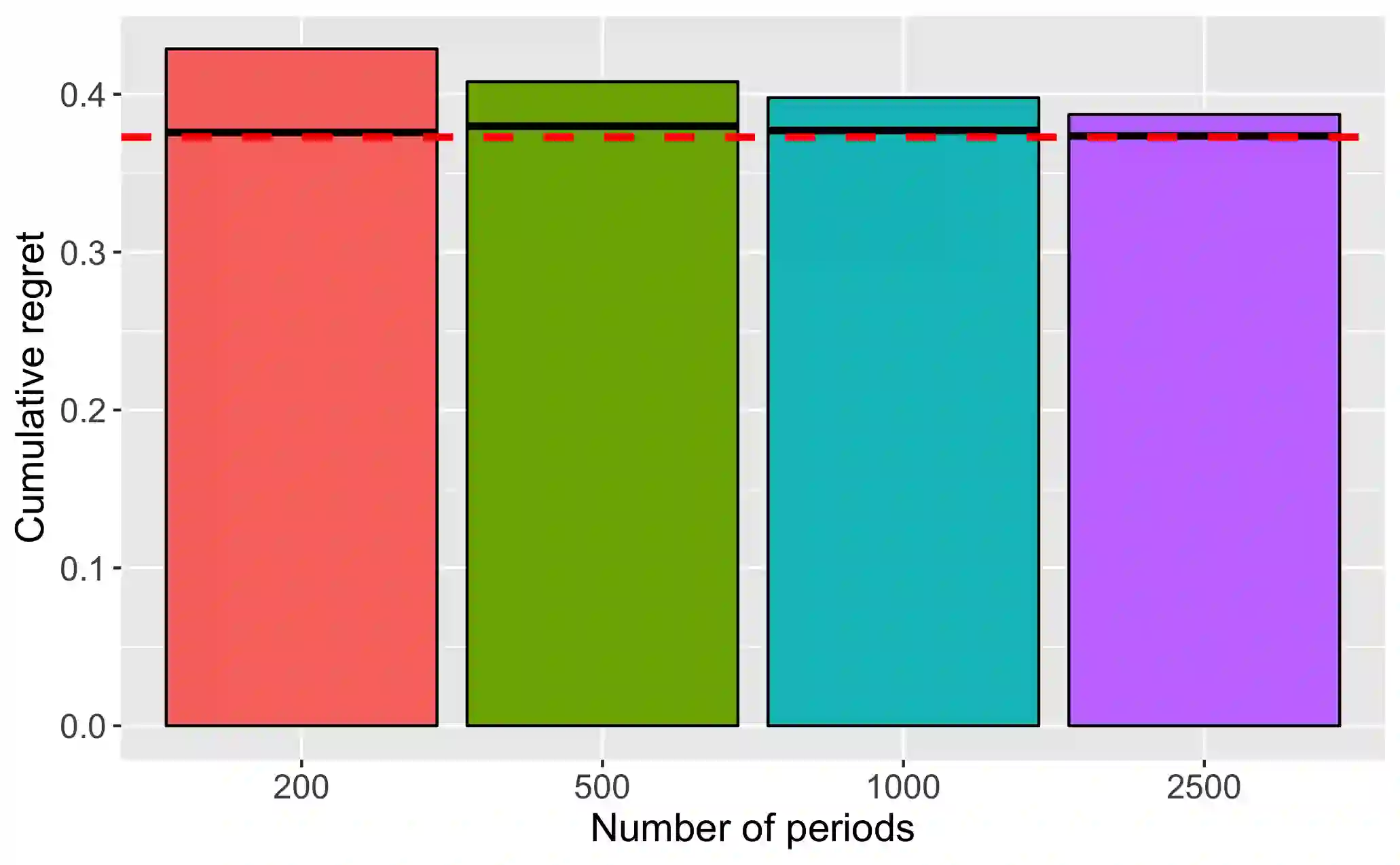
We provide a decision theoretic analysis of bandit experiments. The setting corresponds to a dynamic programming problem, but solving this directly is typically infeasible. Working within the framework of diffusion asymptotics, we define suitable notions of asymptotic Bayes and minimax risk for bandit experiments. For normally distributed rewards, the minimal Bayes risk can be characterized as the solution to a nonlinear second-order partial differential equation (PDE). Using a limit of experiments approach, we show that this PDE characterization also holds asymptotically under both parametric and non-parametric distribution of the rewards. The approach further describes the state variables it is asymptotically sufficient to restrict attention to, and therefore suggests a practical strategy for dimension reduction. The upshot is that we can approximate the dynamic programming problem defining the bandit experiment with a PDE which can be efficiently solved using sparse matrix routines. We derive the optimal Bayes and minimax policies from the numerical solutions to these equations. The proposed policies substantially dominate existing methods such as Thompson sampling. The framework also allows for substantial generalizations to the bandit problem such as time discounting and pure exploration motives.
翻译:我们为土匪实验提供了决策理论分析。 设置与动态编程问题相对应, 但直接解决这个问题通常不可行。 在扩散无症状的框架中, 我们定义了无症状贝亚和小鼠风险的合适概念。 对于通常分布的奖励, 最小贝亚风险可以被定性为非线性二级部分差异方程( PDE) 的解决方案。 我们使用一个实验限制方法, 显示这种PDE定性在参数性和非参数性奖赏分布下也处于静态状态。 这种方法进一步描述了它足以限制注意力的状态变量, 因此提出了减少规模的实用战略。 亮点是, 我们可以将动态的编程问题描述成PDE, 用稀薄的矩阵例行程序可以有效解决。 我们从这些等方程的数值解决方案中推导出最佳的巴亚和小型马克斯政策。 拟议的政策在很大程度上控制了诸如汤普森抽样等现有方法。 框架还允许对频度问题进行实质性的概括化, 如贴现和纯度等。