网易云音乐广告算法实践

分享嘉宾:蒋能学 网易云音乐
编辑整理:桑小晰 深交所
出品平台:DataFunTalk
导读:本次分享的主题为网易云音乐广告算法实践,内容围绕以下五个部分:
网易云音乐广告系统简介
广告点击率预估模型
广告转化率预估模型
用户向量建模与应用
总结与建议
1. 网易云音乐广告特点
MAU(月活跃用户人数)过亿
广告位分散,数据量适中
广告推荐属于弱推荐
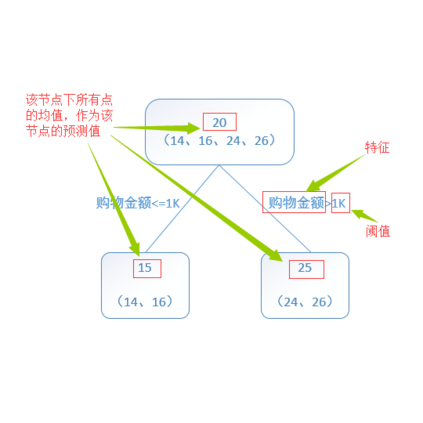
2. 广告系统要解决的核心问题 – 解决广告主与媒体方的博弈
注:ROI - 投资回报率;eCPM - 每一千次展示广告可以获得的广告收入;pCTR - 预测广告点利率;Price - 每次点击收费价格。
对于广告主来说,他们希望广告能够精准投放目标客户,并且使自己的广告成本尽可能的降低,从而最大化投资回报率。而对于媒体方,他们希望提高用户对广告的点击率,希望广告主之间有竞争(引入拍卖机制),以达到收入最大化的目的。
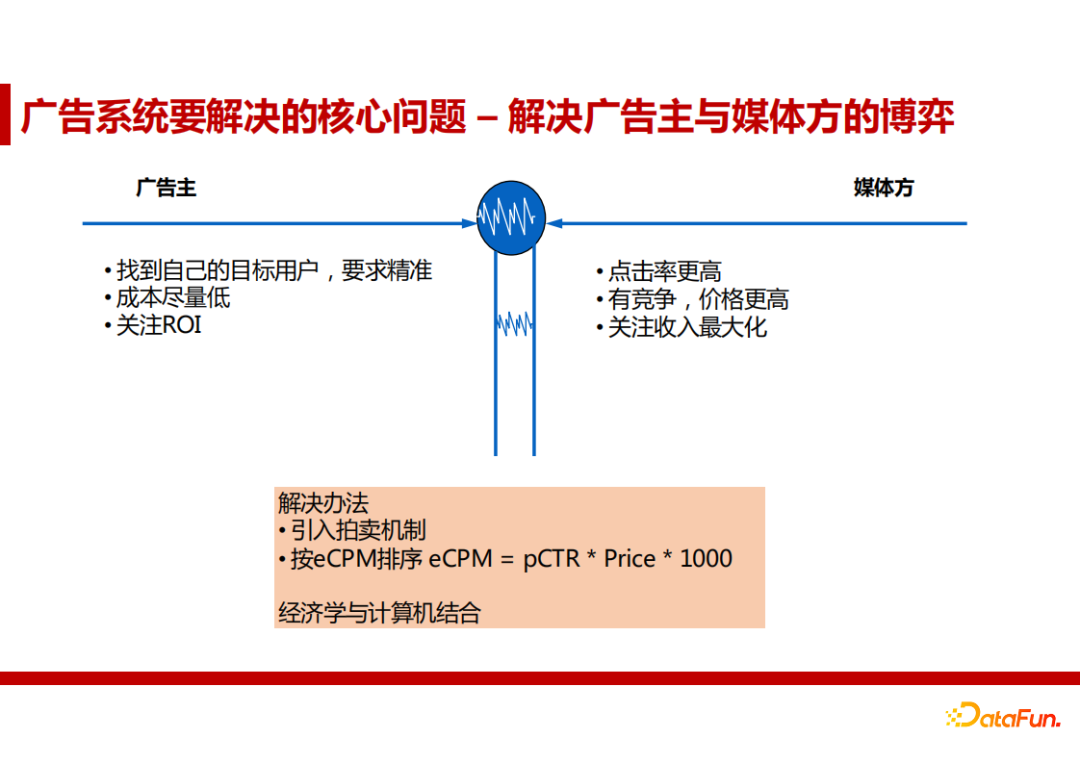
3. GFP vs GSP
GFP(广义第一价格拍卖)的主要特点是明拍,广告主之间互相知道价格。
GSP(广义第二价格拍卖)是目前互联网广告系统最常用的拍卖模式。
4. 经济学+机器学习,平衡博弈双方的利益

CTR预估的一个解决方案: 利用机器学习来预测点击概率。
精准投放的特点保障了广告主的ROI。
拍卖机制保障了媒体方流量价值的最大化。
CTR预估扮演着非常关键的桥梁作用。
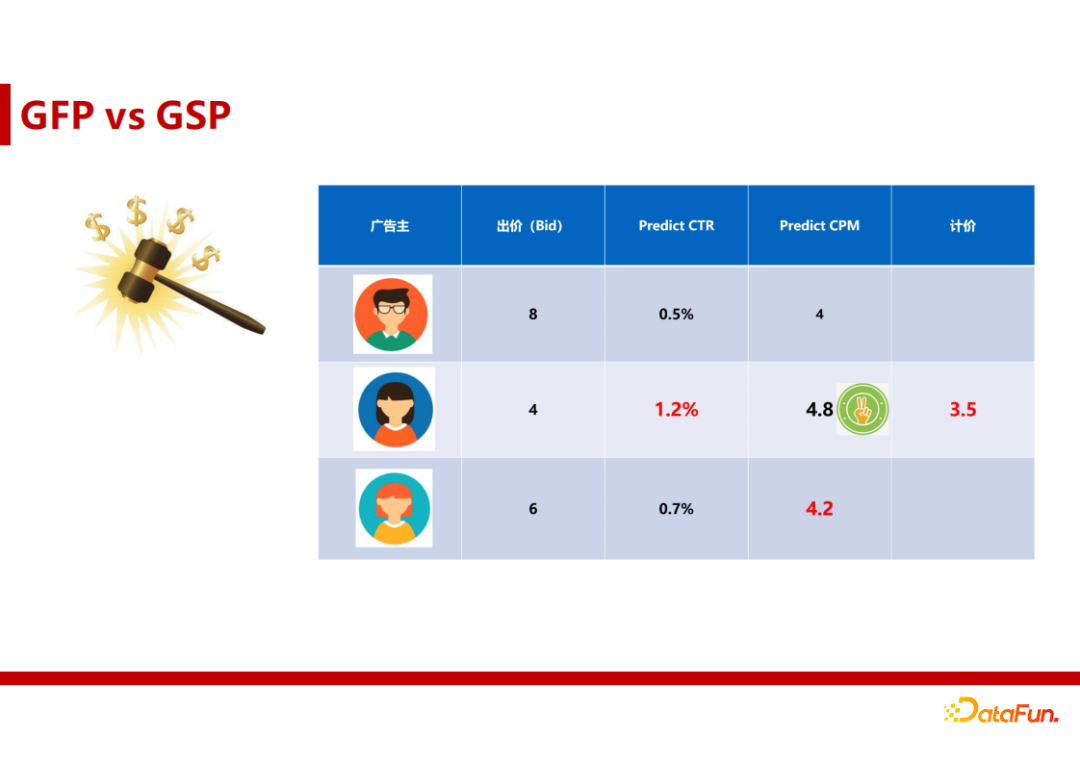
1. CTR预估要解决的问题
点击率预估和如何出价是计算广告中非常重要的两块工作。
广告主 - 广告平台的CTR预估模块根据用户特征、广告特征和环境特征等,计算出广告库中符合广告主定向条件的所有广告的点击概率,以最大化ROI。
媒体方 – CTR预估模块用于选择广告计价方式,以达到收入最大化。
2. CTR预估的基本原理
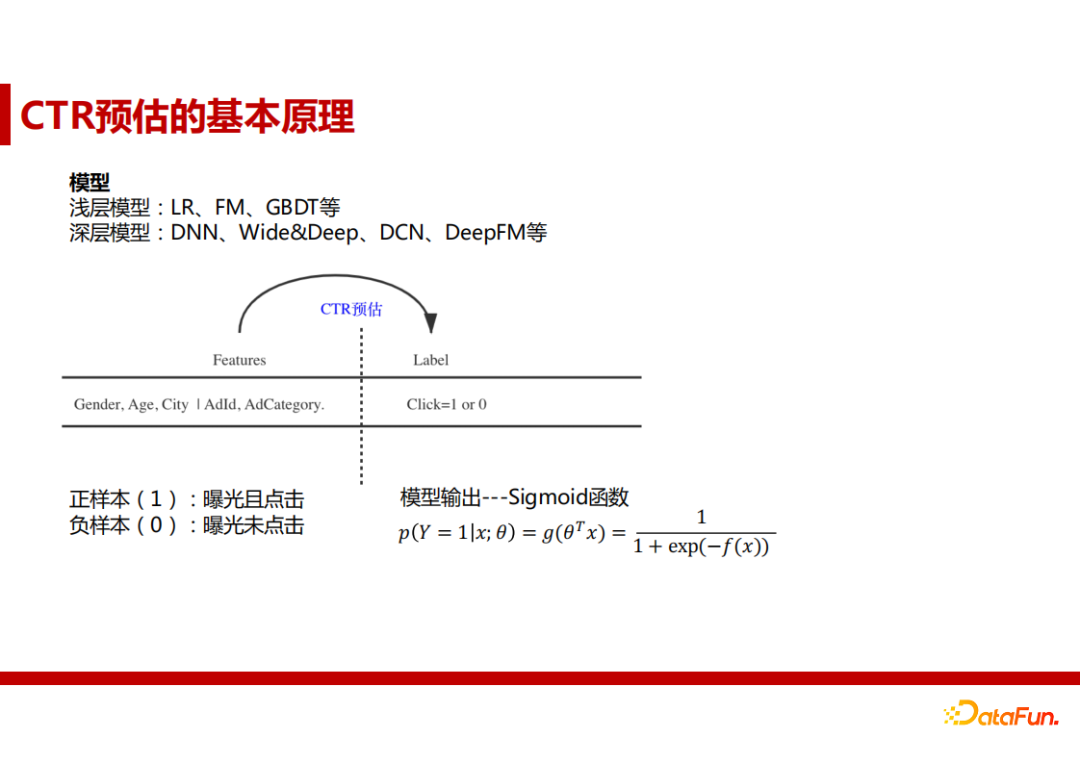
我们根据历史投放记录来收集数据样本,对于之前被投放过广告并且点击的用户视为正样本,投放过广告但未被点击的视为负样本。输出通过使用Sigmoid函数来得到点击概率。
早期约09年期间用于CTR预估的主要是LR模型,后来常用FM和GBDT模型以及它们的变体。神经网络出现之后,DNN、Wide&Deep、DCN、DeepFM等深层模型逐渐代替了浅层模型的使用。
3. 云音乐广告系统浅层模型演进和优化
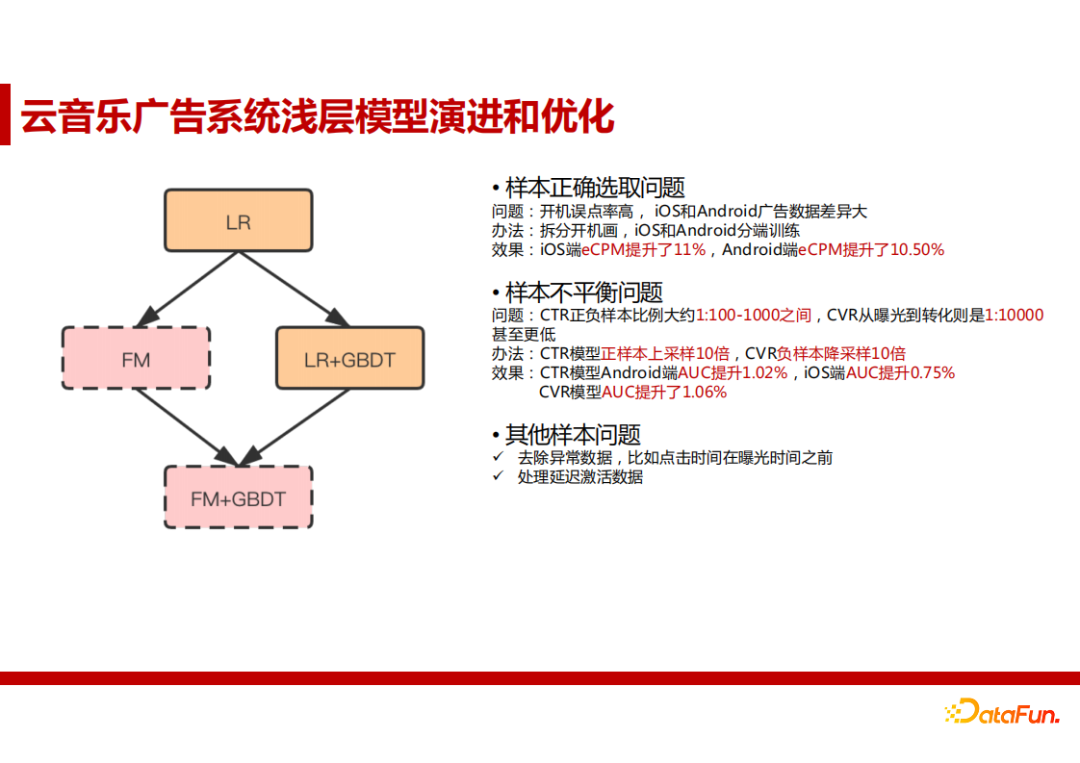
① 浅层模型优化空间小, 早期主要是对数据样本进行优化,涉及以下几个方面:
样本正确选取问题:早期为了简化,iOS端和Android端的数据是一起训练的。后来把这两个分开了,因为IOS和Android的用户群体是不太一样的,很少有一个用户同时用两款手机。此外,有些广告位置误点率也比较高。这些都会对CTR的预测效果有影响。拆分后,数据分布的一致性提升,在两端训练后的效果也都提升了超过10%。
样本不平衡问题:CTR高低的样本区域分布不平衡,这也会对训练和预测有一定影响。解决方法是对CTR模型正样本上采样10倍,对CVR(转化率)模型负样本降采样10倍。处理后AUC指标大约提升了1%。
② 特征组合与模型进化尝试 - FM
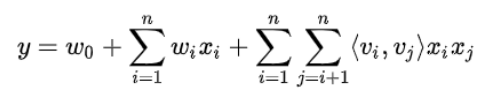
早期使用LR模型时,由于样本数量有限,特征稀疏,并不能很好的捕捉组合特征和学习出用户侧和广告侧的匹配关系。后来采取FM模型为每一个特征学习一个隐权重向量,泛化之前没有出现过的特征组合,解决了稀疏特征组合的问题。FM模型的线下AUC提升了0.75%,但线上效果不够稳定,不符合全流量标准。推测原因是模型深度不够,非线性表达能力不足,从而对连续特征的处理不好,以及在弱个性化推荐场景,二阶特征组合的记忆力也不算太好。
③ 特征组合与模型进化尝试 – GBDT

为了解决上述FM模型遇到的问题,我们尝试使用了GBDT模型对特征做深层交叉,增强数据的有效性,提供更好的记忆能力。结果显示LR+GBDT模型相比基线LR模型的AUC指标提升1.71%,效果非常显著。线上CTR和eCPM提升稳定,符合全流量标准。推测这是因为是弱个性化场景下需要有深度记忆功能。LR处理好了模型对稀疏特征的记忆能力,GBDT处理好了深度组合特征以及连续特征的记忆能力,这正好符合网易云音乐音频流量的广告场景。并且,这个思路会持续到深度学习阶段。
4. 云音乐广告系统深度模型演进和优化
前面提到LR处理了稀疏特征记忆能力,GBDT处理好了深度组合特征以及连续特征的记忆能力。但如何才能进一步提升效果? 深度模型提供了更大的灵活性,比如引入泛化能力,以及更灵活的深度特征组合。因此,为了延续LR+GBDT的优化思路,我们引入了深度模型。
(1) DNN与LR的对比
① DNN相比LR的优势
DNN的非线性表达能力更强
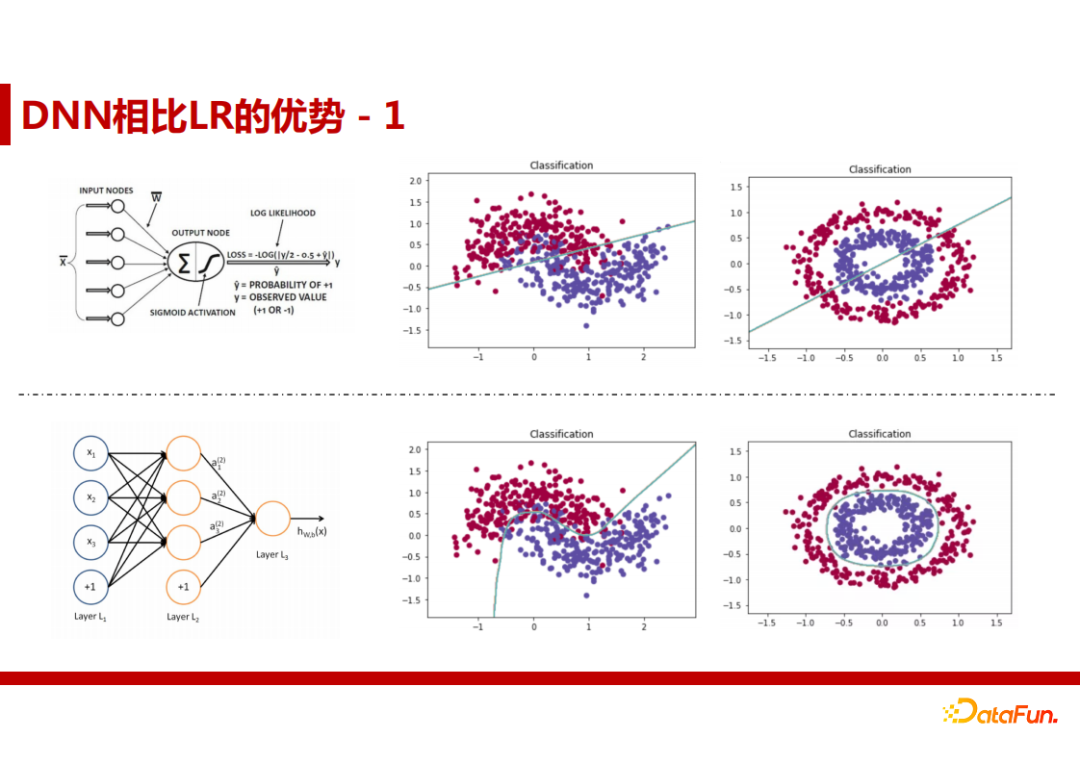
可以看出,即使对于环形数据,DNN也能够通过特征工程很好的表达。
DNN能够实现自动高阶特征组合

LR模型对于这种数据情况,没有特征组合是学不出来的,在增加了一个特征组合“性别x游戏类型”后,模型才学到了有用的信息。
泛化能力
DNN能够将高维稀疏特征编码降为低维稠密Embedding向量,使模型具备泛化能力,并且对于从来没出现过的特征组合也能通过共享特征向量分别从单个特征中学到有用的信息,类似于FM的隐向量,能有效提升模型的泛化能力。
② DNN相比LR的不足
长尾特征学习不充分
在线广告场景的数据特征非常稀疏,并且长尾特征非常多,由于出现次数太少,这些特征的Embedding向量无法得到充分的学习,从而导致预测不准确。相比之下,LR模型对于高频共现的特征组合具有良好的记忆能力,这种能力在广告场景下非常有用。
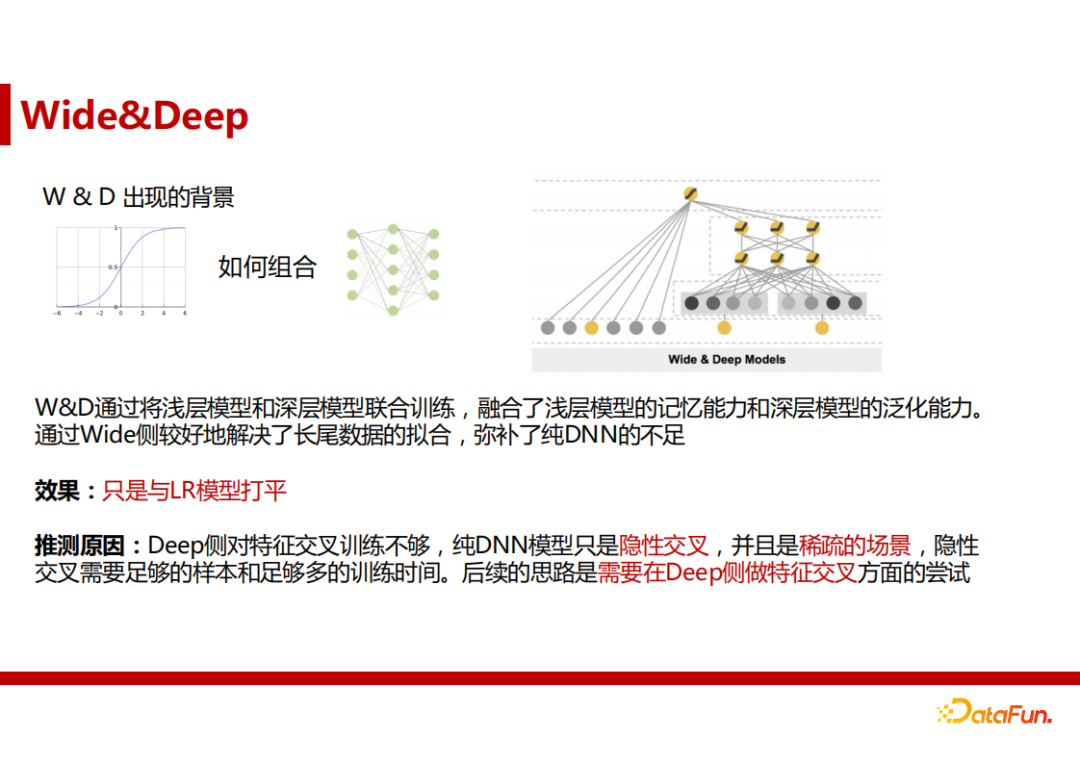
因此,将LR的记忆力和DNN的泛化力进行联合成为了一个研究方向,Wide&Deep模型的提出是解决这个问题的方案。Wide&Deep通过将浅层模型和深层模型联合训练,融合了浅层模型的记忆能力和深层模型的泛化能力。通过Wide侧较好地解决了长尾数据的拟合,弥补了纯DNN的不足。然而,Wide&Deep模型的效果并不显著。推测是因为Deep侧对特征交叉训练不够,纯DNN模型只是隐性交叉,并且是稀疏的场景,隐性交叉需要足够的样本和足够多的训练时间。后续的思路是需要在Deep侧做特征交叉方面的尝试。
PureDNN在实际应用中特征组合能力有限
虽然理论上只要MLP的层次足够深,算力足够强,样本数量足够且准确,DNN就能拟合出任意函数。但在实际中,样本数量和运算能力等都是有限的。改进办法是改变Pure DNN的网络结构,改变特征交叉。不要让模型自己去学习,需要添加一些假设,使得模型更有效的学习特征组合。
(2) DCN
为了解决纯DNN没有特征显式交叉的问题,我们引入了DCN模型。它在Wide&Deep的基础上,把Wide侧改成了Cross Network :

DCN模型的离线AUC比LR+GBDT高0.69%, 线上eCPM提升幅度稳定达到3%,达到了上线标准。
(3) DCN + Wide + Attention
DCN已经解决了头部数据的特征深度交叉,以及泛化的功能。但其长尾数据问题仍旧存在,因此我们自然的加入了Wide侧,通过优化效果陆续得到了提升。此外,他们还加入了Attention机制(DIN),解决了用户的短期兴趣问题。
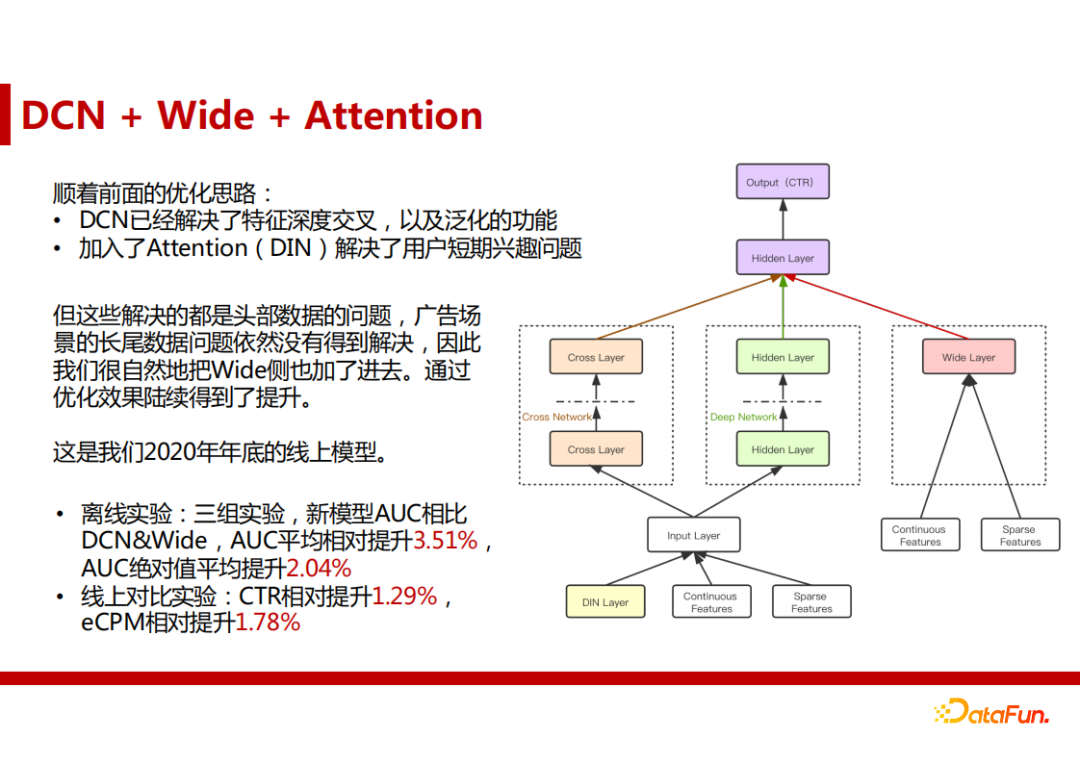
此模型为网易云音乐广告系统2020年年底的线上模型。它的离线AUC相比 DCN&Wide平均提升3.51%,离线AUC绝对值平均提升2.04%。线上CTR相对提升1.29%,eCPM相对提升1.78%。
(4) 深度模型优化点
激活函数优化
在优化DeepFM的过程中,发现Deep侧不起作用,进一步发现隐藏层的很多输出为0。这是因为激活函数ReLU的单侧抑制能力在训练过程中导致大量神经元不可逆死亡,进而使大量参数无法更新,导致训练过程失败。

后来我们把激活函数换成了PReLU,解决了神经元死亡的问题,AUC提升了0.5%。
递减学习率和Batch size的优化
递减学习率 - 太高的学习率会导致不收敛或者震荡,太低的学习率则收敛速度太慢。递降的学习率一开始比较大可以让模型快速收敛,后面逐步减少则可以精确收敛。这里使用了Adam优化器,学习率初始值设置为 a,之后每n步降低0.96,AUC提升了0.2%。
Batch size - 设置为10000,以确保每个batch里有一定数量的正样本。
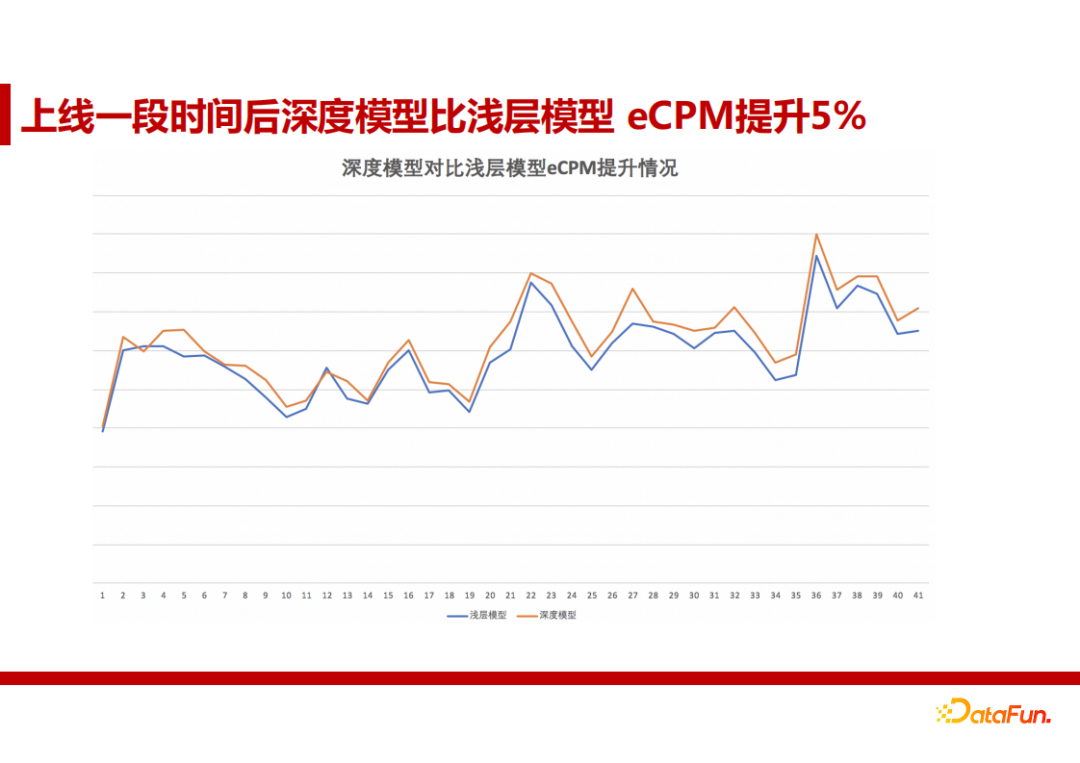
优化效果如下图所示:
1. 广告主与媒体再次博弈 - 更低的成本 vs 更多的收入
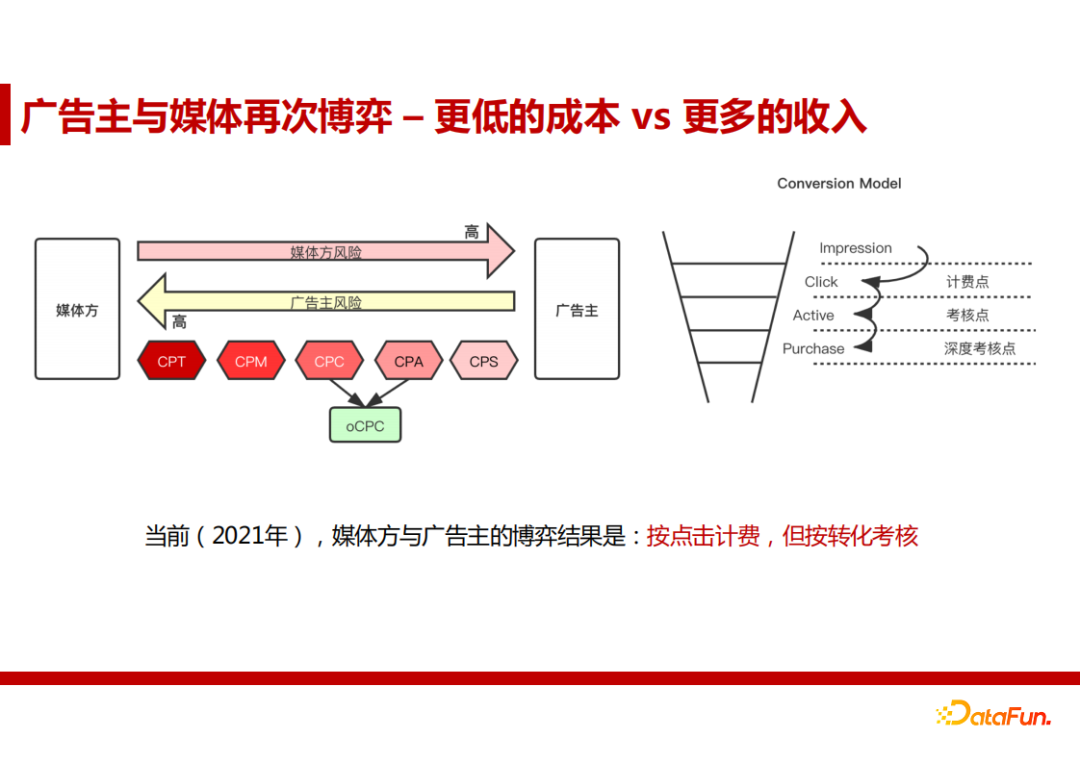
注:CPT - 按时长来计费的广告;CPM - 按照曝光展示计费;CPC - 按照点击量计费;CPA - 按照有效回应行为计费;CPS - 按照最后成交计费。
2007年以来,广告主和媒体方就主要围绕着CPC和CPA进行博弈。当前(2021年),媒体方与广告主的博弈结果是按点击计费,但按转化考核。目前出现了oCPC这种折中的方案。oCPC和CPC的结算方式是一样的,都是按点击计费,不同的是oCPC是平台通过估算广告的CTR、CVR,帮助广告主合理出价(点击计费的价格)。
2. 解决方案: 采用多目标优化来达到平衡
核心思想:竞价时,给转化率高的用户出高价,转化率低的用户出低价 (oCPC)。
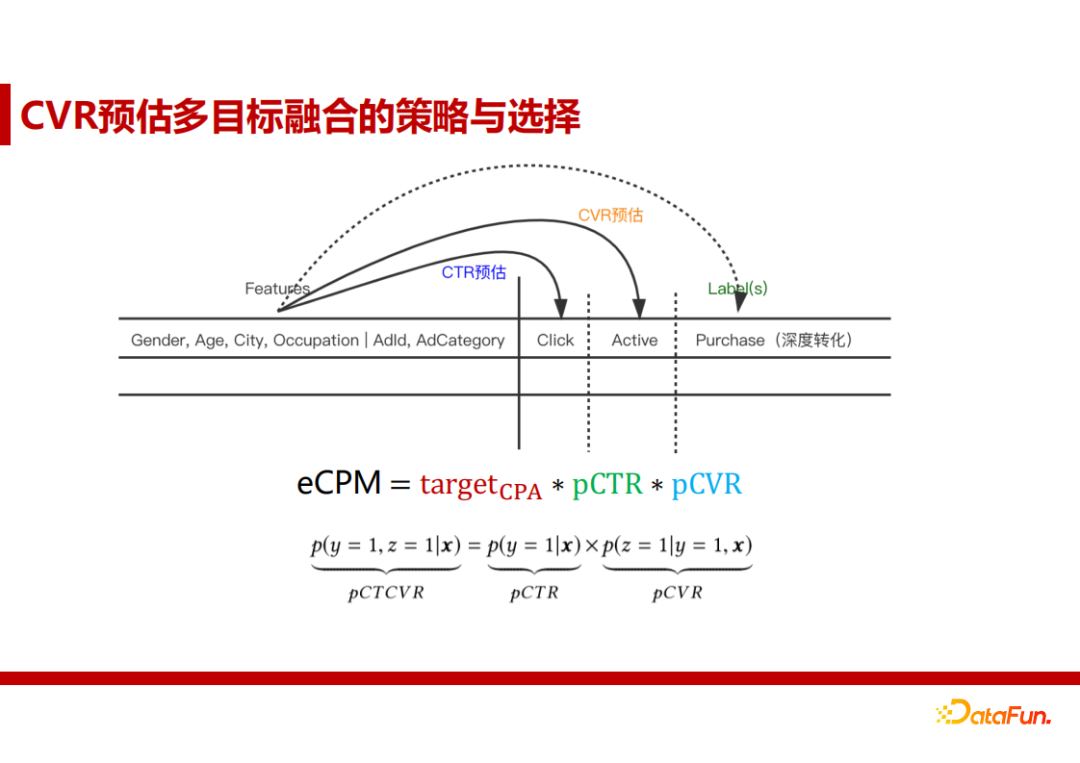
targetCPA是由广告主控制的。例如,广告主根据能够接受的价格范围决定每一个转化收费多少。pCTR和pCVR则是由模型进行预测和评估得来。
3. CVR预估多目标融合的策略与选择 - 统一建模还是分开
早期CTR和CVR是分开训练的,一个是由曝光预估点击率,另一个是由点击率预估转化率。分开训练会导致样本选择有偏差,即训练时使用点击样本,线上预测则是使用曝光样本。
4. CVR模型成败的关键: 调控和校准因子
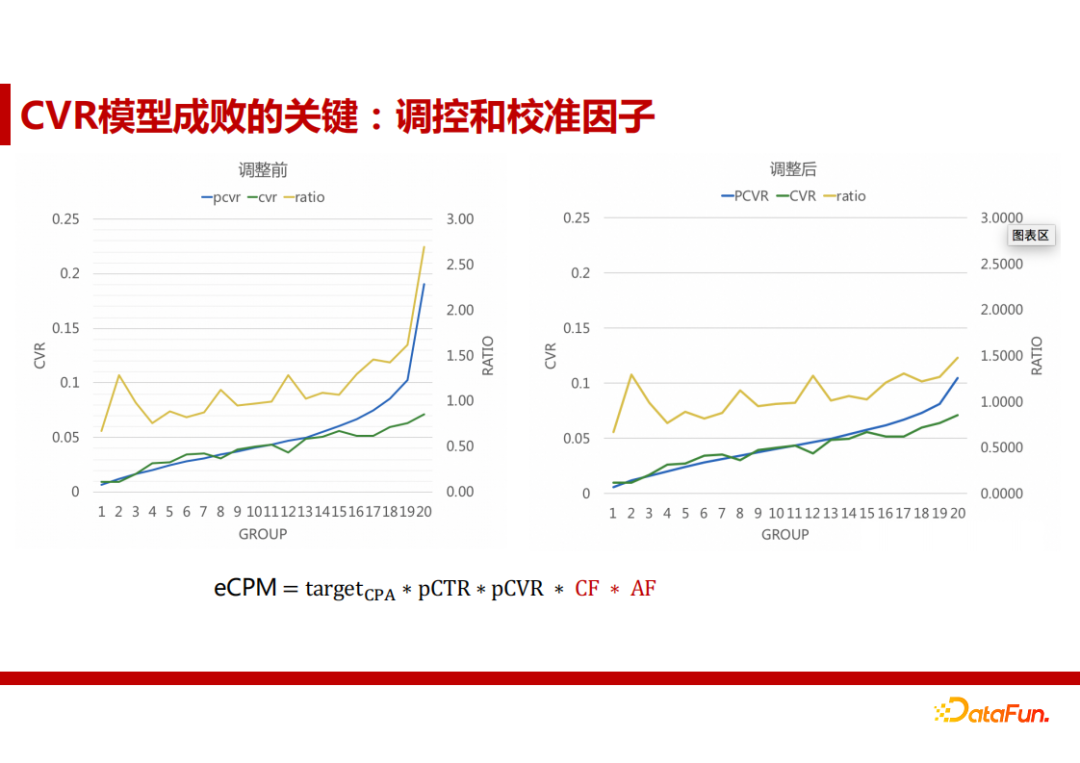
我们使用了一个经验公式来做校准。我们首先按照PCVR从小到大做了20个分桶,这样每个桶就是就一个集合,就能够把PCVR和CVR统计出来了。
问题:面向新广告投放冷启动。即因为新广告、新广告主无历史投放记录,会导致CTR/CVR模型缺少新广告的特征和样本,很难准确预估。
解决方法:使用Lookalike扩展相似人群。
1. Lookalike怎么扩展相似人群
① 找出种子用户:种子用户一般是指广告主的历史转化人群,例如产生过APP下载、商品购买、表单提交等转化行为的用户群体。
② 扩展方法:基于广告主提供的种子用户,通过一定的算法模型,找到更多拥有潜在关联性的相似人群。
人工选标签
二分类法(早期使用):将种子人群作为正样本,将与种子人群无交叉的人群作为负样本进行训练。多次迭代,直到获得达到要求数量的种子人群。这种方法的问题在于针对不同广告主都需要做一次二分类训练,资源浪费。
基于聚类
基于协同过滤
基于社交关系
向量计算(近期使用):计算种子用户的向量表示与候选用户的相似度,基于相似度打分来召回相似用户。优点是用户向量可通用,能服务于所有广告主。难点在于如何有效地学习用户的向量表示(通常基于双塔模型)。
2. DSSM双塔点击率模型
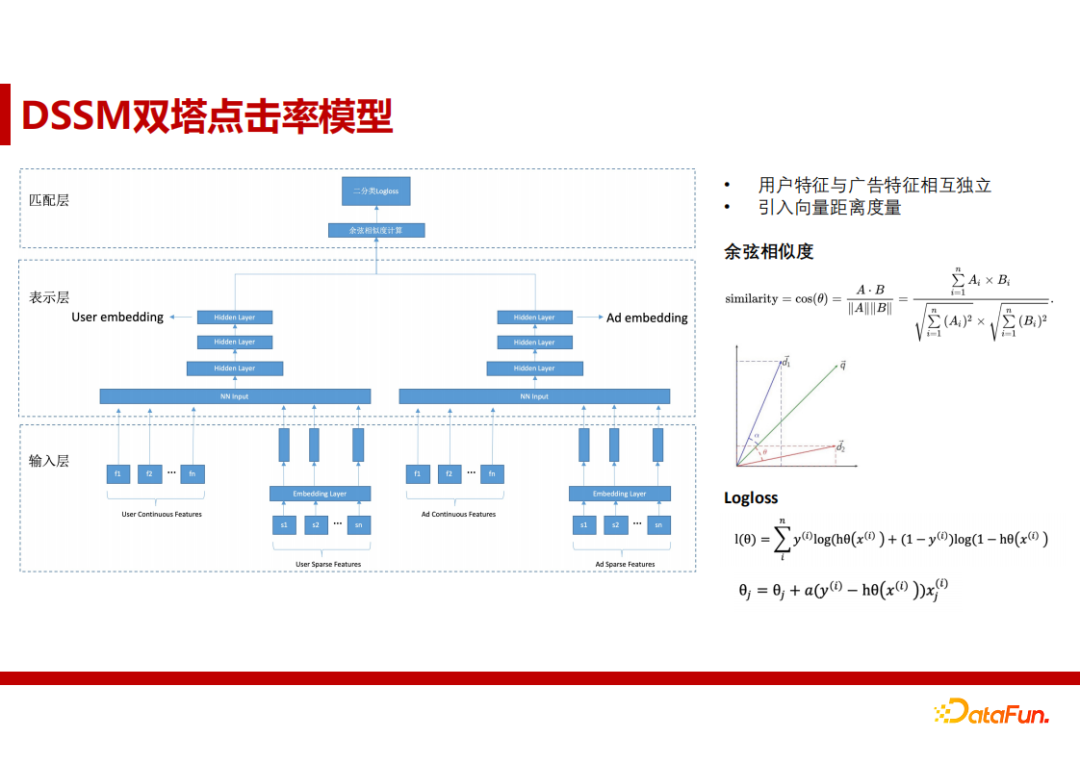
双塔模型中,用户侧特征与广告侧特征在输入时相互独立,并且引入向量距离度量。训练后,对于有过点击行为的数据,我们视为正样本,认为两种特征的空间距离较近。没有点击的为负样本,空间距离远,余弦相似度低。
3. 如何获得用户向量
获得用户向量:首先输入用户侧特征;然后进行模型预测,用户侧DNN的最后一个隐层输出即为用户向量embedding。
为什么使用双塔模型,而不使用传统CTR模型? 因为生成用户向量时只能使用用户侧特征,因此模型中用户侧与广告侧不能进行特征交叉。双塔模型最后一层中使用余弦相似度距离度量,使得用户向量拥有距离信息,并且处于同一空间。
以下是几个需要注意的点:
-
由于样本正负比例过大,需要对负样本进行采样,我们保持正负样本1:7,否则将会影响收敛。 -
采用Adagrad优化器,可以随着训练的进行逐步减小学习率。 -
采用dropout和L2正则项减少过拟合。
4. 如何衡量候选用户与种子人群的相似度
种子用户的数量通常上万,直接计算时间复杂度过高,且效果不好。解决措施:
① 对种子人群向量聚类
对种子人群进行聚类,形成K个向量聚类中心表示种子人群,以减少种子数量。
② 对K个聚类簇的重要程度进行衡量
方法是增加种子人群每个聚类簇的历史统计CTR作为权重(提升效果显著)。
③ 对候选用户与种子人群的相似度打分
首先,计算候选用户与K个聚类中心的向量余弦相似度;
之后,使用K个聚类簇的权重对相似度进行加权;
最后,选择候选用户与K个聚类中心的加权相似度的最大值作为候选用户与种子人群的相似度得分。
1. 个人理论总结 - 人类行为可预测的认知
人类行为有93%是可预测的,我认为这一基本原则是很多优化工作的指导基础。
个体人格相对稳定,可以根据其历史行为预测未来。
人类具有共同的行为模式,可以用群体行为预测个体。
做算法上的优化,应该要遵循这两个基本原则。
2. 建议
围绕业务 – 关注业界,但要针对自己的业务和数据特点做优化和创新。
抓住本源 – 数据要能真实反应用户意图。
多交流 – 多与同行沟通交流,拓展自己的视野。
Q:针对新广告投放冷启动的经验有哪些?
A:利用广告主提供的种子人群包,使用LookLike扩展相似人群;给新广告一定数量的曝光,观察数据表现;对新广告的行业进行分类,使用相同行业中其他广告的数据。
Q:使用聚类方法降低候选用户与种子人群的相似度计算中,使用历史统计CTR作为权重是如何提升候选用户的识别准确率的?
A:假设A,B两个地点均有很多程序员,C地点是两者的距离中心,但是几乎没有程序员,D比较接近地点A或者B的其中一个,我们认为程序员浓度相对C高。此时,我们需要识别程序员密度高的地区,使用距离平均中心C显然不符合实际要求。我们更倾向于把地点D整个群体的属性作为一个候选群体,以此来提高相似度计算的准确率。在找出候选用户的问题上,地点D的情况就类似于历史CTR高的用户群体。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“计算广告” 就可以获取《计算广告专知资料合集》专知下载链接

请扫码加入专知人工智能群(长按二维码),或者加专知小助手微信(zhuanzhi02),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG、论文等)交流~