Embedding技术在商业搜索与推荐场景的实践
分享嘉宾:苏永浩
作者单位:58同城资深算法工程师
出品平台:DataFunTalk
导读:从C端视角来看,58商业将Embedding作为广告的一种理解方式,使我们精确理解C端用户意图,同时理解B端推广提供的能力,使得目标推广以合适的形式触达C端用户。Embedding对文本语义、用户行为进行向量化,通过数学计算表达广告和用户关系,具备易表示、易运算和易推广的特点。今天将从以下几方面来介绍Embedding技术在58商业搜索和推荐场景的实践:
58商业流量场景
主流Embedding算法介绍
Embedding在58商业搜索实践
Embedding在58商业推荐实践
首先和大家分享下58商业流量场景。
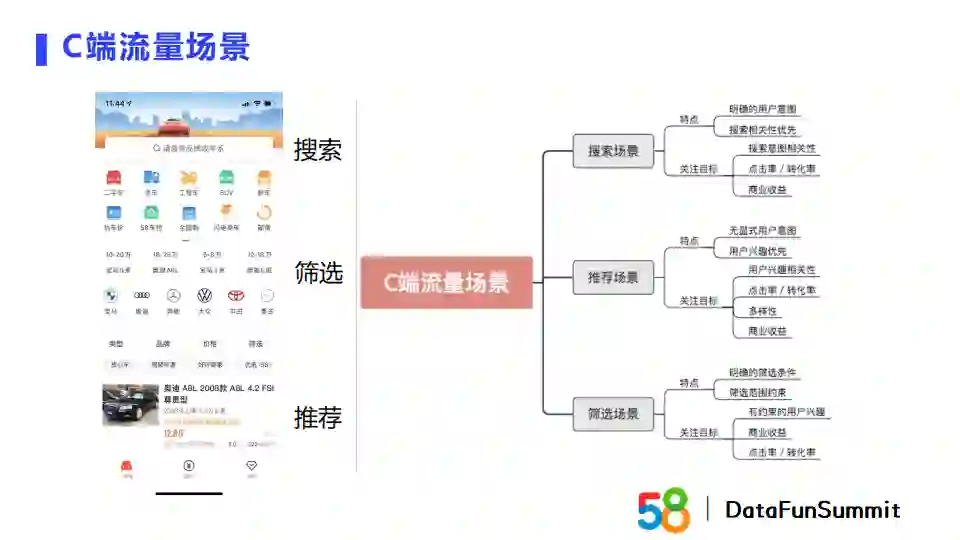
从C端的视角来看,58商业流量包括搜索、筛选和推荐。
搜索场景的特点是有明确的用户意图,主要通过搜索的query来表示。我们在搜索场景下需要优先保证搜索的相关性,其次是点击率、转化率以及商业收益。
推荐场景没有显示的用户意图,即用户的真实意图是一个隐式表示,需要通过用户的历史行为,包括点击、购买、微聊等行为序列中获取。在此场景下,我们主要的目标是优先保障用户兴趣,关注的目标是用户的兴趣相关性,其次是点击率和转化率、多样性以及商业收益。多样性的目标是避免相似帖子聚集。
筛选场景的特点是具有明确的筛选约束条件。在这一场景下,我们需要关注的目标是在有约束的情况下用户的兴趣,同时关注点击率、转化率以及商业收益。
Embedding相当于对one-hot做了平滑,而one-hot相当于对embedding做了max-pooling。
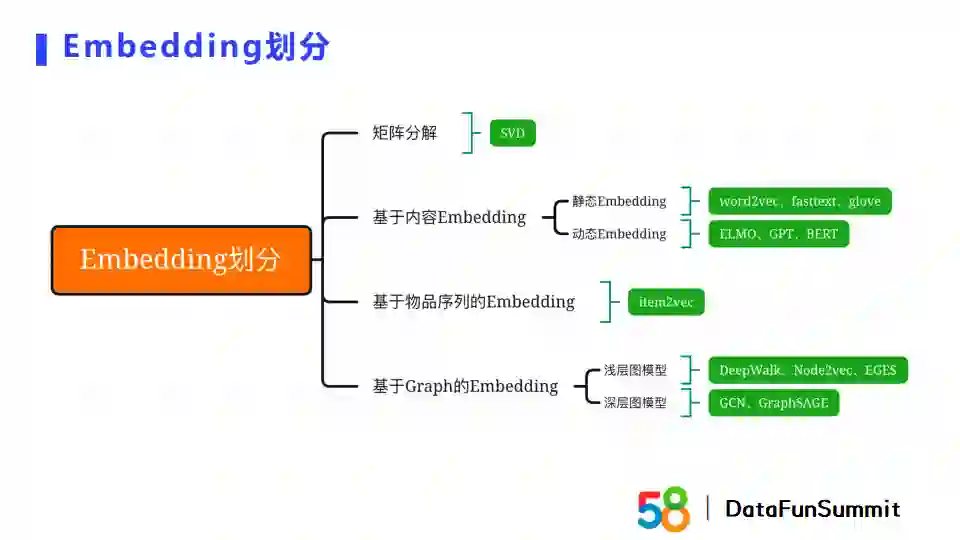
Embedding可以被划分为四类:
第一种是基于矩阵分解的方式,其中的代表方法是SVD;
第二种是基于内容的Embedding,它包含如word2vec、fasttext等静态Embedding和如ELMo、GPT、BERT等动态Embedding;
第三种是基于物品序列的Embedding,代表方法是item2vec;
最后一类是基于图的Embedding,分为浅层图模型和深层图模型。浅层图模型有deepwalk、Node2vec、EGES,深层图模型有GCN、GraphSAGE等。
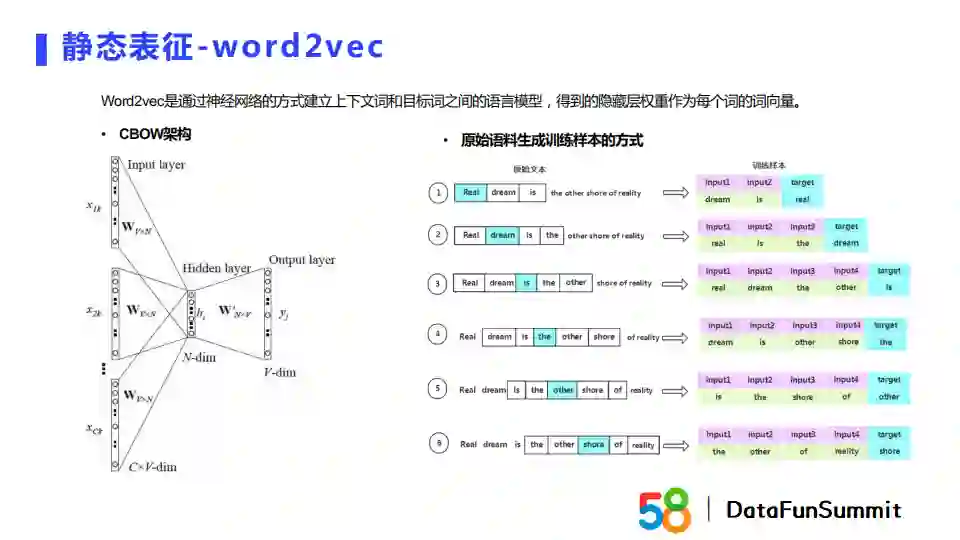
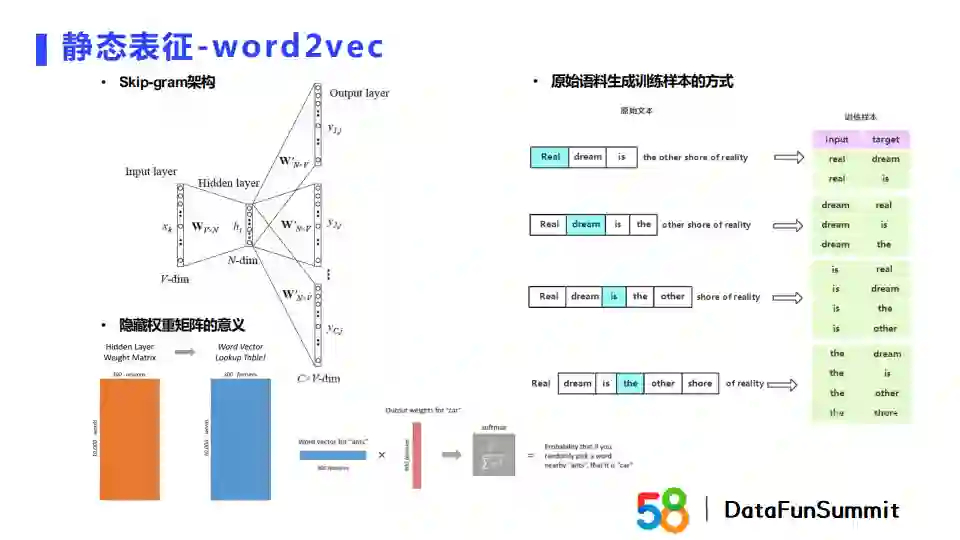
首先来介绍一下静态表征。从名字我们就可以看出,静态表征方法主要是对一个词生成Embedding,且它在生成之后是固定的。这类方法的优势是我们可以提前确定词向量,在后面线上使用的时候就相当于“查字典”的操作,比较方便。它的劣势也很明显,针对一词多义的情况,静态表征无法解决。
静态表征方法中具有代表性的模型是word2vec,它通过神经网络建立上下文和目标词的语言模型,得到的隐藏层权重可以用来表示每个词的词向量。Word2vec有两个架构:CBOW和Skip-gram。CBOW的输入是中心词的上下文词,输出是中心词。它的训练样本可以通过滑动窗口进行建立。Skip-gram是将中心词作为输入,输出是中心词的上下文。由于每个词是通过one-hot的方式进行表征,one-hot值和隐藏层的权重相乘就可以得到词的唯一Embedding表示。通过这一方法,我们可以用得到的Embedding来作为中心词的向量表征。
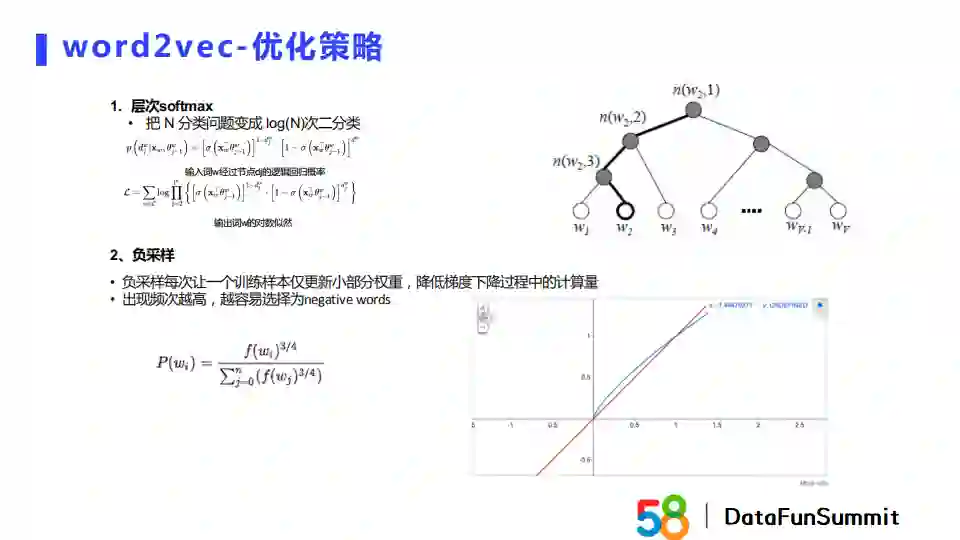
word2vec的优化策略有两种。第一个是层次softmax,第二个是负采样。层次softmax根据词频建立一棵二叉树,把N分类问题变成了logN次二分类问题。负采样每次让一个训练样本更新网络中一小部分权重来降低整个梯度下降过程的计算量。
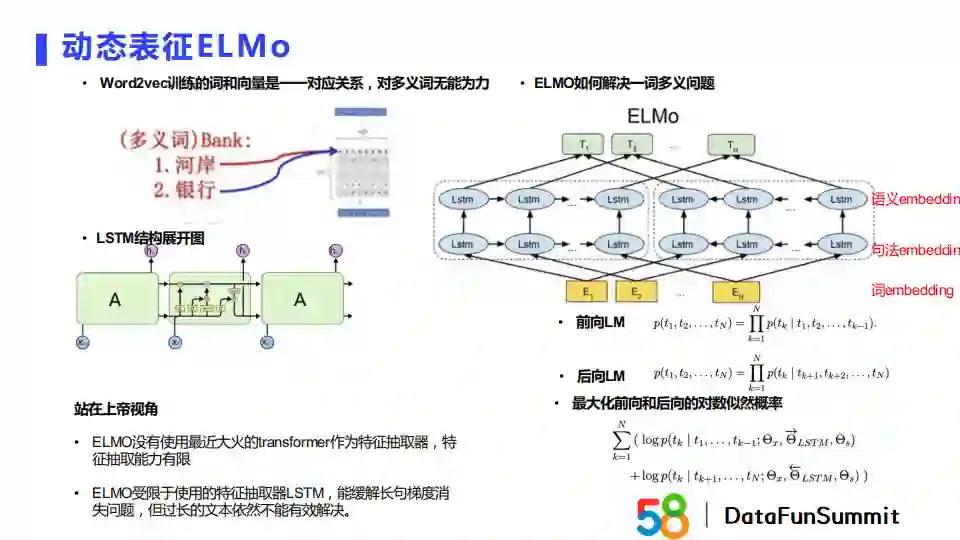
之前提到静态表征对一词多义无能为力。例如“bank”这个词,它即可以表示河岸又可以表示银行,但它在静态表征训练的词向量表中对应了唯一的Embedding。动态表征代表模型之一是ELMo。ELMo可以看作一个前向语言模型和后向语言模型的拼接,它的目标是最大化前向和后向的对数似然概率。由于采用LSTM作为特征抽取器,相较于现在流行的Transformer特征提取器,它的特征抽取能力有限。
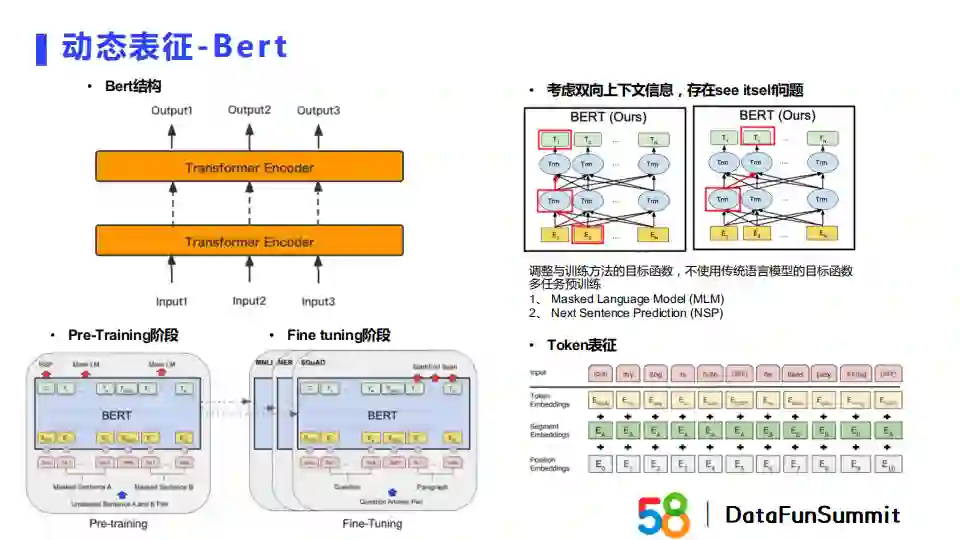
Bert可以被理解为多个transformer encoder的堆叠。由于Bert是双向语言模型,若使用传统语言模型的训练方式会出现see itself的问题,所以Bert借鉴了完形填空的方式,使用Masked Language Model的方式做预训练。又由于bert是一个通用语言模型,它会涉及句子层面的下游任务,所以bert的预训练任务中还加入了Next Sentence Prediction。所以Bert的预训练是一个多任务学习。
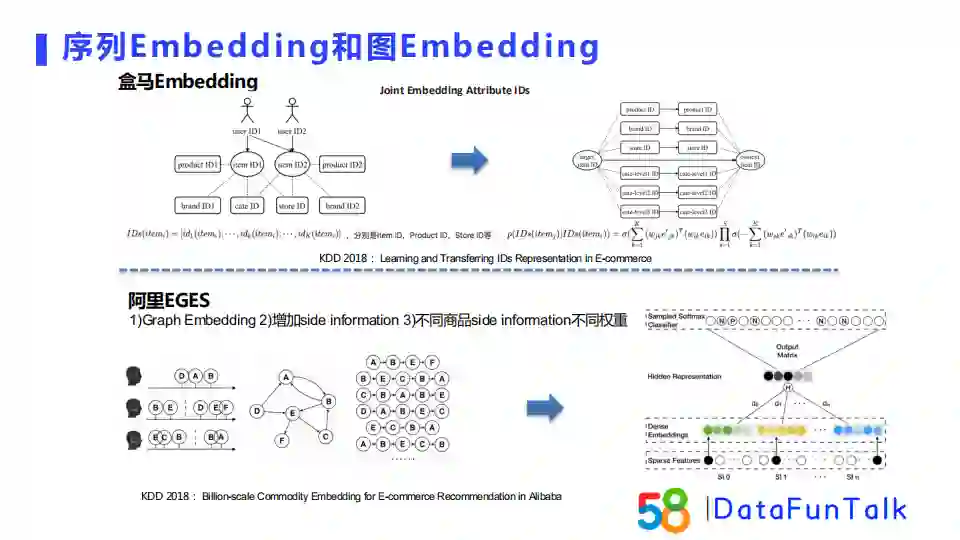
序列Embedding比较经典的模型是盒马Embedding,是item2vec的改进版。盒马没有完全使用item id来作为商品的表征,而是考虑到item的属性信息,例如product id、brand id、category id等。将这些信息组成的列表作为商品的表征。这种方法的好处是将属性映射至同一向量空间,即使有item的某些属性维度缺失,依然可以通过其他维度来计算item的Embedding。所以,这种做法在冷启动阶段会有很好的效果。
阿里的EGES是一个图Embedding,它通过用户行为序列来构建商品关系图,然后使用deepwalk来生成一些序列。基于生成的序列,它使用skip-gram模型,增加了商品的side information并基于不同商品的side information不同权重来训练生成商品的Embedding表征。
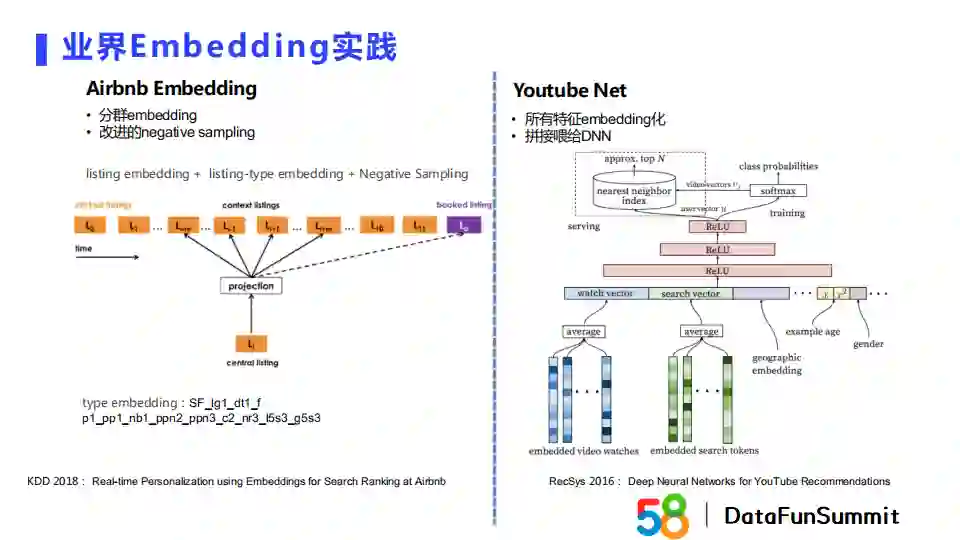
接下来介绍两个业界比较经典的Embedding模型:Airbnb Embedding和YoutubeNet。
Airbnb Embedding的主要特点是分群Embedding,以及改进的负采样方法。分群Embedding是指模型没有直接使用item id,而是使用了商品相关属性的拼接,相当于对item进行了聚类。在改进的负采样中,Airbnb Embedding将下单行为作为正样本,结合自身业务对负采样的策略进行调整。
YoutubeNet将用户的连续特征、序列特征和离散特征全部进行Embedding化后拼接到一起输入一个DNN。在最后进行softmax层分类前的embedding就可以作为用户的Embedding特征。网络的目标是预测当前用户对video的喜好程度,那么在这种情况下softmax层得到的输出就可以作为video的向量表示。他们会将video向量离线建立索引,在线上使用的时候直接将用户Embedding和video Embedding做点乘操作即可。
接下来我来介绍一下Embedding技术在58商业搜索的应用实践。
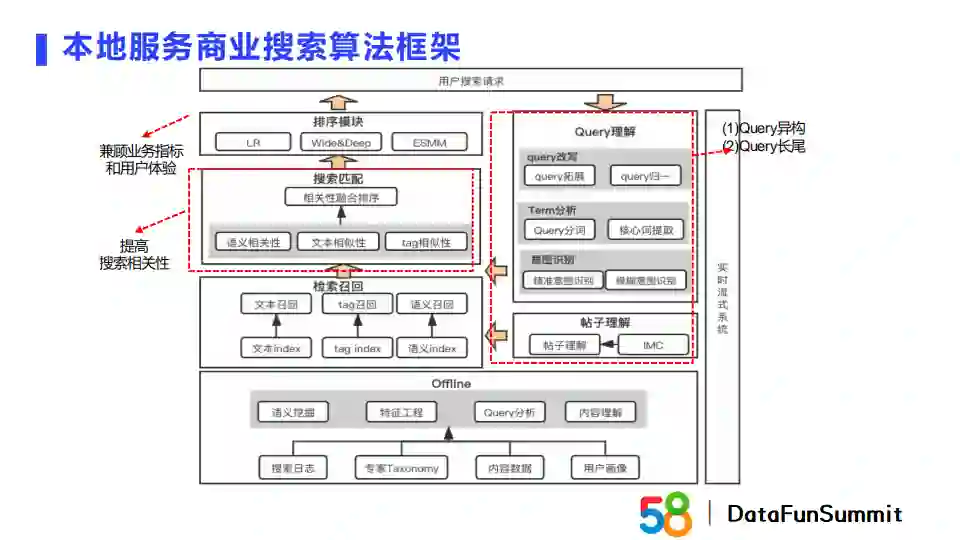
以本地服务搜索流量变现为例,本地服务商业搜索算法的框架如上图所示。当一个用户请求到来后,首先进行query理解、候选帖子理解。之后进入检索召回与搜索匹配阶段,最后输入排序模块得到结果。Query理解中主要包含query改写、term分析和意图识别,重点关注长尾query和异构query。检索召回阶段使用了文本召回、tag召回、语义召回等召回通道。搜索匹配阶段通过语义相关性、文本相似性和tag相似性等指标进行融合,进而保证整个搜索的相关性。在排序层,我们会兼顾一些业务指标和用户体验来进行最终排序。
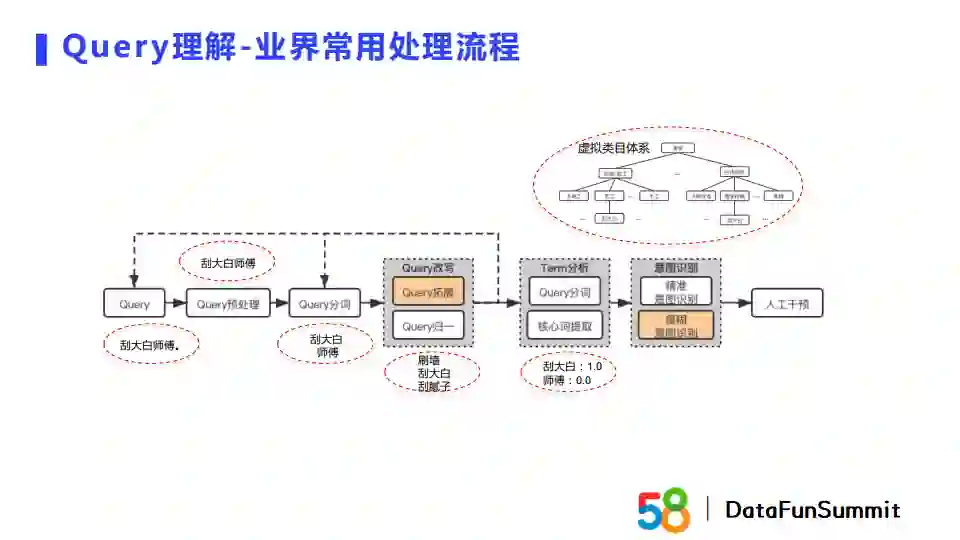
上图展示了query理解的流程。业界比较常用的处理方式如下。首先,我们会对query做预处理,比如会清除标点和特殊字符,随后对query进行分词与改写。Query改写中包含query扩展和query归一,即使用一些同义query或者高相关的query来对query进行扩召回。Term分析主要进行关键词提取。意图识别使用了58内部构建的虚拟类目体系(taxonomy)。
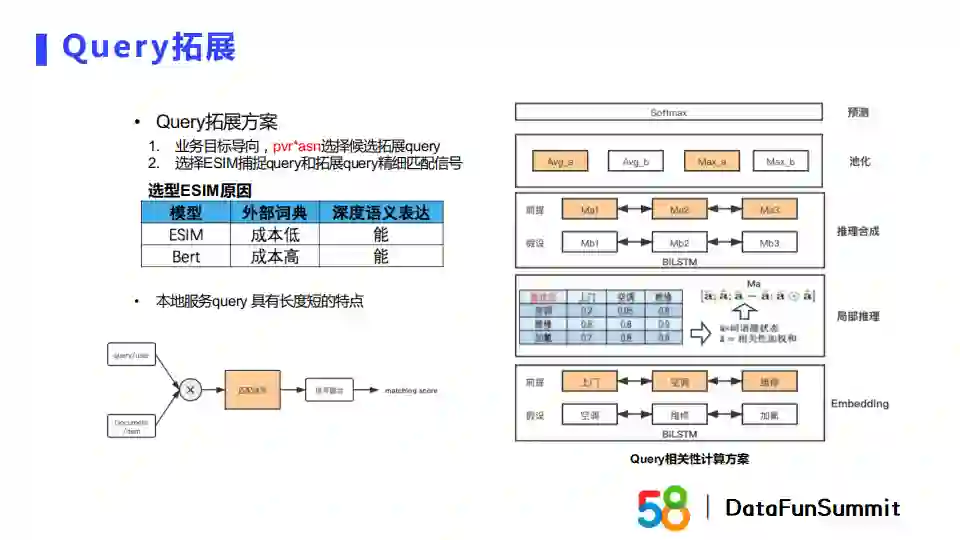
下面我以query拓展为例介绍一下Embedding在搜索的应用。做query拓展时,由于我们发现之前召回的帖子中相关的商业贴数量不足,但实际上我们的帖子库存是充足的。在这种情况下,我们以业务目标为导向,使用pvr*asn指标来召回现有场景中已经具有较高相关性的召回结果作为候选扩展query。我们最初选择ESIM而没有选择Bert,其原因是我们想要利用58内部较强的nlp基础能力。ESIM是一个基于交互的模型,它的做法是query和doc在输入端就进行信息的融合,之后进行匹配信号和信号融合得到最终得分。基于交互的模型会使得query和doc之间的信息交互比较充分,得到的结果准确性会比较高。初版的query拓展是可以异步离线生成的,对于时间复杂度的要求较低。与基于交互的模型相对应的是基于表征的模型,如dssm的双塔模型,其做法是使用两个塔对query和doc生成各自的向量,只在最后阶段做信号的融合。基于表征的模型具备的优势是在线上实时使用的时候仅需要做向量点乘操作即可,可以满足低延时的要求,且模型迁移较方便。但是它的缺点在于向量生成是独立的,导致信号融合并不充分,对准确性有一些影响。所以最终我们在模型选型的时候选择了基于交互的模型。
ESIM基于双向LSTM对前提query和假设query进行特征提取,局部推理层通过假设隐状态与前提隐状态做attention,并将attention的输出做差和乘,最后将向量拼接到一起输入推理合成模块。推理合成会使用另一个双向LSTM,并将提取的特征向量进行池化操作,最后进行预测。

但是在本类搜场景下,ESIM存在一个问题,因为这一场景具有类目约束,用户会进入一个具体类目下进行搜索。由于58的类目体系量级非常大,如果我们分类目进行建模成本特别高。而统一建模的问题在于query在不同类目下的搜索意图存在差异。我们的解决方式是将类目信息加入前提query中,对query进行消歧。
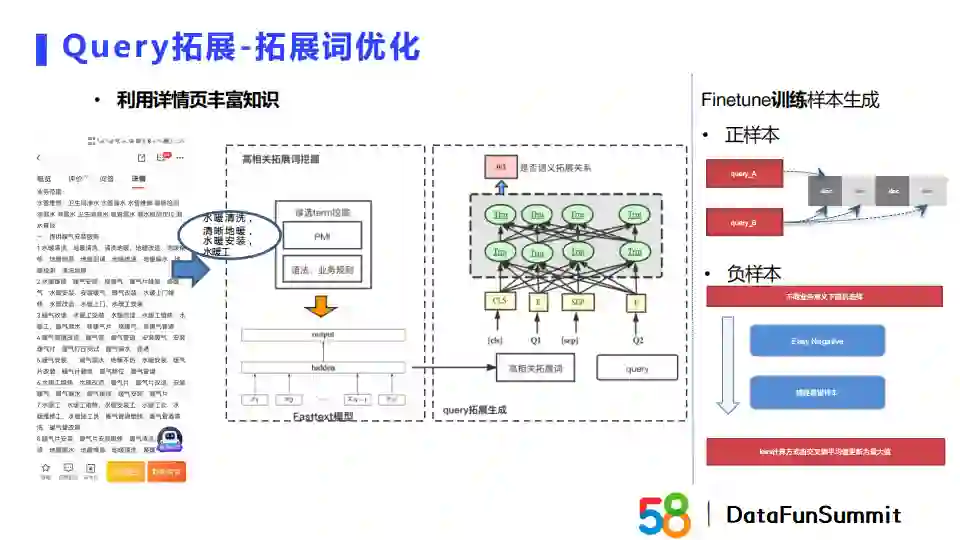
从业务上来看,第一版模型实际上做的是query到query之间的拓展。但是C端用户输入query中的搜索词特征和B端商家在商品详情页描述中所提到的term在语义层面是有一些差异的。实际上,如上图所示,B端商家提供的商品详情页中包含的知识非常丰富。所以,我们想进一步通过C端搜索词和B段详情页term建立一个模型来利用这些信息提升query拓展效果。具体地,我们首先会对整个详情页的信息进行term解析,之后通过fasttext来找到详情页中与query相关性较高的候选term。然后我们基于一个已经经过fine-tune训练完成的bert模型,得到query和候选相关拓展词的相关性排序。最终我们会选取相关性得分较高的词作为最终拓展词。Fine-tune训练是使用两个query作为输入样本的,其中共现的两个query作为正样本,负样本就在不同的业务下进行随机采样。在计算损失函数时,我们将交叉熵平均值调整为最大值。

上图展示了升级后的模型的query拓展效果。例如“刮大白”这一搜索词,它所拓展出来的query有“刮腻子”、“墙面粉刷”,它们和原搜索词是同义的,包含这些拓展词的帖子都会被展示出来。在准确率覆盖率的评估中,这两项指标都达到了80%以上。在上线之后,升级的模型在连接效率和变现效率上都有显著的提升。
下面介绍一下Embedding在58商业推荐中的应用。
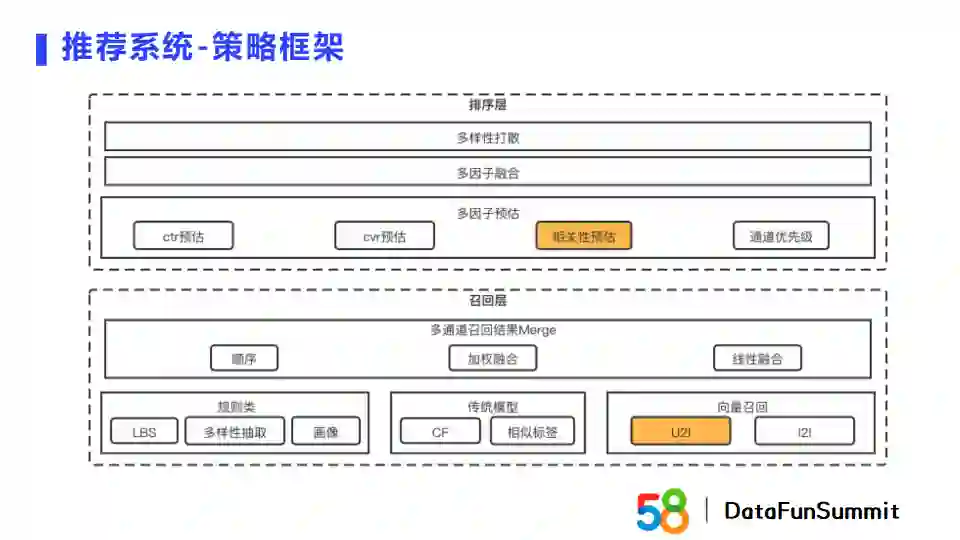
推荐系统的框架由召回层和排序层构成。在召回环节,我们会包含多个召回通道,如规则类、传统模型以及向量召回通道。之后我们会对多通道召回结果做合并。召回层之后是排序模块,我们采用的是多因子排序的方式,同时去预估ctr、cvr和相关性。我们会对多因子进行融合,再对排序结果进行多样性打散,最后得到最终得分。针对Embedding,我主要介绍一下其在相关性预估中的应用。
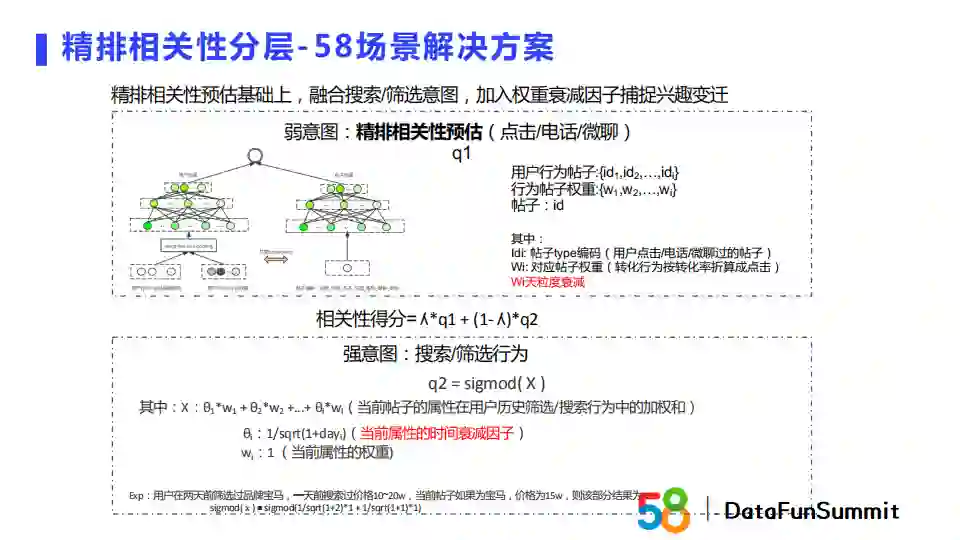
我们在推荐中为什么引入相关性。在商业场景中,排序策略更关注业务收益,但是这会导致用户体验较差。我们希望能够平衡用户的体验和业务收益,其中一个解决方案是在粗排和精排层分别做相关性建模。
在精排层,我们将用户的行为表征分为弱意图和强意图。弱意图可以是点击、电话或者微聊;强意图可以是搜索、筛选等行为。我们对弱意图的建模方式采用传统的双塔结构,而对强意图采用了LR,并且会对搜索、筛选的行为加上时间的衰减。
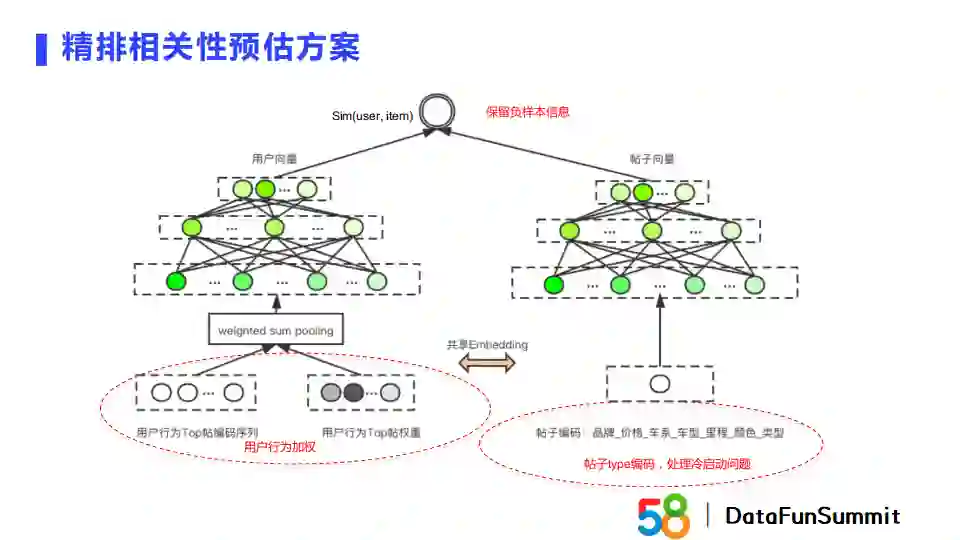
弱意图的双塔结构的左塔是用户,右塔是帖子。在用户塔我们会对用户行为做显式加权,对帖子塔会将帖子的关键属性拼接在一起作为输入,相当于对帖子进行了聚类。
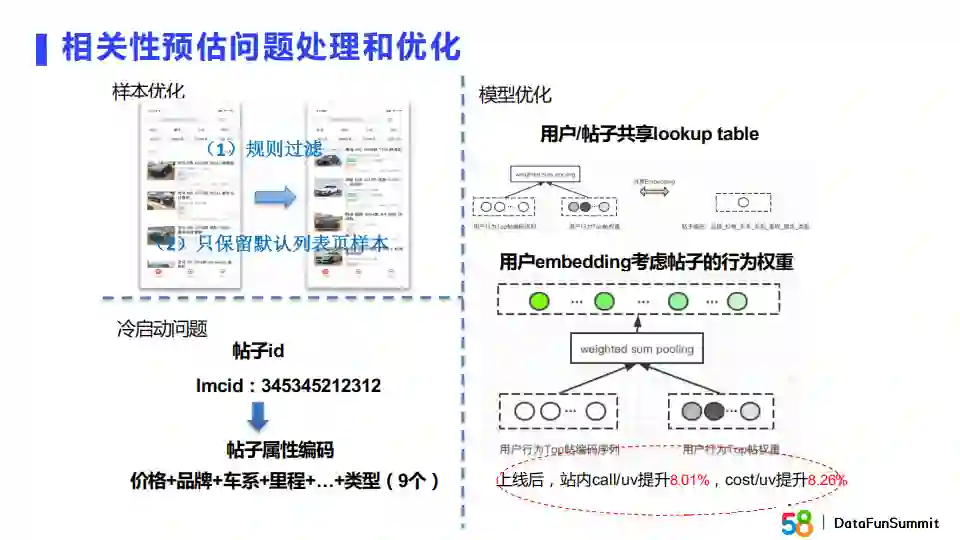
上图展示了我们对相关性预估问题做的几点优化。针对冷启动问题,如之前所述,我们采用了帖子的属性编码信息拼接在一起来表征这个帖子。在模型层面,我们将用户和帖子共享embedding lookup table。在提取用户embedding时我们还会考虑整个帖子的行为权重。
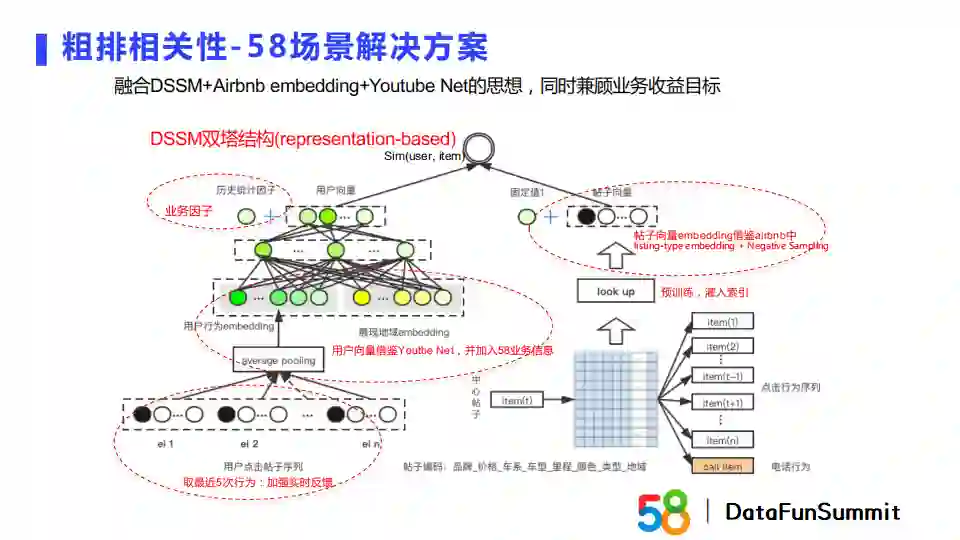
针对粗排相关性,我们融合了DSSM,Airbnb embedding和YoutubeNet的思想,同时兼顾了业务收益目标。具体地,在帖子塔一侧我们借鉴了Airbnb embedding的方式,在精排部分帖子属性中加入了地域相关的维度约束,然后使用帖子属性编码去训练帖子向量。最终预训练完成的向量可以建立索引,在线上服务时不会去更新这些向量,而只是动态更新用户向量。用户塔一侧会考虑到用户的额外属性信息,借鉴YoutubeNet的做法,将用户行为序列的Embedding和用户属性Embedding做拼接作为DNN的输入。我们在双塔向量交互前对向量融入了历史统计因子,将其拼接到DNN的输出向量后。双塔的最终学习目标是优化点击率。
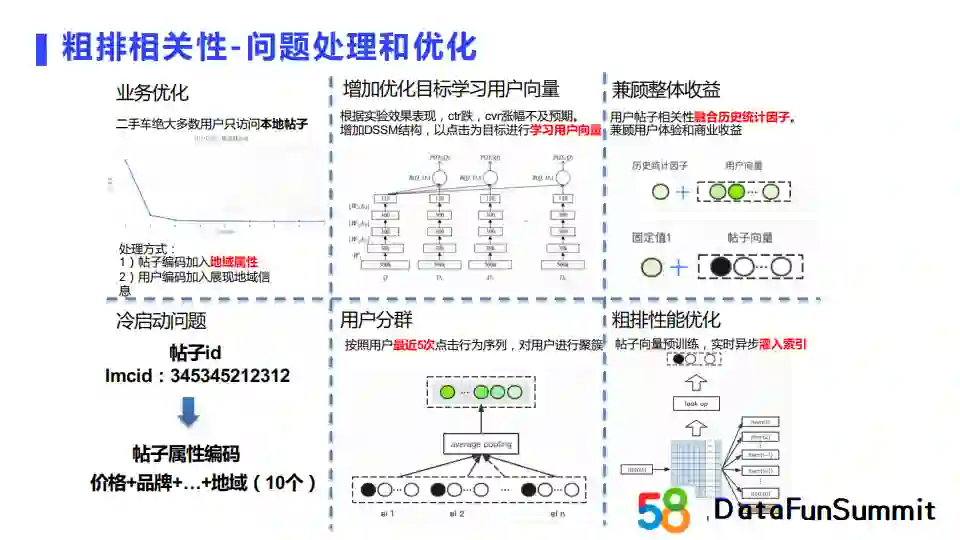
我们在帖子编码中加入地域属性的原因是和业务强相关的。针对模型应用的二手车业务,大多数二手车用户买车只会去关心本地帖子,所以本地倾向性明显。所以在粗排阶段,我们需要加入地域相关信息进行约束,否则就会召回很多异地帖子,进而给精排的输入增加很多不符合要求的候选帖子。其次,我们最开始的模型是使用预训练完成的帖子向量作为表征,然后通过用户行为序列的Embedding做池化操作,进而直接和帖子向量进行相关性计算。但是这种方式在线上的实验效果不理想,ctr指标是下降的。所以针对这个问题我们加入了DSSM的结构,并确定了以点击率为目标对用户塔进行学习。为了兼顾整体收益,我们在优化中针对用户的帖子相关性计算,融合了历史统计因子,使其能够达到兼顾用户体验和商业收益的目标。针对冷启动问题,我们同样对帖子的属性进行拼接作为编码。类似地,在用户侧我们采用了用户分群的思想,按照用户最近五次点击行为序列对用户进行聚簇。最后,针对粗排性能优化,我们是在帖子向量预训练完成后,实时异步地将向量流入索引中。
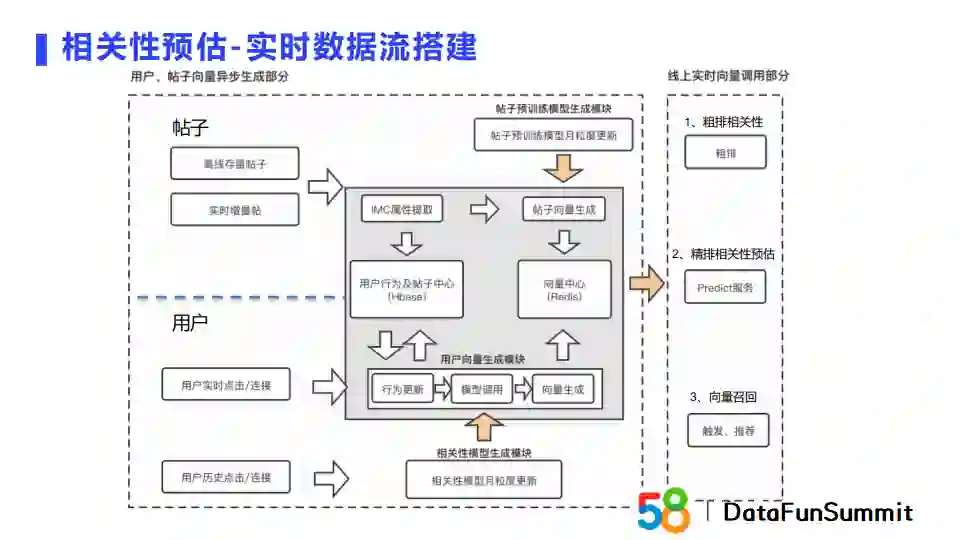
上图展现了线上实时数据流的搭建方案。数据流包含用户和帖子向量的异步生成部分,均包含离线存量数据和实时增量数据。相关性预估模块在粗排、精排和召回模块均有使用。
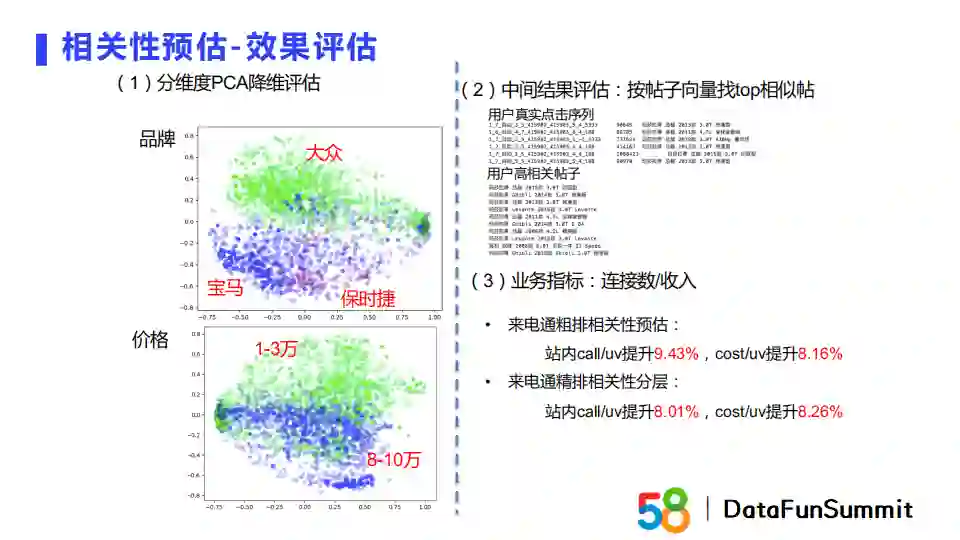
我们针对相关性预估的效果进行了评估,结果如上图所示。以品牌和价格两个维度为例,我们进行了PCA降维进行可视化评估。从结果图中可以发现,我们得到的向量无论在品牌粒度还是价格粒度都有比较好的区分度。上线之后,我们无论在粗排还是精排的相关性预估指标都有较高的提升幅度,说明我们的相关性评估模型效果较好。
Q1:Embedding的效果如何评估?
A:首先,我们会根据不同维度,使用降维的方法可视化地展现向量的区分度。其次,我们也会结合业务场景来关注某一维度的召回结果。同时,我们会根据召回向量的top相似贴做分析来进行效果评估。
Q2:用户和物品双塔使用的特征不一样,那么两者生成的向量为什么可以计算相似性?
A:我们在信息交互前会将用户向量和帖子向量约束在同一个向量空间中,进而使得相似性是可以被计算的。如果你是分别对用户向量和帖子向量进行离线生成,那么在这种情况下相似度确实无法计算。
Q3:有没有考虑ANN检索?
A:没有。因为在召回环节我们会得到与用户query相关的候选帖子。我们直接检索对应的帖子向量与用户向量做点乘即可。
Q4:能否详细介绍一下收益是如何优化的?
A:模型是以优化点击率为主要目标的,但我们不仅仅以点击率为目标,还兼顾了收益率等目标。可以理解为在整个大目标中,我们在召回、粗排、精排不同阶段都会设定不同的收益目标。在这些模块中都会使用Embedding,所以优化收益可以根据业务目标,例如在粗排阶段需要判断优先考虑的是相关性还是收益率;类似地在精排阶段也需要相应地调整策略。我们在粗排阶段重点考虑了相关性,在精排阶段重点考虑了收益目标。整个优化过程需要根据实验结果进行分析。例如实验结果表明ctr出现下降,而模型是以ctr为主要目标的,那么这时候就要去分析哪个原因造成了ctr的下降。可能是对业务场景理解不足出现了如异地召回的情况。还可以以结果为导向,试着重新拟合一个模型来优化ctr,尝试是否可以提升ctr指标。
Q5:预训练的帖子向量多久会进行更新?
A:我们设置的更新间隔会比较长,如周粒度更新。因为帖子向量是全量构建索引的,以天粒度建立索引成本较高。我们现在的模型主要是对用户向量进行实时更新来达到优化模型的目的。
Q6:模型更新的频率是多大?数据长尾问题怎么解决?
A:我们会实时的对用户Embedding进行更新,但它是一个异步更新的过程。针对数据长尾问题,我们使用帖子的属性进行编码来取代帖子id,这样就可以有效地解决冷启动问题。
Q7:为什么没有考虑将graph embedding运用在粗排或者精排模型上?
A:其实graph embedding在召回环节是使用了的,例如EGES。但本次分享主要是介绍相关性模块。
Q8:虚拟类目体系是如何构建的?
A:第一种最基本的方式就是请专家来进行构建,比如邀请产品、技术以及运营同事等,来生成taxonomy树。虚拟类目体系的好处是不使用图谱,而是使用了简单的分类树。对于第二种方式,如果你想建立文本相关的taxonomy树,那么根据语料文本库中的关键词,你可以自下而上地聚合上层的概念来构建关系树。当然,你也可以自上而下地构建taxonomy树,即使用上层概念来向下寻找实体。
Q9:用户塔中加强用户实时反馈的时候使用的是average-pooling,有没有考虑过attention的方式?是不是attention的方式没有带来收益?
A:你所说的方法我们都进行过实验,比如取历史行为序列中的top访问、最近访问以及对行为序列做attention。实验结果表明取最近访问行为做average-pooling效果最佳。
Q10:能否再具体分析一下相关性建模的目的吗?精排阶段是否也可以考虑相关性?
A:我们在粗排和精排环节都会考虑相关性问题。在粗排阶段,我们在兼顾收益的情况下重点关注结果的相关程度。具体地,我们会使用点击率和收益率拉取收益相对比较高的帖子。在精排阶段,我们是计算了query和doc的相关性,这里主要就考虑了两者的相似度。计算出相似度得分后我们会对相关程度进行判定。这里正负样本的比例我们设置为1:4,比例可以通过人为设定一些规则来对正负样本结果进行约束。整体上来看,我们在粗排阶段优先保证了收益,在精排阶段保证相关性。
Q11:相关性预估的样本是从哪里得到的?
A:相关性预估的样本是从用户的历史行为记录中得到的。比如用户发生了点击、转化、电话、微聊等行为就可以作为正样本。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。