

分享嘉宾:王晓伟 快手 AI算法研究员 编辑整理:AMS 周金星 出品平台:DataFunTalk
导读:召回作为整个推荐系统的第一个环节,承担着极其关键的作用,在从全集内容中筛选出用户可能感兴趣子集的同时,又需要保证推理的高效。图神经网络在这两方面具有得天独厚的优势,我们可以利用图中蕴含的高阶结构关系,结合已有的属性信息,得到节点全面而精准的向量表示,应用于后续的召回。快手平台不同场景下的视频推荐特点和需求各有不同,基于图神经网络的召回方式在各个场景具体是如何应用的,又有哪些已优化或者亟待解决的问题?本文将结合实际场景的实现和优化进行介绍。 具体内容包括: * 短视频推荐背景 * 基于图的I2I召回流程设计 * 实际场景优化 * 未来展望
01* 短视频推荐背景**
首先跟大家介绍一下短视频推荐的背景。
1. 业务特点和痛点
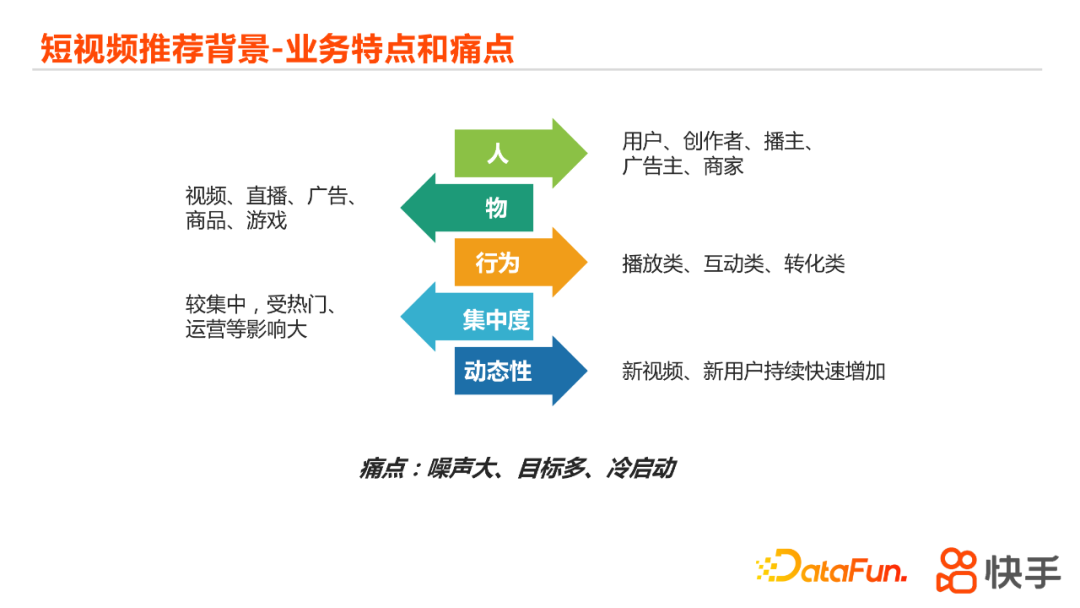
在短视频的推荐业务场景中,人、物、行为都比较多。人也就是角色包含了普通的用户、视频创作者、直播播主、广告主、商家等;物也就是内容包括了普通的UGC或者PGC的视频、直播、广告内容,还有一些售卖的商品、游戏。然后这些人和物结合的话,也会产生多种多样的行为。行为主要可以分为播放类(看视频)、互动类(点赞、评论、进入个人主页)和转化类(广告点击、表单提交等)。 这些人物行为结合在一起,体现在短视频的场景下有两个特点:集中性和动态性。集中性,是说绝大部分的行为会集中在一些热门或者一些运营活动带来的视频上面。动态性,指整个平台上面的新视频、新用户都是在持续的快速增加的,会使得整个系统的一直在持续的动态变化当中。上面这些特点也就导致了我们在短视频的推荐当中会面临一些痛点,主要包括:噪声大,目标多,以及冷启动的问题。
2. 召回体系的发展
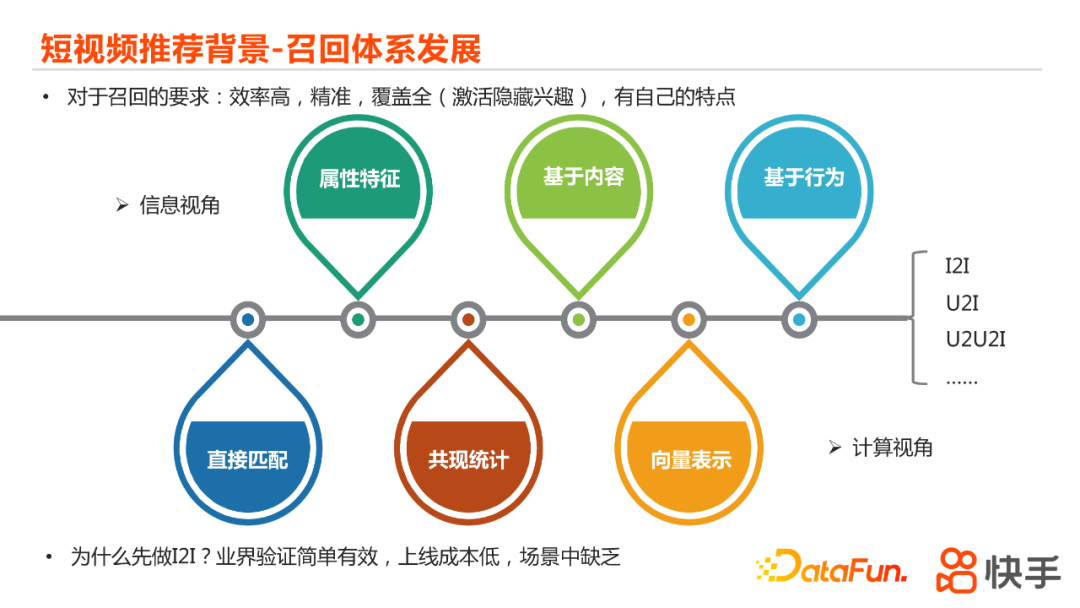
在短视频的推荐里面,整体上与业界通用的推荐场景类似,都是分为召回、粗排精排、重拍等阶段。召回是在整个推荐系统里面的第一个环节,它的作用是需要从海量内容池(比如说几百万、几千万、甚至上亿)中快速筛选出用户可能感兴趣的内容。所以对于召回来说,第一个要求就是效率要足够高:能快速的从海量的内容池里面进行筛选;其次的要求是精准性,也就是说筛选出来内容要跟用户的兴趣有关联;然后是多样性,对于整个召回体系,我们希望对于用户的兴趣有足够全的覆盖,甚至能激活一些用户当前没有表现出来的隐藏兴趣。针对单个召回路,我们希望它有自己的特点,这样它才能推荐出来与其他已有召回路不同的内容,对于整个系统来说,才有增量价值。 整个召回的发展可以从信息和计算两个视角来看。从信息视角来看,最简单的,可以只利用一些待召回物的属性特征,比如视频的作者信息,或者它的一些标签。随着NLP、图像、语音技术的发展,我们现在可以基于视频提取出它本身内容的信息,比如标题信息、视频里面关键帧的信息、还有一些语音信息,此外,我们其实还可以加上用户的行为数据,去得到更好的关联召回结果。从计算视角来看,如果我们只利用一些简单的属性特征,召回可以直接基于一些匹配实现,比如相同作者的其他视频,或者相同标签下面的其他视频。如果还有一些内容和行为数据,我们可以利用CF(协同过滤)的共现统计去得到待召回的内容,现在最常用的是通过向量去计算得到召回的结果,我们会把包括属性、内容、行为的信息转化成embbeding的向量表示,然后通过向量相似度计算的工具去快速得到待推荐召回结果。现在常用的召回方式有I2I(商品到商品)、U2I(用户到商品)、U2U2I(用户到用户到商品)等。
3. 为什么需要图
为什么是I2I?首先是I2I在很多公司多种场景已经被验证,被证明是一个简单且有效的召回方式。其次,I2I的在线和离线是可以解耦的,新上线的成本比较低。另外我们在优化的场景中,发现这种I2I的召回还是比较缺乏的,所以我们现在是先从I2I开始做。
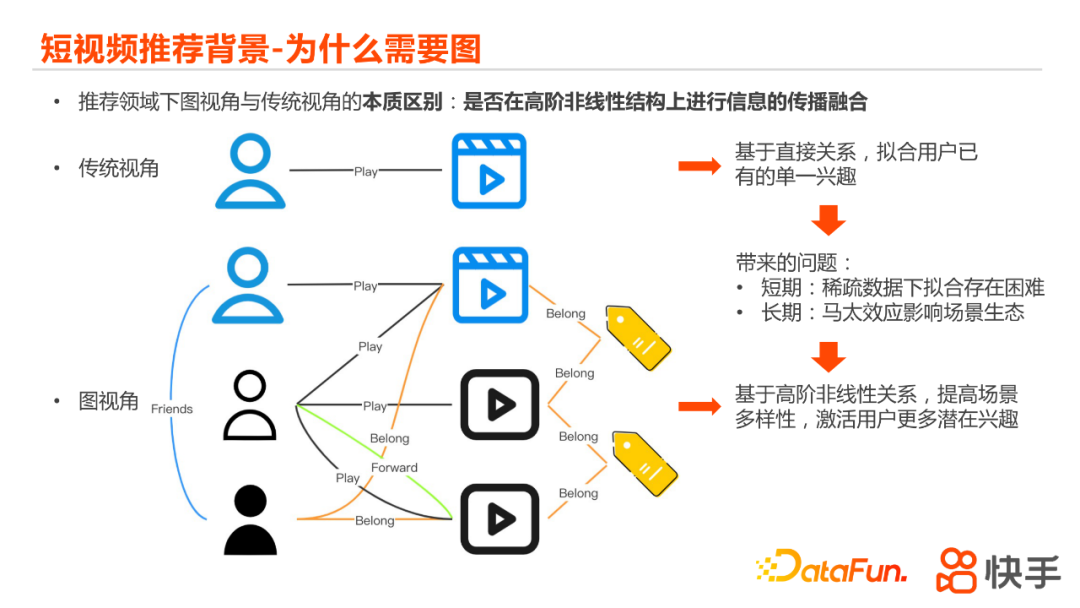
为什么要通过图的方式去实现这个工作?从传统的视角来看的话,推荐是说给了一个用户,尽可能去召回他感兴趣的视频,这个关系是直接的一阶关系,我们的model也只拟合了他当前的单一兴趣,但是如果把用户和视频展开来看,把它变成一个图或者一个网络的话,可以发现用户和用户之间、视频和视频之间、用户和视频之间其实还都存在着各种各样更多的、不同的、复杂的关联。
为什么传统的只考虑一阶关系是有问题的?从短期来看,整个产品中的用户数量和视频数量非常大,但真正有这种一阶关系的,在整个UI的矩阵当中仅仅是很小一部分,也就是这个矩阵非常稀疏,在这种稀疏的数据下面去做拟合是很困难的。从长期来看,因为推荐系统有选择曝光偏差的问题,导致绝大部分的行为集中在很少的一部分热榜视频身上,容易导致马太效应,长期累积会影响场景生态的健康发展。但是通过图的视角,考虑的是高阶的非线性的关系,一方面这个用户可能会跟更多的视频产生关联,会对于整个我们这个模型带来更多的正样本;另一方面,用和用户之间、视频和视频之间的一些相似性的要求,也会为模型带来更多正则项,提高模型的泛化能力;再进一步,能达到提高场景多样性、激活用户更多潜在兴趣的目的。
02****基于图的I2I召回流程设计
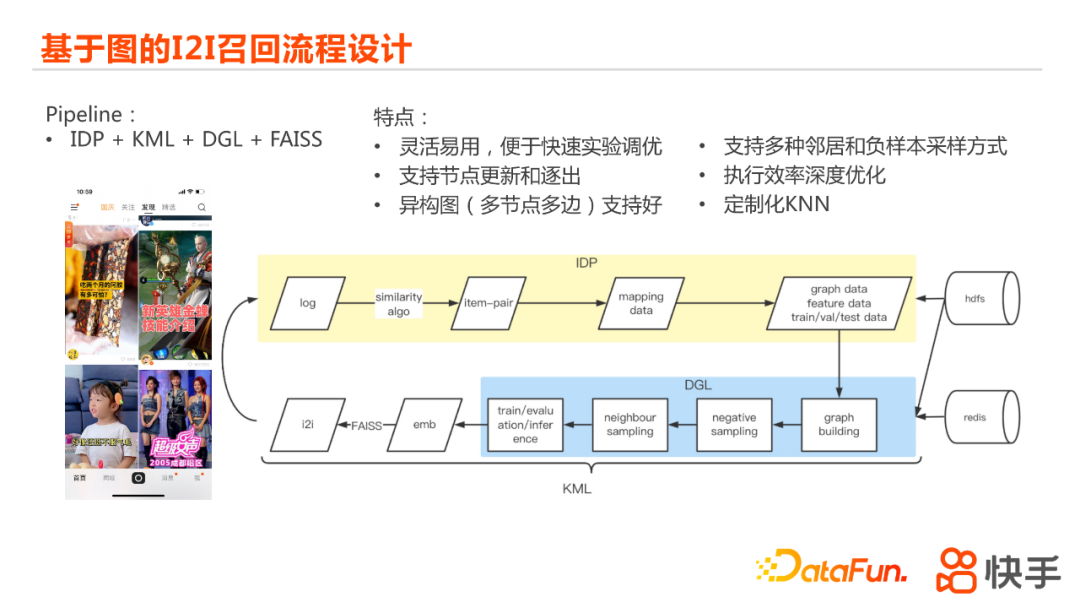
接下来给大家介绍一下现在我们快手使用的基于图的I2I召回的pipeline,我们的pipeline主要是基于IDP、KML、DJL、FAISS这些平台和工具去搭建的。IDP是快手内部的集成开发平台,它主要的功能是做一些数据处理,并且实现这种离线数据的任务调度。KML是我们自己开发的一站式机器学习平台,主要是能帮助我们做模型的训练预测和模型管理。DGL是和FAISS更是整个工业界目前比较优秀的框架和工具。我们在这些工具和平台的基础上进行了一些特定的封装和优化,就生成了我们现在整个的基于图的I2I召回的pipeline。
pipeline主要包括了从原始数据的处理到item-pair的生成,到训练的一些数据的生成,再到图算法当中图的构建,然后是负样本和邻居的采样,到训练预测的一些过程,再到产出embedding和最终的I2I,当用户曝光展示,拿到行为之后,pipeline的流程就会进行循环。
我们为什么会采用这么样一个pipeline?其实现在工业界,包括我们内部也有一些图的框架,但我们调研发现,如果用公司内部定制性的框架,上线起来会容易一些,但是在算法的优化迭代上面成本会稍微高一些;如果用其他开源的框架,它的算法优化起来会比较容易,但是进入整个上线流程会比较困难。综合考虑,我们利用了这样一套流程去构建了整个上线的过程。这套流程的有点主要有:灵活、应用快,便于快速的实验调优;实现了节点上面的更新和逐出,支持图上节点的动态变化;异构图(多边多节点)的支持很好;支持多种邻居和负样本采样方式 ;执行效率深度优化;定制化KNN ,满足目前的上线要求等特点。
03****实际场景优化

上文提到我们短视频推荐主要是会有这三个痛点,噪声大、目标多和冷启动问题,由于时间的关系,今天主要集中介绍去噪的工作。我们使用的优化方式主要包含了相似度度量优化、图结构学习、边权重学习。
1. 相似度度量

相似度度量优化是指基于其他方法产出I2I的初始图去做优化,我们使用了一个简单的小trick,是基于这种neighbour-based method(基于近邻的方法)的节点相似度度量优化。产出原始的I2I的图的比较常用的方法有Jaccard相似度(考虑两个节点之间它的共同邻居和所有邻居的关系)和Adar相似度(计算共同邻居里面对于邻居热度做一个加权)。这里我们发现不同的邻居,对于这两个节点来说,它的作用其实并不仅仅体现在这个节点和邻居节点的热度上,举一个例子,我们要从X点到Y点之间有存在很多流水的管道,从X到Y的话,我们要经过Z点,整个X到Y它的流水流速,是由X到Z管道的直径和Z到Y管道直径这两个里面较小的这一段管道来决定。所以我们在基于Adar的基础上,对它的分子做了一个加权,这个加权表示XZ和YZ这两段管道直径或者是说在我们场景里面一个相似分的表示,这个分子的权重是由较小的值来决定的 。相似分我们可以简单地只通过比如说它们的共同曝光、共同点击或者观看间隔等统计量去表示。我们通过简单的这一个小的trick的优化,其实可以在离线Hit-Rate的上面看到一个比较明显的一个提升。
2. 图结构学习
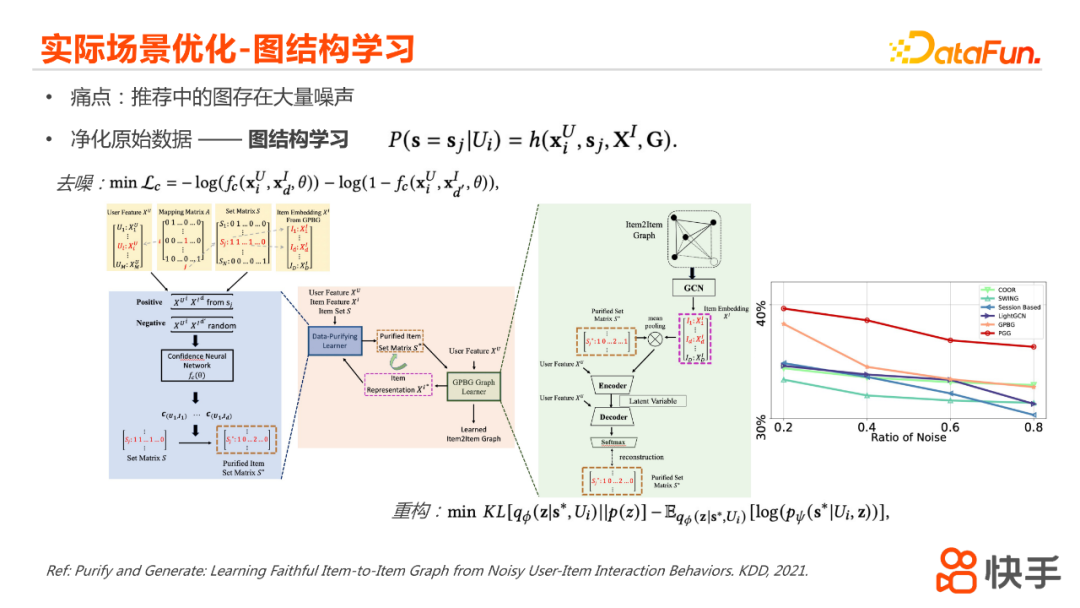
第二个优化的方式的话是基于对原始数据的净化去做,我们采用是一个图结构学习的方案,这个工作是跟清华崔峰老师实验室一块儿合作去完成的。整个的算法的框架,分为两大部分,左边这部分是基于重采样的数据去噪的模块,右边是基于用户个性化行为embedding学习的模块。左边我们会首先去训练得到一个置信度的网络,网络代表的是对于用户和我们场景中也就是视频User&Item这个pair有多大的置信度是一个真实的行为,也就是说用户对于他有行为的视频有多大的置信度(是真的是有行为,还是因为一些其他原因比如误点或者一些运营的因素影响才去观看)。在置信度网络的基础上,我们比较特殊的点在于利用了一个user和set的信息,set里面包含的是在一个session当中,用户所观看或者是有行为的所有的视频的集合,然后我们会利用网络对于user的set做一个重采样,这个采样的过程其实可以理解为是通过一些用户长期稳定的行为去对他短期行为做了一个过滤,得到一个净化过后的set表示。然后就会到右边的图机器学习的模块当中,我们利用净化之后的set,以及我们需要得到的I2I的图的关系、I2I的embedding,然后我们会利用I2I的embedding对于净化后的set做一个pooling的表示。之后会接一个VAE的结构去对set做一个encoder和decoder,希望能重构出来用户净化过后的set集合的表示。去噪和重构这两部分的loss是我们整个模型里面所有的loss。这样的方案我们可以在理论和实验当中看到它的一些优势:最右边这个图,它的横轴是我们在数据集中插入的噪声比例,纵轴是不同模型的准确度,上面这条红线是我们提出的模型的表现。可以看出,它对于噪声来说是更不敏感的,也就是它更鲁棒的。这个工作已经在今年的KDD被录用了,有兴趣的同学可以去关注一下Paper。
3. 边权重学习
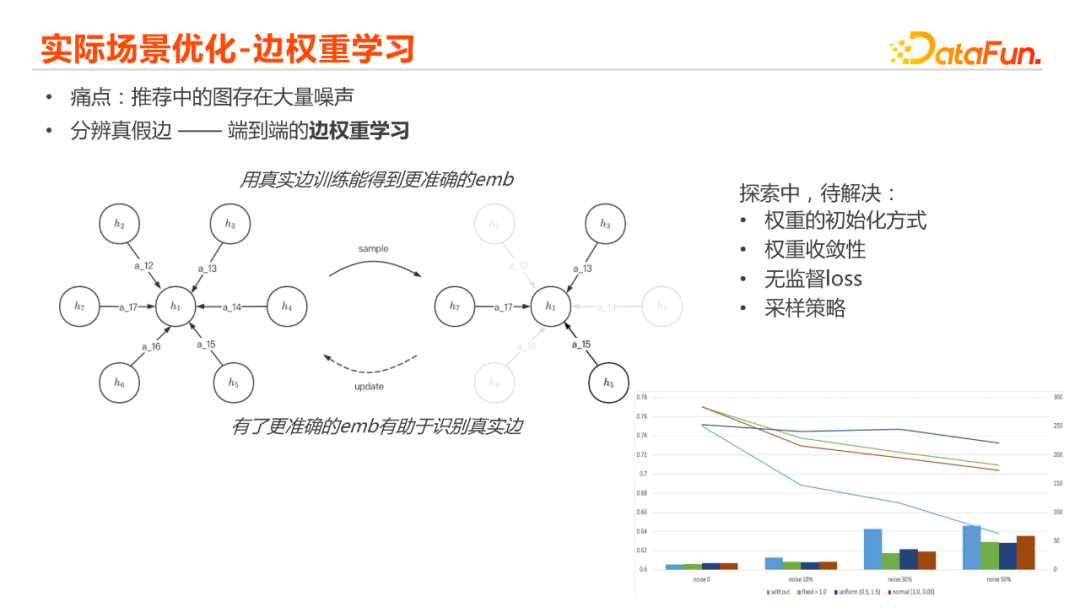
第三部分,我们主要是基于上线成本的优化。其实上面的工作,理论和离线实验的结果是比较好的,但是因为有去训练confidence的model的过程,这在我们上线过程当中,成本是比较高的,我们想有没有一些方法能去快速的进入我们线上的流程。我们有一个很直接的方式,如果有一个图,它里边不管通过什么方式,我们知道它们存在一些边,我们通过什么样的方法能去分辨出来这些边的真实性,于是就提出了一个端到端的一个边权重的学习,intuation(直觉上)也比较的简单直接,其实就是如果我们能知道对于当前这个节点,它所有邻居、它的边的权重表示的是这条边的置信度,我们就能去根据置信度以更大的概率采集到真实的边,然后在真实的边的基础上再去做embedding的训练,能得到一个更准确的embedding的表示。反过来,如果我们有更准确的embedding的表示,也能有助于我们识别出来原始图中哪些边是真实的边,哪些边是虚假的边。这样的话我们相当于是把之前图的训练过程前移到了这个图的连续采样过程中,然后这两部分去做一个循环迭代。我们在一些实践场景中的数据也能也能看到一些比较明显的优化效果:最右边的图与上边的图类似,横轴是数据当中插入的噪声边的比例,纵轴是模型的表现,上面这三条线其实都是用了边权中学习的一些方法,它们区别是用了不同的边权重的初始化方式,浅蓝色这条线是没有边权重学习的表现。不难看出我们加了边权重学习之后,整个模型的鲁棒性是提高的,另外底下的柱状条表示的是当下model达到最优这个点的时候,所需要循环迭代模型训练的迭代轮数,也能看出加了边权重学习,达到最优点的时候,它需要循环迭代的次数是更少的。
整个方案也还在探索和优化当中,这边列举了我们现在正在解决的一些问题。包括什么样的权重的初始化的方式是更好的,不同的初始化可能会有不同的结果。另外就是边权重的收敛性,很多的情况,边的权重是一直在变的,并不能确定在什么情况下,它能收敛到一个最优的结果。以及现在的模型还是跟原始的模型一样,采取的是有监督的loss,我们是不是能加入一些无监督的loss来达到指导辨别真实和虚假边的目标。最后一块是采样的逻辑,在实验当中我们是初始按随机采样,训练到稳定之后再去加入加权的采样,还是从一开始就做加权采样?它的结果也是有差异的,那什么样的策略会是最优的策略。这些都是我们目前还在探索和解决当中的问题。
4. 图召回线上特点
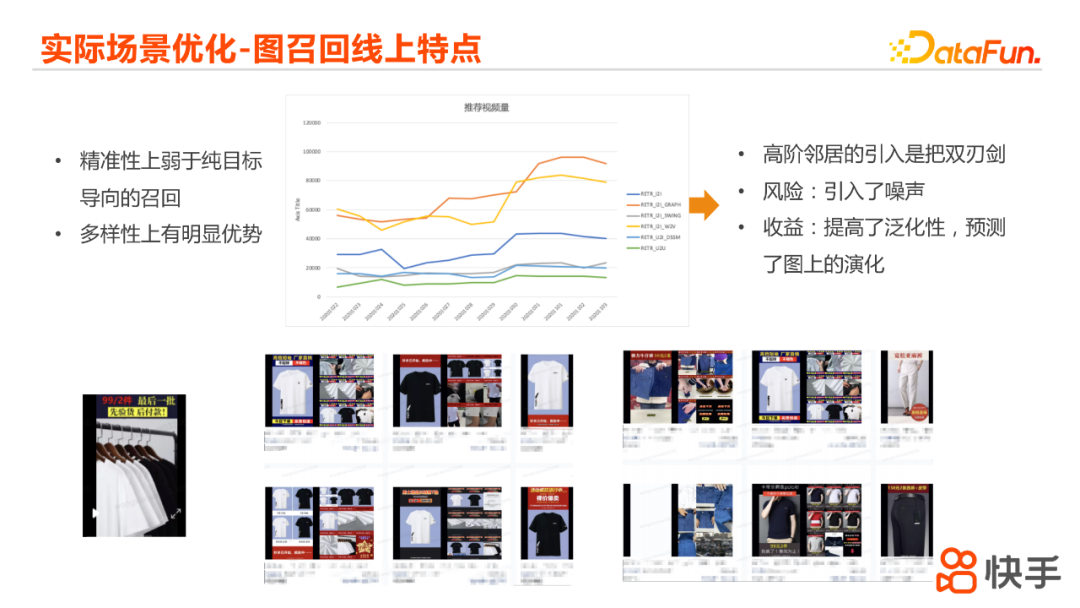
上文我们之前介绍到的一些方法,在快手的一些业务场景中也有一些线上应用和优化的结果。我们从一些场景中观察到的基于图的召回,相对于纯目标导向的召回,它在精准性上是相对来说更弱一些的,但是它有一个比较明显的优势,就是多样性上的优势。这个曲线图就比较有意思,横轴是上线之后不同的日期,纵轴代表的是这一路召回推荐出来不同的视频量的和,这里面橙色的线是我们graph(图)召回的情况,可以看出,它在这个过程当中有几次畸越,随着训练,图召回的不同视频量是会递增的,召回的递增其实也在为其他不同的路带来更多不同种类的样本,也会带来其他路召回量的提升,所以使得整个场景的多样性有更好的表现。基于之前一些实验的结果,我们认为就在图里面把高阶的邻居引入其实是一把双刃剑,在风险上来说,它引入了这些高阶邻居里面的噪声,也是因为这一点,我们现在主要工作是集中在如何对数据去噪,它的收益的主要体现在提高整个模型的泛化能力,能去预测图在未来的演化,这其实跟召回本身的目的也是一致的。这页展示了我们在场景中的一个case,是商业化广告场景,最右边是使用了图召回的方式,最左边是trigger:黑色和白色的T恤。可以看到之前目标导向的I2I,推荐出来基本上都是白的或者黑的T恤,然后右边图的方式,可以看到有不同款式、不同颜色的T恤,还有一些相关的裤子类的商品。我们认为这对于我们整个场景的生态发展是更优的。
04****未来展望
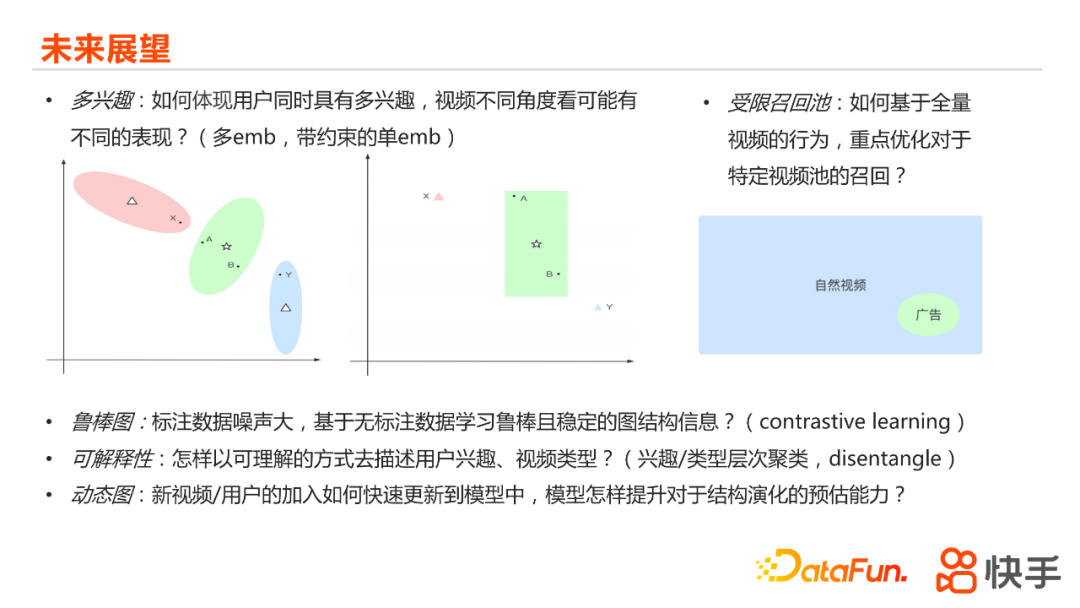
最后跟大家聊一下,我们认为在图召回上未来可能的一些技术方向展望。首先是多兴趣,我们认为用户他肯定不是只有单一兴趣的,怎么样去描述多兴趣?要么是利用多embedding,要么是带约束的单embedding,这样其实都会有一些问题,例如:embedding数量怎么去设置,单embedding甚至是不是能表达多兴趣等。我们现在一个思路是,之前学习节点的embedding都是对它做点的预估,也就得到一个固定的embedding的表示,我们是否能学到一个embedding的分布,然后对于不同的点,它的embedding都是有一个分布的范围,如果我们在做召回的话,就能根据比如对这两个节点去计算它们相似度的时候,根据他们的分布去得到一个比较适合的一个采样,到它真正一个embedding表示之后,再去计算它的相似度。这样在不同的兴趣上面的话,我们是希望能通过得到一个在分布中采样到不同的节点的表示,然后来实现多兴趣的目标。第二点是受限的召回池,主要是在商业化场景中比较明显,是说整个场景中自然视频的量和行为数是远远大于广告视频的,但是我们实际场景中更希望是能得到这部分广告视频的更精确的embedding,怎么样利用全集的数据去重点优化有特定限制的召回池的效果,这也是我们认为在实际场景中比较重要的一个问题。其他的话,对应上文提到的去噪的优化,就是如何得到更鲁棒的图,我们后面计划引入一些contrastive learning(对比学习)或者unsupervised learning(无监督学习)的方式去做优化。以及还有可解释性、动态图的优化,这些跟我们整个场景的生态、业务需求都是强相关的,我们认为未来比较值得去做持续的优化。





