Paper Reading | CVPR 2017最佳论文作者黄高深入解析深度学习中的三大挑战


Momenta,打造自动驾驶大脑。
我们致力于打造一个自动驾驶学术前沿知识的分享沟通平台,深入浅出让你轻松读懂AI。
感谢Momenta研究员,来自清华大学的实习生邱楚聿整理成文。
Momenta Paper Reading 第12期回顾
【 主讲人:黄高 】
CVPR 2017最佳论文《Densely Connected Convolutional Networks》第一作者。
清华大学博士、康奈尔大学博士后,主要从事机器学习相关研究工作。
曾先后在圣路易斯华盛顿大学、新加坡南洋理工大学、微软亚洲院做机器学习相关研究。
从深度学习的蓬勃发展开始,众多经典的网络设计从LeNet、AlexNet到VGG、Inception、ResNet等,都推动了一波又一波的人工智能的高峰。
目前来看,深度卷积网络挑战主要有:
1、Underfitting(欠拟合)。一般来说,模型越为复杂,表达能力越强,越不容易欠拟合。但是深度网络不一样,模型表达能力够,但是算法不能达到那个全局的最优(resnet基本解决)。
2、Overfiting(过拟合),泛化能力下降。
3、实际系统的部署。如何提升效率和减少内存、能量消耗。

Insight:训练深度网络很困难时长太长,如何在训练时训一个比较浅的网络,而部署时得到更深的网络?
目的:提升网络的训练效率,进一步改善网络的泛化性能。
方法:在训练的每一个iteration前,在resnet的每一个Residual Unit上,我们只需随机扔一枚硬币,判定这个Unit是否被消去(去除非线性stack只保留直连)。最后再做前向和后向的传播。这样,我们每一次都相当于在训一个浅一点的网络,最后这个大网络也能收敛,效果不错。
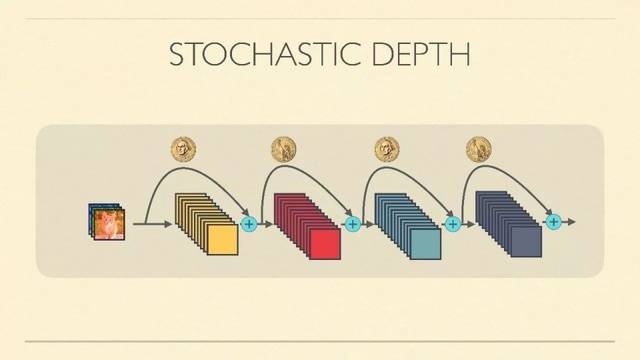
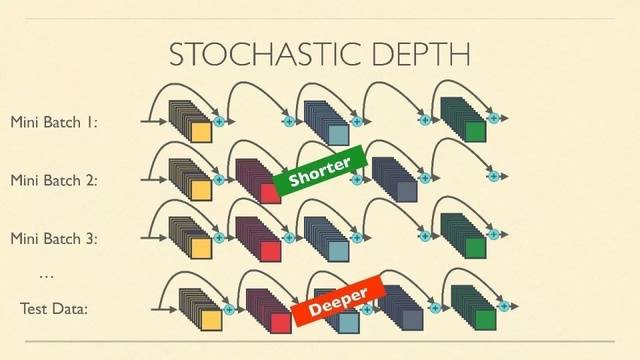
细节:注意,这个随机硬币并不是五五开对称的,而是用线性插值来决定。例如,第一个unit的生存概率为1,最后一个为0.5,中间各unit做一个线性插值。因为前几层的提取相对重要,我们直接让第一个unit生存概率为1,只要决定最后一个unit的生存概率,一个超参数。
效果:Cifar-10上,新方法训练resnet时,比常用方法测试集误差低,准确率更高,但是训练误差高,说明正则化效果很好。
启示:为什么这个简单的方法效果很好?
网络冗余性:训练时扔掉大部分层却效果不错,说明冗余性很多,每一层干的事情很少,只学一点东西。

Insight:如何消除上述的冗余性?更紧致的结构?更好的泛化性能?
目的:减少不必要的计算,提高泛化性能。
方法:根据之前分析的冗余性,ResNet很多计算其实是隐式地把之前的feature复制到后一层。怎么避免计算上隐式的copy操作?一个直接的方法就是把之前所有的feature直接concat到这一层的输入,我们每一层的主干channel比较小,每层只学一点点应该学的。这样用显式的concat来替代掉了隐式的计算“拷贝“。
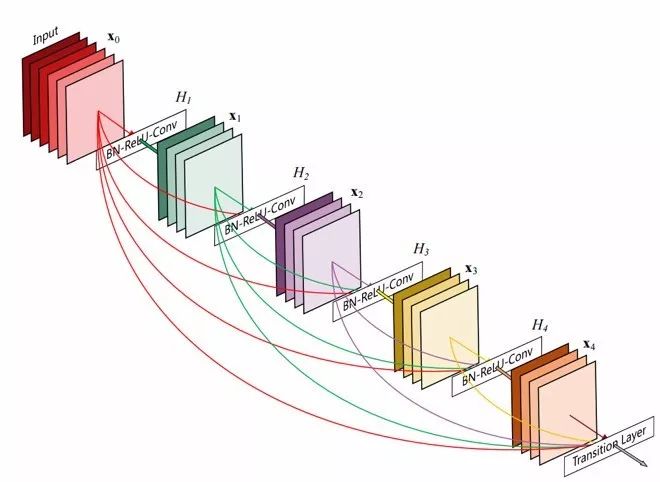
细节:由于输入的channel会随着深度增加而增加,因此每个stage后使用了类似ResNet的bottleneck1*1来降低输入channel。
效果:
比较好进行反向传播,前层会比较好的受到梯度的监督。
参数量降低,计算高效。
分类器建在所有层的feature上,从相对光滑到粗糙的决策函数的线性组合来cls。对比只在最后一层,粗糙的决策面。
最终在ImageNet等数据集上,同等计算量下都比当时state-of-the-art的网络表现要好。
彩蛋:如果没有data augmention,CIFAR-100下,ResNet表现下降很多,DenseNet下降不多,说明DenseNet泛化性能更强。

Insight:人辨别简单和难的物体,反应时间不同。神经网络能否分辨简单和复杂的任务?
目的:图像分类上,高效利用计算资源,简单的任务更快,复杂的任务稍微慢一点,平均速度提升。每层都有一个cls?不行,downsample的作用会很重要。
方法:为了在浅层时来判断是否达到置信要求,我们希望能在各个层都能加分类器来判断。由于downsample非常重要,在浅层(大feature)后直接接分类器,表现很差。如果将downsample提前,表现也很差。因此我们设计了二维结构,横轴代表深度,纵轴代表尺度,分类器只接在尺度比较小的feature上。并加入了dense connection。如果没有dense connection,各种cls的联合训练会导致冲突,可能前期的特征会被抵消掉。加上密集连接后,前期的特征会直接连上,解决了这个问题。
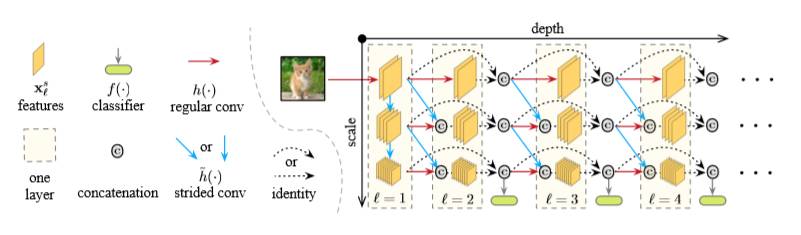
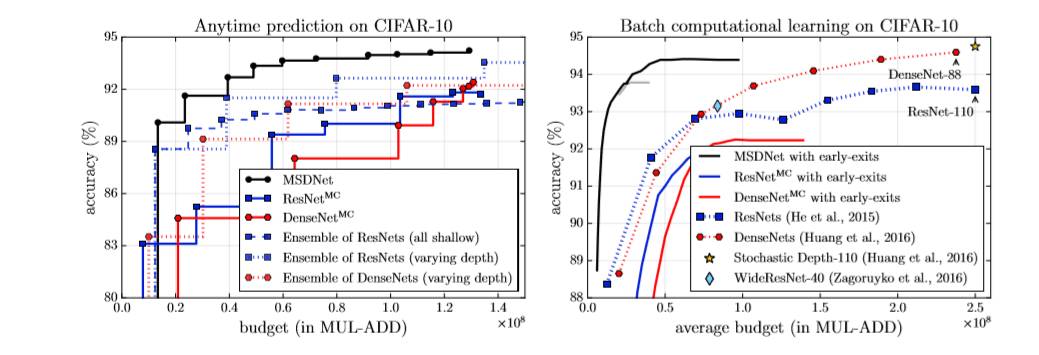
效果:在CIFAR-10、CIFAR-100和ImageNet上,我们在相同平均计算量下推理的平均准确率比state-of-the-art都要高。

我们欢迎有梦想,有能力的技术人才加入我们,目前有多个研发职位开放招聘,点击文末“阅读原文”可查看职位详情。
Momenta,打造自动驾驶大脑。
Momenta致力于打造自动驾驶大脑,核心技术是基于深度学习的环境感知、高精度地图、驾驶决策算法。产品包括不同级别的自动驾驶方案,以及衍生出的大数据服务。
Momenta有世界顶尖的深度学习专家,图像识别领域最先进的框架Faster R-CNN和ResNet的作者, ImageNet 2015、ImageNet 2017、MS COCO Challenge 2015等多项比赛冠军。团队来源于清华大学、麻省理工学院、微软亚洲研究院等,有深厚的技术积累和极强的技术原创力。
我们因同一个梦想相聚,真诚期待你的加入!
登陆www.momenta.ai了解更多精彩。
往期Paper Reading(点击文字查看)

扫描二维码,关注MomentaAI公众号
点击公众号主页-学术分享-往期回顾,马上获取更多资讯。

点击“阅读原文”,获取校招资讯及职位详情




