一周精品论文分享-0325
分享几篇最近阅读的论文。经常会有人问我,为什么简单粗暴的模型平均(Model Average)方法会比单机或单卡的方法取得更好的泛化效果呢?下面这篇文章很好的解释了这个问题。
Averaging Weights Leads to Wider Optima and Better Generalization
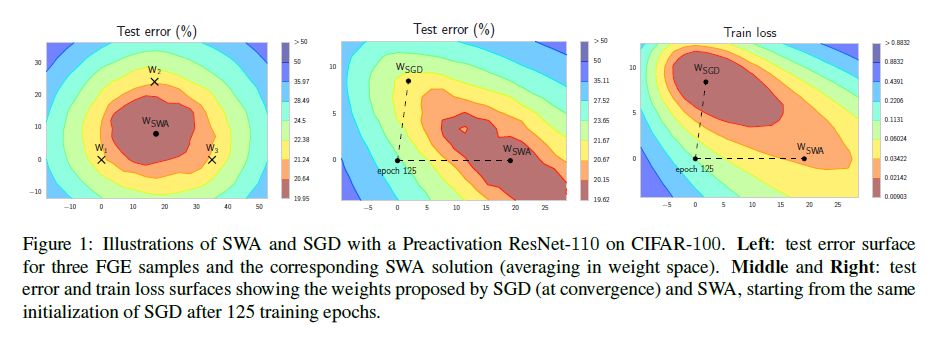
摘要:深度神经网络通常通过采用带衰减学习率的随机梯度下降法(SGD)来最大或最小化模型的损失函数,以此来优化模型参数。结果表明,当学习率为常值或循环变化时,简单平均SGD寻优轨迹上的多个点,比常规训练取得更好的泛化能力。我们还表明,这种随机加权平均(Stochastic Weight Averaging, SWA )方法比SGD方法具有更宽的优化范围(broader optima),并且与最近提出的单模型Fast Geometric Ensembling( FGE )方法近似。使用SWA,我们在CIFAR - 10、CIFAR - 100和ImageNet上的一系列最优的Residual Network、PyramidNets、DenseNets和Shake-Shake network上的测试精度比常规SGD训练有显著提高。总之,SWA非常容易实现,明显提高了泛化能力,并且几乎没有计算开销。
A Survey of Deep Learning Techniques for Mobile Robot Applications
摘要:近年来,深度学习的发展吸引了人们对深度人工神经网络如何应用于机器人系统的研究。本综述将对当前的研究成果进行总结,重点介绍移动机器人在深度学习方面取得的成果和存在的问题。
Attention on Attention: Architectures for Visual Question Answering (VQA)
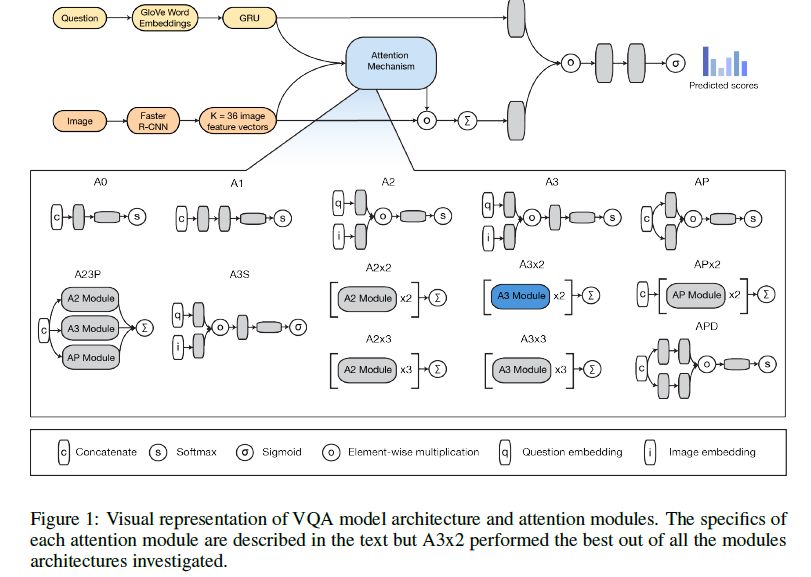
摘要:视觉问答(Visual Question Answering, VQA )是深度学习研究领域中一个越来越热门的话题,需要将自然语言处理和计算机视觉技术协调成一个统一的体系结构。通过开发13种新的注意机制并引入一个简化的分类器,我们构建了一个用于解决VQA问题的第一个深度学习模型。我们进行了300个GPU小时的大规模超参数和体系结构搜索,取得了64.78 %的评估分数,优于现有最先进的单模型63.15 %的验证分数。
Gradient Descent Quantizes ReLU Network Features
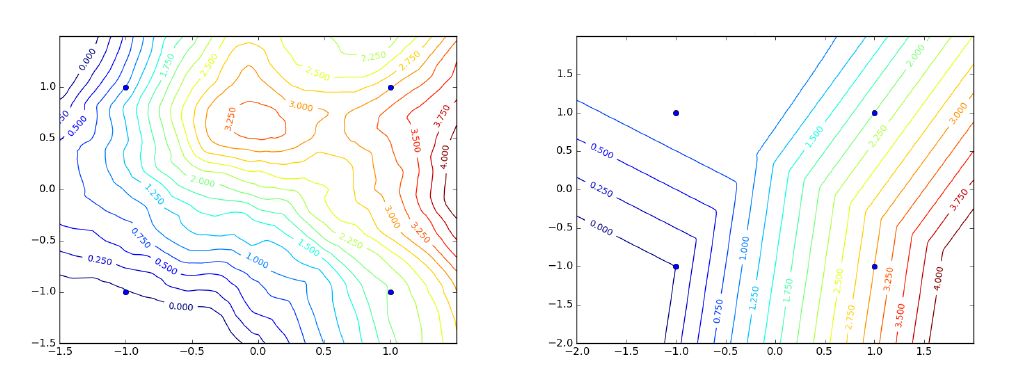
摘要:深度神经网络通常在过参数化(Over-parametrized)的状态下训练时(即,训练样本个数少于参数个数),为什么训练收敛于一个泛化的解仍然是一个亟待解决的问题。一些研究结果指出,在训练过程,小批量随机梯度下降( SGD )容易导致参数寻优收敛于具有特定性质的局部最优值。然而,即使在采用二维的平面梯度下降( GD )的情况下,在过参数化区域(over-parametrized regime)中寻优得到解也相当好,并且这种现象很难理解。
本文假设采用很小初始值和学习率,分析具有ReLU激活函数的前馈网络的这种行为,揭示了一种量化效应:权值向量趋于收敛于由输入数据确定的少量方向上。结果表明,对于给定的输入数据,可以获得的“简单”函数数量很有限,与网络规模无关。这使得这些函数类似于线性插值(对于给定的输入数据,存在有限数量的triangulation,每个triangulation通过线性插值来确定函数)。我们也在思考是否这种类比可以扩展到一般性质,虽然通常与分布无关的泛化性质不成立,但是对于例如具有有界二阶导数的平滑函数,近似性质(Approximation property)成立,其可以“解释”网络(无界大小)到不可见输入的泛化。
Group Normalization

摘要:Batch Normalization( BN )是深度学习发展中的一项里程碑似的技术,使各种网络能够快速进行训练。然而,根据Batch的大小进行归一化也引入了一些问题,即当Batch Size变小时,由于不准确的batch sampling导致BN的估计误差迅速增大。这限制了BN用于训练较大模型和将特征转移到计算机视觉任务(包括检测、分割和视频)的使用,这些任务由于受内存大小的限制,智能使用较小的batch size。本文提出了一种简单的Group Normalization(GN),可以看做BN的简单的变体。GN将channels分成组,并在每个组内计算归一化的均值和方差。GN的计算与batch size无关,在大批量范围内精度稳定。在ImageNet训练的ResNet-50上,当Batch size为2时,GN的误差比BN低10.6 %;当使用典型batch size时,GN与BN的性能相当好,并且优于其他Normalization的方法。此外,GN可以自然地从预训练转移到微调。GN在COCO比赛的目标检测和分割以及动力学视频分类方面均优于基于BN的同类算法,表明GN能够有效地替代BN。GN在现有的深度学习库中只需几行代码就可以实现。
往期精彩内容推荐
<纯干货-4> 加州伯克利大学2017年最新深度强化学习视频课程_part1
<深度学习优化策略-4> 基于Gate Mechanism的激活单元GTU、GLU
<纯干货-3>Deep Mind Reinforcement learning course Lecture 1_2
<模型汇总-6>堆叠自动编码器Stacked_AutoEncoder-SAE
<深度学习优化策略-1>Batch Normalization(BN)



DeepLearning_NLP


深度学习与NLP
商务合作请联系微信号:lqfarmerlq



