干货 | 张宇伦:基于残差密集网络的图像超分辨率(CVPR 2018 亮点论文)

AI 研习社按:图像超分辨率技术作为底层计算机视觉任务,有着广泛的应用场景,比如:手机图像增强,视频监控,医疗影像,卫星图像,低分辨率人脸识别。因此,图像超分辨率技术吸引了众多来自学术界与工业界的研究兴趣。但是,当前图像超分辨率技术仍然面临一些难题,比如,对高放大倍数的图像超分辨,难以恢复丢失的细节;对已经恢复出的细节,也有着模糊等效应,其质量有待提升。
近期,在 GAIR 大讲堂上,美国东北大学计算机工程在读博士张宇伦本次公开课,张宇伦同学设计一种新的网络结构,得到更强的表达能力,不仅将之前方法难以恢复的细节恢复出来了,而且,结果更清晰。最终,在不同图像退化模型下都达到了当前较好的结果。公开课视频回放链接:
张宇伦,美国东北大学计算机工程在读博士,西安电子科技大学智能科学与技术专业学士,清华大学自动化系硕士。主要研究方向为计算机视觉,机器学习,具体包括图像复原,生成,风格转换等。目前作为深度学习研究实习生在美国 Adobe 公司实习。
分享题目:基于残差密集网络的图像超分辨率
分享提纲
1. 图像超分辨率问题,相关工作,难点。
2. 残差密集网络。残差密集块,连续记忆机制,局部与全局残差学习,局部与全局自适应特征融合。
3. 实验结果。实验设置,网络结构参数分析,网络模块分析,不同退化模型下的对比,性能与运行时间比较,训练数据对网络性能的影响。
4. 总结及展望。
AI 科技评论将其分享内容整理如下:

大家晚上好,我叫张宇伦,来自美国东北大学的一年级博士,今天想跟大家分享我们在 2018 年 CVPR 的一个工作:基于残差密集网络的图像超分辨率,这个工作是跟我的合作者们一起完成的。

现在直接讲超分辨率问题,这个问题看起来比较简单:在把小图变成大图的过程中,我们要尽量地把一些损失的细节恢复出来,比如上面 Biubic 的图,它就是你平常在电脑上你用鼠标的滑轮把它放大后的效果(鼠标滑轮放大的效果可能还会比它更差),右边这个 RDN 方法是我们最近提出来的,当然可能会有很多的一些方法,大概就是这样一个问题。
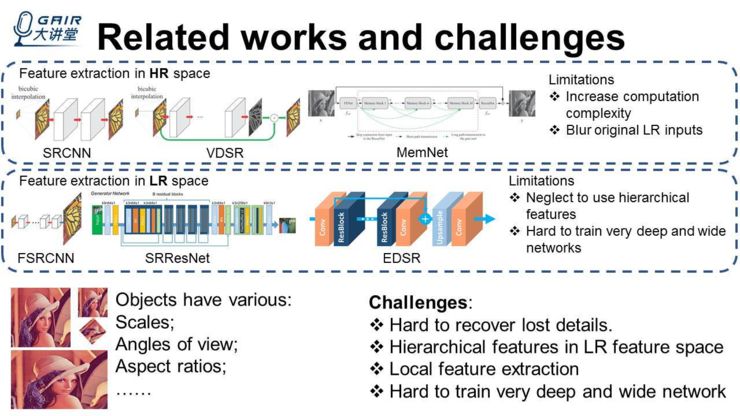
下面就是一些相关的工作以及这个领域的一些挑战,基于深度学习的超分辨率最早可以追溯到 2014 年的 ECCV,由港中文的多媒体实验室的董超博士等人提出的 SRCNN,当时那个网络只有 3 层,而且最开始的时候,给网络输入图像的时候,还把小图直接先放大了一遍,后面是有人尝试把那个层给加深,但一直都很难,直到 CVPR2016 年,有人提出 VDSR,然后才通过加入残差学习,才把网络的层数由 3 层加到了 20 层左右。
后面是 ICCV2017 年,有人进一步用 dense connection 把网络提升至 80、90 层,甚至到 200 层,然后其效果也进一步提升了。但是这些方法有一些缺陷,比如说最开始的时候把图像放大,就会大大增加它的计算复杂度和显存消耗,同时最开始放大的时候,它会把原始的低分辨率的图模糊化,导致后面你怎么恢复都是在一个相对较差的图像上进行恢复,所以不太好。第二种是从低分辨率的空间去提取特征,然后,在网络的后面去进行放大处理,我认为这个工作最开始是 SRCNN 的作者董超博士等人在 ECCV2016 年发表的 FSRCNN,在这个里面他们的网络层数是差不多的,大概是 5 层左右,但是他们把放大的层放在最后一层,这样的话,它网络的主要计算量全部是在低分辨率空间里计算的,所以能够大大的降低它的计算复杂度。
然后沿着这个方向走,大概在 CVPR2017 年的时候,SRResNet 当时把网络弄到了 34 层的样子。CVPR2017 年的超分辨竞赛第一名,EDSR,他们当时把网络弄到了 160 层,当然,他们也可以把网络弄得特别宽,比如它的通道数能够达到 256,当然这些方法它们的一些缺点是忽视了去使用一些 hierarchical 的特征。另外,想训练一个非常深或非常宽的网络是有难度的。另外,在现实生活中,我们图片中的物体有不同的 scale、视角以及纵横比。所以这个领域的难点在于,很难把一些损失的细节恢复出来,另外大家很少研究怎么在低分辨率特征空间中,去充分挖掘这些 hierarchical 的 feature,以及局部的一些特征提取,另外就是如何训练一个非常宽、以及非常深的一个网络,这很难做到。
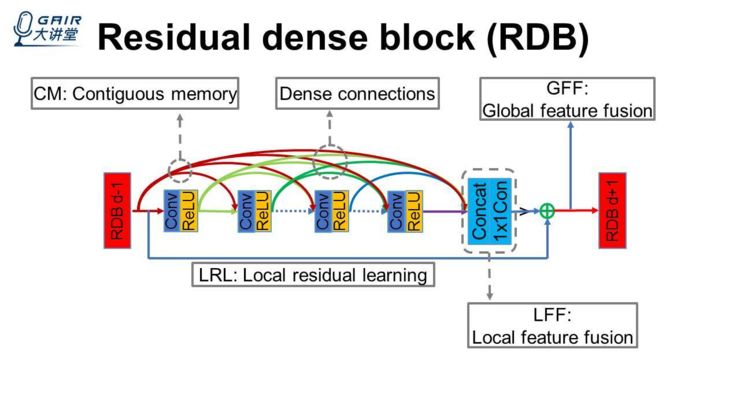
然后基于这样的一些发现和难点,我们在工作中提出了一个 Residual dense block(RDB)作为基本的一个网络单元,比如在一个 block 里面会有一些卷积层,我们的卷积层里面会用一些 dense connection 方式,让这些层之间的特征能够尽量地被利用到,我们把这些 connection 称为 dense connections。
另外,我们提出 Contiguous memory 的一种机制,就是能把上一个 block 的所有信息,全部输入到当前 block 的每一个卷积层里面去。但是这样全部加进来的时候,越往后的话,它的特征数就特别多,不可否认的是,这些信息会有一些冗余。所以要提出一个局部特征的融合,来把一个 block 里面最后面很多更有效的特征进行融合提取。但是这个过程中存在一个问题:当你的 block 比较长,以及这些 connection 之间的特征数比较多的时候,它很难训练起来。所以我们进一步提出一个残差学习(也是借鉴残差网络而来的、很简单的),我们整个 block 的输出,不仅是输出到下一个 block 里面去,同时也会输入到一个叫全局特征融合的模块里面去,就是让我们的网络最终能够得到 deep hierarchical 的 feature,我们基于这样的一些 block,来构造一个网络,输入是一个低分辨率的图,我们用少部分卷积(如两层卷积)进行一些低层次的特征提取,低层次的特征输入到一些 block 里面去,这些 block 同时会把特征输出到全局特征融合里面去。为了让我们整个网络能够比较深、能够训练起来,这里还需要一个 long skip connection,我们把它称作 global residual learning。
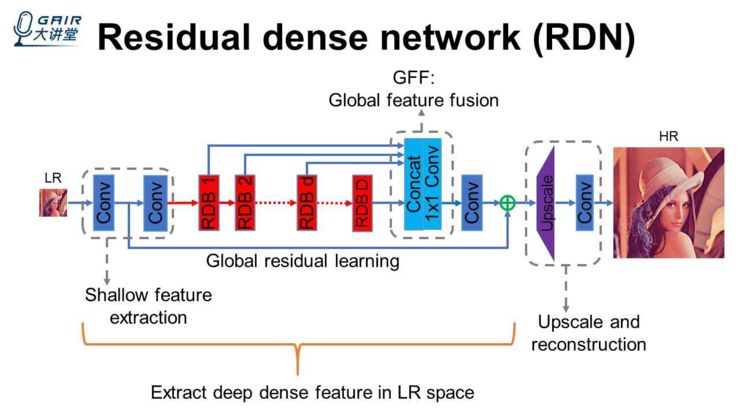
这样的话,就能让 block 的数量变多,同时性能也不会下降。一般来讲,性能会上升一些,在网络的后端,对特征的空间层进行一个放大,同时进行一个重构,得到一个高分辨率的图,然后这些高分辨率的图去跟 ground truth 计算一个 loss,进行整个网络的参数更新。所以,我们可以看到网络的整个主体是在低分辨率空间去进行的,然后经过 block 里面局部的特征提取,以及网络后端的全局特征融合,这样一个网络就能够在低分辨率空间里面提取到 deep dense feature。
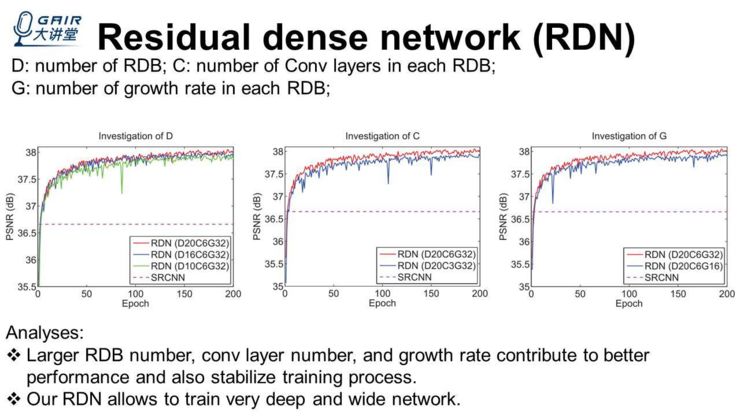
当我们提出一个网络模型的时候,会对其中的一些参数进行一些探索,再去确定我们最终网络要使用的参数,这里比较关键的一些参数:D:Residual dense block 的数量;C:C 就是每个 block 里面卷积层的数量;G:growth rate,每一个 block 里面的卷积层送到下一个卷积层的特征的数量。
看上面三个图,图(1)探究 D,我们设置了 3 个不同的 D:10、16、20,其它设置均一致。会发现它的 PSNR 的曲线确实是不一样的,可以明显看到 D 越大的时候,它的线明显越好。
图(2)探究 C,分别取了 3 和 6,其他参数是一样的,也可以看出红线和蓝线,红线里面 block 里面的卷积层数量多一些,所以整个网络的能力也提高了。
图(3)探究 growth rate,也是控制变量,其他的两个 D 和 C 全都不变,G 由 16 变到 32,然后看到这个曲线也都提高了。所以,我们分析 block 数量,卷积层数量以及 growth rate 数量,它们的增大,都能对网络的性能有正面的影响,还能进一步稳定我们的训练过程,由此,可以看出我们提出的这个网络能够训练非常深和非常宽的网络。

下面直接讲实验设置,我们使用的训练集是 DIV2K,这个是 CVPR2017 年 NTIRE 超分辨竞赛用到的,在后面的大部分顶会中大家都会采用这样一个数据集,同时还有一个 Flickr2K 的训练集,CVPR2018 也有人用。我们的方法如果在这两个数据集中训练的话,结果会更好,后面会给出结果。在测试集上,我们使用了 5 个当前非常通用的测试数据集,对于退化模型采用了 3 种退化模型:BD、DN、BI。
BD:先把图像模糊化,再将它降采样,我们这里使用的模糊和是高斯模糊核。
DN:先降采样,再给它加一些高斯噪声,高斯噪声水平:30。
BI:最经典的 bicubic 的降采样,我们这里探究了(x2,3,4,8)4 个倍数,对比的方法也都是最近两三年的一些 CVPR、ICCV、ECCV 的一些方法,为了保持公平对比,训练的一些 setting 都是和 EDSR 一样。
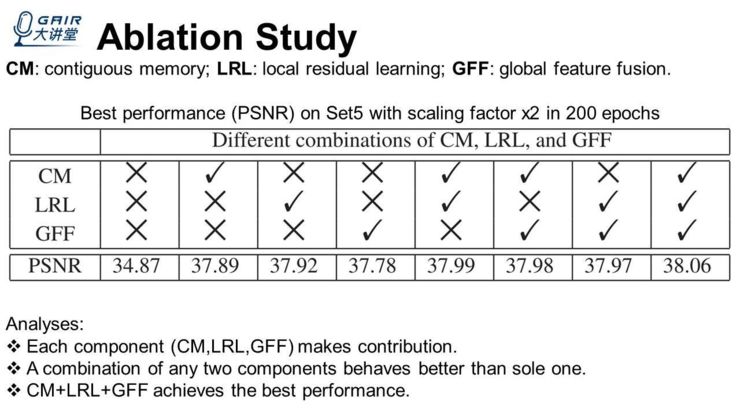
实验过程中,首先要进行的是 Ablation Study,因为要向读者去展示你的贡献点确实都有用,并且缺了任何一个,都会在结果或性能上受到一些损失。例如上表里,我们把 contiguous memory,local residual learning,global feature fusion 放到里面去,最左边的一列全部都是 x,如果全部都不使用的话,它的性能最低。
后面依次的三个列,只要其中的任何一项被使用,它的性能都会有很显著的提升;接下来的三个列,我再任意地加一个项,它又会得到提升;最后一列,我们把三个 item 全部都用上,能够达到最好的结果。
所以得到的结论就是,这些贡献点(component)都有用,任意两个 component 比单独用一个都要好,三个同时用能够得到最好的结果,这是 Ablation Study 的一个部分。
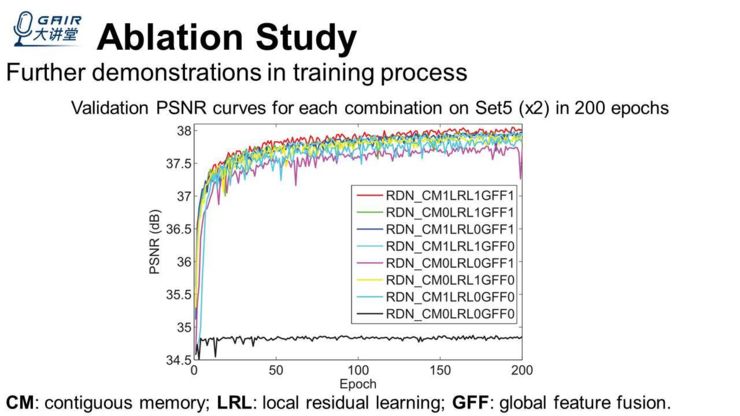
我们也在论文中展示了,我们把整个训练过程中 Ablation Study 的性能画成了曲线,我们发现,在训练的过程中,这些 item 全都用上(比不用或者少用都要好),例如上图中最上面的红色曲线,就是将 item 全部用上了,所以它在整个训练过程中性能都是最高的。
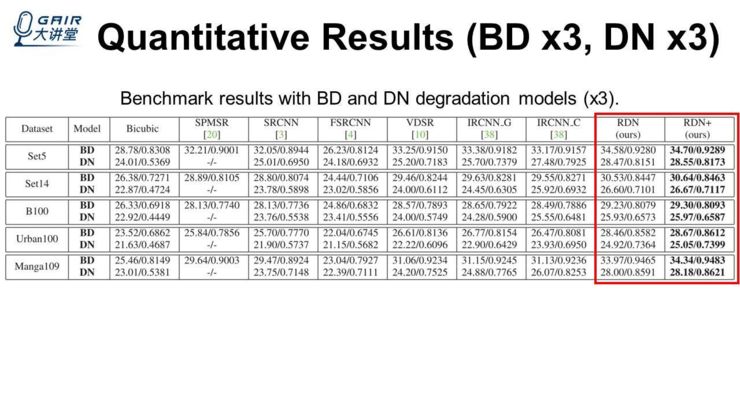
然后就是数值结果,比如在 BD、DN 上,我们的放大倍数都是 3,最后两列是我们的方法,对比的方法包括 CVPR2016 年的 VDSR、CVPR2017 的 IRCNN。我们发现在 BD 和 DN 两个退化模型以及 set5、set4、B100、Urban100、Manga109 这些数据集上,RDN 得到最好的结果,以及我们的模型在小图受到模糊或者噪声干扰的情况下,也能达到比较好的结果。
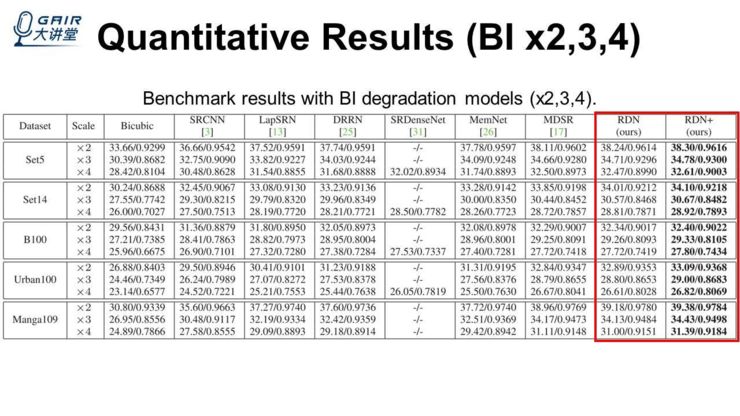
另外一个,就是在经典的 bicubic 的退化模型中,这里我们放出了 2、3、4 倍的一个结果,对比的方法有 CVPR2017、ICCV2017、CVPR2016 的方法,也发现我们在 2、3、4 倍的数据集上的结果也最好。

实验部分是 4 对结果,我们就把它的局部截出来,进行各个方法的对比。original(表示 ground truth,原图)、后面依次是 Bicubic、SPMSR、SRCNN、IRCNN_G,最后一列是我们的方法,因为这里是 BD、这些低分辨率的图是模糊化的,我们可以发现以前的其它一些方法,对处理模糊方面还有很大的提升空间,会发现我们的方法对这些模糊的效应抑制地比较好,得到的结果更接近原图。
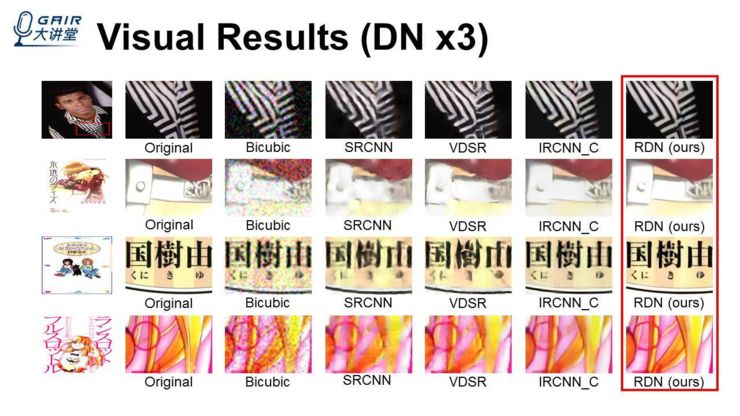
上面是 DNx3,DN 的退化模型 x3 的一个结果,我们输入的图都被加了噪声,对比的方法当然还有 VDSR 和 IRCNN,发现对比的这些方法,在去燥以及放大的过程中,会有一些细节恢复不出来,甚至会出现一些扭曲的情况,例如 VDSR、SRCNN,我们的结果得到的边缘更加清晰、锐利,细节更多一点。
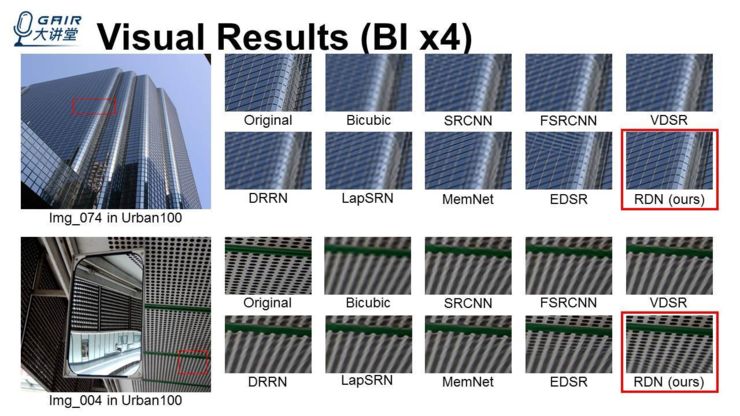
后面是在 bicubic 下我们的结果,这里我们对比的结果就更多一点,因为这是一个最经典、最常用的退化模型,我们对比了一些 EDSR、CVPR2017 的 LapSRN、DRRN、CVPR2016 的 VDSR,我们也能发现,比如上面的这栋建筑的玻璃,很多其它的方法得到的结果都不太好,但我们的方法得到的结果就锐利一些。
下面这个有网格的图,很多以前的方法基本上不能把很多小的洞恢复出来,像 EDSR 恢复了一部分,但是剩下的一部分难以恢复。而我们的方法把它给恢复出来了。值得一提,我们的参数量比 EDSR 少很多,后面会给一个表,列出参数量的对比。这里又是 bicubic 上面呈现的一些结果,比如上面这一张图,很多其它的方法把(一些线条和很多细节)恢复错了,而我们的方法能够更加正确、清晰地恢复出来。另一张图也有这样的问题:像 EDSR 这种恢复了一部分、另一部分难以恢复出来。

我们还放了 bicubic 在 8 倍放大下的一些结果,可以看到 x8 倍本身就比较难,我们的方法把细节恢复地比较多,当然还是不太好。
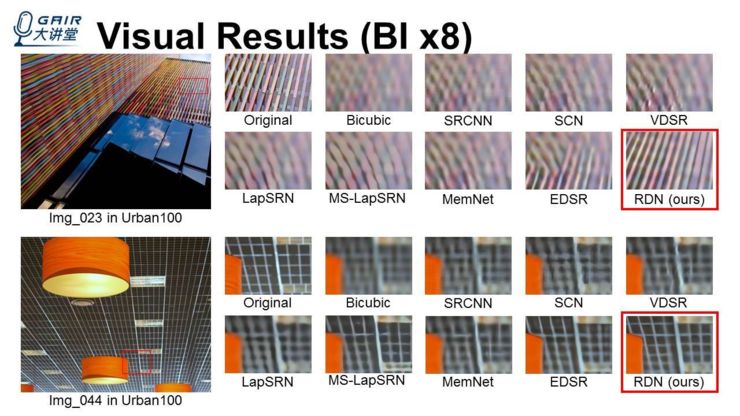
这里是其他的一些例子,也能够看出区别。这些结果,我们后面会扩成一个期刊呈现出来。
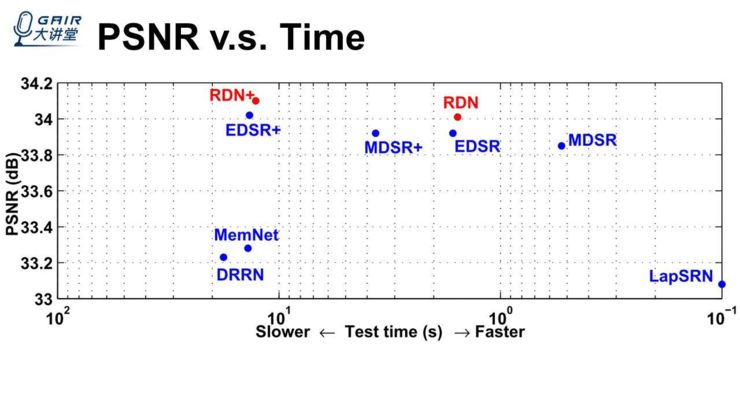
另外,性能和测试时间的一个对比,我们发现 RDN 的参数量不算太多(比 EDSR 还要少一些),但它的性能更高一些。这里是指 PSNR 和运行时间,运行时间跟 EDSR 差不太多,但是比其他的一些方法(MemNet、DRRN、EDSR+、MSDR+)的运行时间要少一些。
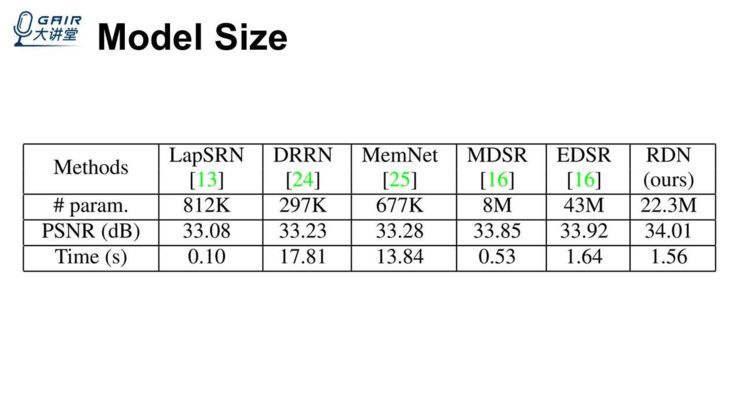
将我们的方法跟当前最好的一些方法在模型、运行时间上做了一些对比,发现我们的参数量大概是 EDSR 的一半,我们还能得到更好的结果,同时与它的运行时间差不太多,比它低一点点。
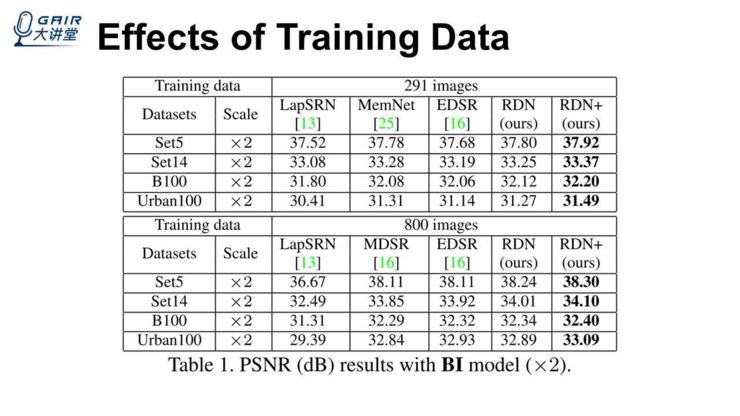
还想跟大家说一下,我们的训练数据对整个网络的影响,比如在这张表中,上面是用 291 张图去训练这个网络,下面是 800 张图来训练我们的网络以及其他的一些方法。整个表的上下对比,我们会发现,当我们的数据量更多的时候,其实我们的网络能够得到更好的结果。在表格的上下部分,这些方法之间的对比,我们会发现,在使用同样多的训练数据的情况下,我们的方法能够得到更好的结果,这也从一个方面说明我们的方法确实比之前的那些方法更有效一些。
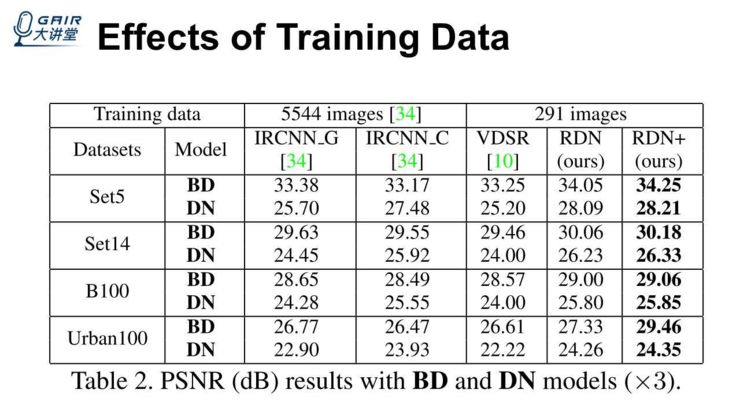
刚才是在 bicubic 上面做的实验,这里是在 BD、DN 退化模型上做的实验,比如说 CVPR2017 年的 IRCNN,是在 5000 多张图片上训练,这里我们仍然用 291 张图训练,会发现在这两个退化模型上面,即使 IRCNN 使用了更多的数据集,我们的结果也比它好,这里就进一步说明,即使我们使用更少的数据集,因为网络设计考虑的因素更加多,更加合理一些,所以我们得到的结果也会更好一点。
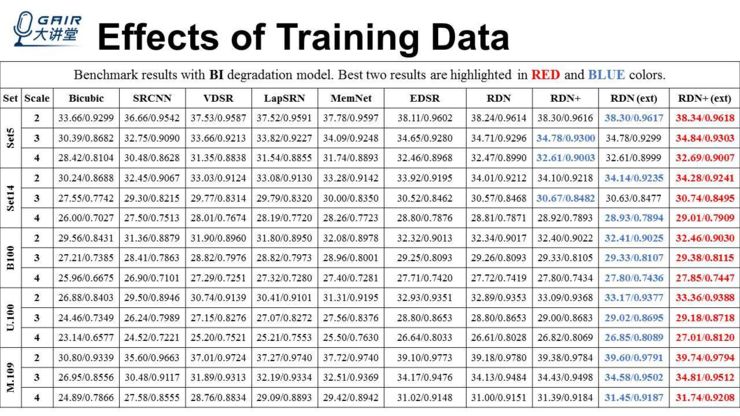
下面这个图是我们在 DIV2K 和最后两列是我们在 DIV2K+Flickr2K 的数据集上面,重新训练我们的网络得到的结果,会发现结果比我们之前在论文里面的结果更好,且会好很多,基本上,我们不使用 self-ensemble 比之前使用 self-ensemble 的结果更好一些。
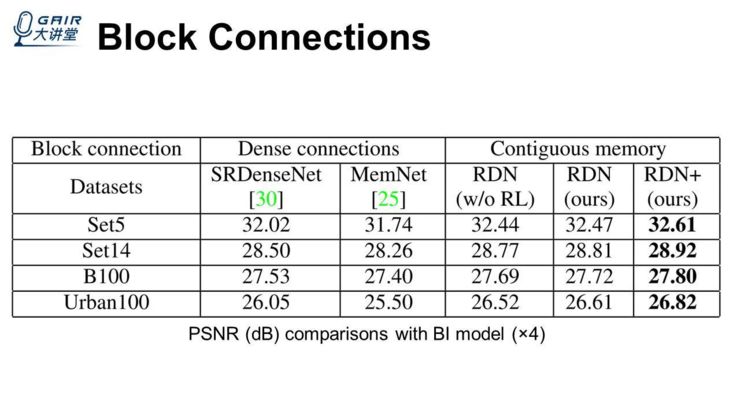
另外一个是 block connections,因为像 ICCV2017 年的 MemNet 一样,block 之间会有 dense connections,我们里面使用的其实是 contiguous memory。这里,我们也对比了一些像 ICCV2017 年的两篇文章,它们的 block 之间都使用 dense connections,我们没有使用,同时还把 RL 也去掉了。我们会发现,在这几个公共数据集上面,这几种情况都比之前使用 dense connections 那种方式得到的结果都要更好。

我们的结论:
我们的网络能够同时达到很深、很宽,去进行高质量的图像超分辨。
residual dense block 里面的这些 dense connection,能够让我们的局部 feature 得到充分的利用,同时在 block 里面的局部特征融合与局部残差学习,不仅能够稳定我们的网络训练,对于更高的 growth rate 也能自适应地去控制当前以及之前 block 里面输出的信息。
另外,RDB 能够让之前的 block 里面的卷积层,跟我们当前的每一个卷积层都有直接的 connection,有 contiguous memory 的一种机制。
局部残差学习能够进一步去改善我们整个网络的信息以及梯度的流动,配合使用上全局的特征融合,我们能够在低分辨率空间中去提取到 hierarchical 的 feature,从而得到更好的结果。通过使用局部以及全局的特征来,我们的网络能够得到 dense 的一些 feature,从而也能够得到更好的结果。

对于一些网络也能应用到其它的一些任务上,比如图像去燥、以及一些压轴增强、inpainting、去马赛克。这项工作的源代码已经共享在 https://github.com/yulunzhang/RDN
想了解更多 AI 研习社直播?
欢迎点击“阅读原文”
或者移步 AI 研习社社区~



