[深度学习] AlexNet,GoogLeNet,VGG,ResNet简化版
总结了一下这几个网络的比较重要的点,像这些经典的网络,面试的时候,估计会经常问到,怎么用自己的话说出来?不知道大家想过没有。 今天有空就总结了一下,尽量简单和通俗,希望对大家有帮助。同时欢迎大家补充!谢谢!
AlexNet
AlexNet共有9层,包括输入层,5个卷积层和3个全连接层,中间使用了3次最大值池化。卷积核的大小由11x11到5x5再到3x3, 最后输出层是1000维的SoftMax多分类。第2,4,5和三个全连接层神经元的偏置初始化为常数1,其它层初始化为0。为了避免过拟合,AlexNet使用数据增强和Dropout两种方法。数据增强是在原始图像上随机采样得到更多的数据,Dropout是每次随机断开部分神经元来实现的。激活函数用的是Relu,可以加速模型收敛,Relu可以避免梯度消失或者梯度爆炸。
GoogLeNet
GoogLeNet最大的贡献就是提出了Inception结构,其主要特点是采用不同大小的卷积核得到不同大小的感受野,然后把他们在拼接起来,这样就得到了不同尺度的特征融合。还有一个特点是网络开始的时候1x1卷积核较多随着网络深度的增加,3x3和5x5大小的卷积变多,这样做的原因是随着网络的增加,特征也越来越抽象,每个特征表示的感受野也越来越大,所以需要更大的卷积核。
后来又提出了Inception V2,相对于V1的改进的地方是将原来5x5的卷积核变为两个3x3卷积核序列来代替大的卷积核,最终确定的方法是用nx1的卷积核序列代替原来nxn卷积核。在15年的那篇论文中,n最终确定为7.
VGG
vgg是14年和GoogLeNet同时提出的,获得分类任务的第二名。其主要贡献是通过减小卷积核大小然后增加网络深度可以提高模型分类效果,而且VGG具有很好的泛化能力。
超参数设置:
使用了3x3和1x1大小的卷积核,1x1卷积核可以看做是对通道的一种线性变换。优化方法和AlexNet一样,都是含有动量的随机梯度下降算法,正则化使用L2正则,Dropout在全连接层的前两层,p=0.5。更小的卷积核和更深的网络,相当于隐式的正则化。和AlexNet相比较,VGG每层的卷积不止1个,一般是2-4个卷积。vgg对输入图像做了crop,batch size 是256, momentum是0.9,weight decay是5*10^-4,学习率是初始化为0.01,当验证集准确率不再上升的时候,学习率减少为原来的1/10。
ResNet
ResNet指出随着网络深度的增加,在训练集和测试集的误差都在增加,也就是网络的学习能力“退化”了,为了解决这个问题,提出了一种深度残差学习的框架,其目的是为了便于优化算法的使用,加速模型收敛。3.75%top-5错误率。作者先用了一个18层和一个34层的测试网络,发现采用残差块可以避免模型退化,然后实验了50层,101层,152层的ResNet,错误率降低的同时,计算复杂度并没有增加。
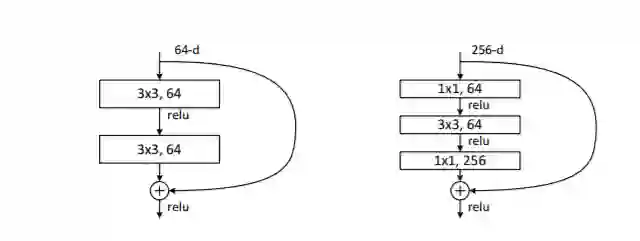
这个图的左图是34层ResNet使用的残差块,右图是50,101,152层残差块使用的,区别很明显了。
H(x) = F(x) + x
目的是降低优化难度。
