论文浅尝 | Question Answering over Freebase

Dong,L., Wei, F., Zhou, M., & Xu, K. (2015). Question Answering over Freebasewith Multi-Column Convolutional Neural Networks. Meeting of the Association forComputational Linguistics and the, International Joint Conference on NaturalLanguage Processing (pp.260-269).
动机
基于知识图谱的问答系统(KBQA),旨在利用知识图谱覆盖领域内的三元组,来回答一些事实性问题。处理 KBQA 问题,其关键在于两个方面:实体识别/链接,关系映射。其中,最重要的工作是关系映射,即将问题中的关系模式(relation pattern),或称谓词指称,映射为知识图谱中连接实体的关系。为了解决这个问题,传统的方法为使用模板。对于训练语料中覆盖的模板,固然可以精确地从模板映射到某个关系。但是模板覆盖的范围有限,而且需要大量的人为标注和模板统计工作,会耗费大量的人力。对于模板没有覆盖的问题,就有很大的概率无法正确回答。为了解决这个问题,本文引入了卷积神经网络,旨在建立一个端到端的问答系统,将自然语言问句与知识图谱映射到同一个向量空间,从语义上理解问题,而非通过规则的堆砌来解决 KBQA 问题。
本文为了引入更丰富的信息,从三个角度:答案路径、答案上下文、答案类型对候选实体进行理解,并尽量从问题中找到与候选实体近似的语义,从而推测出正确的答案实体。
贡献
文章的贡献有:
(1)设计了基于 CNN 的端到端语义模型,解决 KBQA 问题;
(2)同时训练自然语言问句词向量与知识图谱三元组,将问题与知识图谱映射到同一个语义空间;
(3)从三个方面考察候选实体与候选实体的上下文,而不是从问句去进行谓词映射,从一个新颖的角度处理 KBQA 问题。
(4)实验效果表面,本文提出的方法是 state-of-the-art 的。
方法
本文从三个角度来理解问题,试图找到最可能的候选答案。该文主要聚焦于三个方面:答案路径(answer path)、答案上下文(answer context)和答案类型(answer type)来分析问题和答案的相似度。每一个方面都对应一个训练好的卷积网络,以此来回答问题。这三个 CNN 被称为多列卷积神经网络(Multi-Column convolutional neural network,MCCNNs)。
该模型的主要设计框架如下:首先利用命名实体识别、实体链接等技术,从自然语言问句中找到KB中对应的实体,然后将该实体连接的每个实体,都视为一个候选答案实体。找到候选答案实体后,对候选答案实体从答案路径、答案上下文、答案类型进行向量的映射。具体映射方式为将相关实体或属性对应的向量进行累加(如构成答案路径的属性边的向量累加),从而形成三个向量:g_1(a),g_2(a), g_3(a)。同时,利用三个 CNN 分别对问句从三个方面(答案路径、答案上下文、答案类型)进行卷积,得到三个向量:f_1(a),f_2(a), f_3(a)。有这些向量,最终可以对问题-候选答案进行评分,评分公式为:
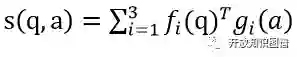
根据计算结果得到最高分的就是问题答案。
下面对方法细节进行阐述。
首先,是找到候选答案实体。模型中,识别出来的实体,在一定范围内相连的其他实体(经过一跳或两跳),都视为候选实体,形成一个候选实体集合 c_q。
其次,是对自然语言问句的卷积计算。如图1所示,每一个 CNN,首先对问题中所有的词赋予一个预训练好的初始词向量,并根据上下文窗口(窗口大小为5)进行拼接;再经过卷积计算、最大池化得到定维的向量。最后将这三个向量与候选问题映射的三个向量进行加权求和,得到最后的问题-候选答案打分。三个 CNN 的输入都是单词向量,而不同的是每个网络的参数不同,得到的向量也不同。此外,需要注意的是,在 MCCNN 中,词向量也是待学习的参数,也就是说,每次的 loss 反向传播都会更新词向量。
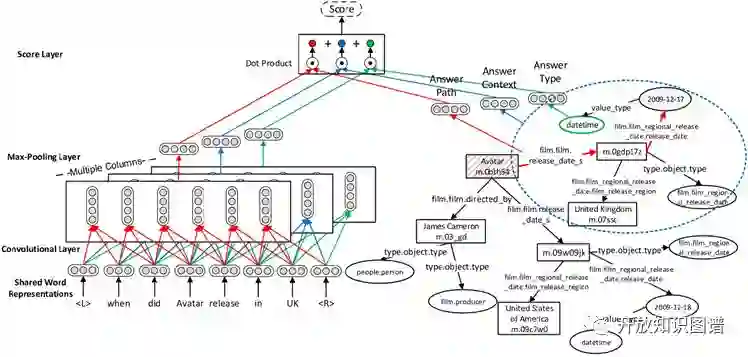
图1 MCCNNs框架图
再次,是对候选答案的向量映射。模型将 KB 中所有的实体、关系和答案类型都映射为事先初始化的向量,并组成一个知识图谱向量矩阵,每个实体和关系都可以从矩阵中找到对应向量,而这个矩阵的参数也在训练中被更新。如同词向量一样,训练完成后,知识图谱的实体与关系映射的向量也得到相应的更新。
对于答案路径的映射,首先是找到路径。在模型中,问题中的实体与答案实体之间相连的关系(一跳或两跳),即为路径。如图 1 所示,实体“Avatar”与答案实体“2009-12-17”之间由“release_date_s”和“cate_release_date”这两个关系相连,这两个关系就组成路径。路径对向量的映射,就是在知识图谱向量矩阵中找到关系对应的向量,并求平均值。
对于答案上下文的映射,就是在与问题路径相关的一跳实体和关系,都视为答案上下文。如图1中所示,“release_date_s”、“m.0gdp17z”、“cate_release_date”形成了一个答案路径,那么与这三个元素相连的单跳实体或关系就是上下文。上下文对向量的映射,也是找到这些元素对应的向量求平均值。
对于答案类型的映射,即对于候选答案实体,确定其答案类型,并从知识图谱向量矩阵中找到映射的向量。比如图1中,“2009-12-17”的答案类型为“datetime”,而“JamesCameron”的答案类型为“person”和“film.producer”。映射方法也是求平均值。
由此,问题的三个向量和候选答案的三个向量,就已经得到,进行点积计算并求和后,就得到最终评分。
最后进行训练。损失函数为
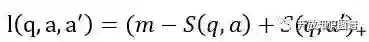
其中m为margin,S(q,a) 为问题-正确答案对的相似度,S(q,a`) 为问题-随机答案对的相似度。随机答案是从候选答案集 c_q 中随机抽取的答案,视为负例。目标函数是使该损失函数最小:
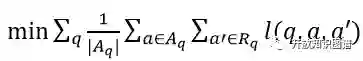
|A_q|是一个问题的正确答案数量,R_q 是随机答案集合。模型使用反向传播来训练,并使用 AdaGrad 来解决非凸函数问题,并且使用了 max-norm regularization技术。此外,由于 WIKIANSWERS 有平行问题,所以采用平行问题来额外训练模型,即平行问题(paraphrased questions)应该经过卷积后有类似的向量。所以将平行问题作为正例,随机抽取的非平行问题作为负例,设置 margin 损失函数,并最小化损失函数为目标进行模型训练,而训练过程如前所述。
实验
从图 2 所示的表格可以见到,当前系统的方法,比使用传统 semantic parser(即模板)和使用粗放词向量相加来表示问题的 Bordes 方法,有了显著提高。
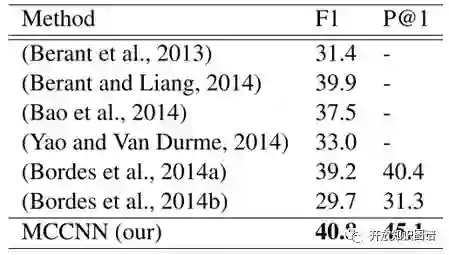
图2 问答系统实验效果比较
另外,从图3可见,从多列模型中,去除 path 网络(w/o path),实验效果下降最多,可知道 path 对问题理解最为重要;而如果只使用一种方法来理解问题(w/o multi-column),比从多个维度理解问题,效果差很多;另外,平行问题(w/oparaphrase)的训练也提高了实验效果。

图3 实验方法效果比较
除此之外,这篇文章中还做了两个有趣的实验。
其一是寻找句子中的显著词。所谓显著词,就是如果将该词用一个停用词(of/a/is/to)来替代,句子的语义变化最大(卷积出来的向量与原始句子的向量做欧氏距离计算,值为最大),那么这个词就是显著词。

图4 显著词实验
如上图 4 所示,柱状条代表该词的显著程度(即前述计算出来的欧氏距离)。可见 wh-疑问词(如what、who、where)、与疑问词相连的名词或动词(如type、speak)是最为显著的,也就是说,这些词最能体现出问句的语义,是重要的关键词。
其二是通过卷积出来的向量,从三个维度去观察,是否真的相似,即通过三个维度考察的句子,是否真的有聚类效应。
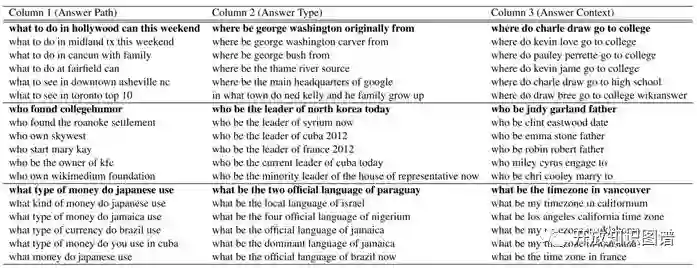
图 5 句子聚类实验
如上图 5 所示,每一列都代表,通过答案路径、答案类型、答案上下文的映射向量,所找到的最相近向量所对应的句子。从这三列可以看到,基本都能将最相近的答案路径、答案类型、答案上下文的问句找到,即可以通过模型训练出来的问句卷积神经网络,找到语义最相似的句子。
这篇文章,作者从三个角度去理解问题和候选答案,并找到最佳预测答案,这样可以更加精细地理解问题语义,准确地找到答案,并且可以附加训练出词向量词典和知识图谱向量词典。当然,如果实体链接没有正确找到实体,或者遇到时间判断的问题(谁是**的第二任妻子),或者问题问得很模糊(**是谁,是问这个人的身份,还是这个人的职位?),模型处理效果都不佳,这些都需要以后去解决。此外,大量的参数(词向量、知识图谱、三个卷积神经网络)都是训练生成,那么训练的调参就非常重要,找到最佳参数相对更加困难,训练时间也更长,这些都是有可能妨碍模型效果的问题,需要在实践中积累经验。
论文笔记整理:花云程,东南大学博士,研究方向为自然语言处理、深度学习、问答系统。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。





