论文浅尝 - ICML2020 | 拆解元学习:理解 Few-Shots 任务中的特征表示
论文笔记整理:申时荣,东南大学博士生。

来源:ICML2020
链接:http://arxiv.org/abs/2002.06753
元学习算法会生成特征提取器,这些特征提取器在进行few-shot分类时就可以达到最新的性能。尽管文献中有大量的元学习方法,但对于为什么生成的特征提取器表现如此出色的原因知之甚少。本文对元学习的基本机制以及使用元学习训练的模型与经典训练的模型之间的差异有了更好的了解。在此过程中,本文针对元学习模型为何表现更好而提出了一些假设。除了可视化之外,本文还根据假设设计了一些正则化器,这些正则化器可改善几次快照分类的性能。
1.元学习
元学习算法的目的是产生一个网络,该网络可以使用很少的数据快速适应新的类别。具体来说,元学习算法会找到可以在几个优化步骤和几个数据点上进行微调的参数,以实现对任务Ti的良好概括,该任务Ti由来自分布和标签空间的少量数据样本组成在训练期间没有被看见。如果在看到Ti中n个类别中的每个类别的k个示例后,元学习算法必须适应对Ti中的数据进行分类,则该任务的特征为n-way,k-shot。
元学习方案通常依赖于带有内部循环和外部循环的双层优化问题。
外循环的迭代涉及首先对“任务”进行采样,该“任务”包括两组标记数据:支持数据Tsi和查询数据Tqi。然后,在内部循环中,使用支持数据对要训练的模型进行微调。最后,例程返回到外循环,在该外循环中,元学习算法将查询数据相对于预微调的权重的损失降至最低。通过微分内环计算并更新网络参数以使内环微调尽可能有效,来执行此最小化。

2.元学习有效性的解释和可视化
实验发现,在所有情况下,元学习特征提取器均优于相同体系结构的经典训练模型。全面的性能优势表明,元学习的功能在质量上与传统功能有所不同,并且从根本上来说优于一次性学习。
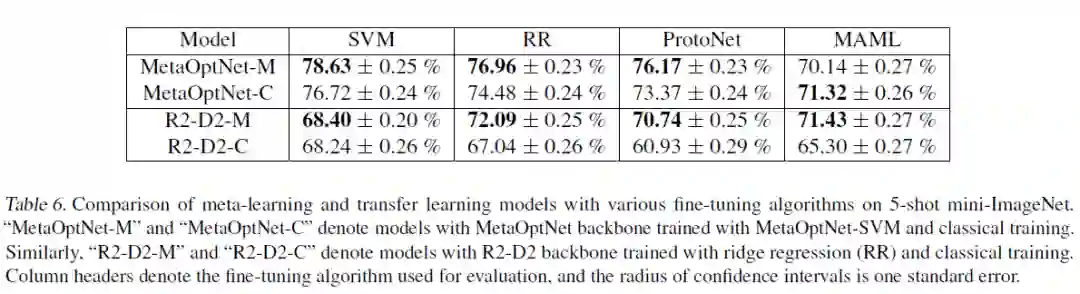
2.1在特征空间中测量聚类
首先,测量不同的训练方法对特征表示的聚类程度:

2.2比较元学习和经典训练模型的特征表示
| 通过LDA对特征空间进行可视化: |
|
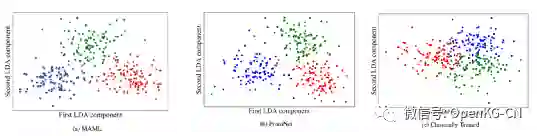 |
可以看到,元学习和原型学习的方法,在语义空间中的分布更加合理。特征空间的聚类可以提高迁移的成功率。
2.3为参数空间中的任务损失寻找局部极小值簇
我们在特征空间图中看到,由MAML特征生成的前两个LDA组件在外观上看起来是分开的类。现在,我们通过为预先训练的MAML模型以及相同体系结构的经典训练模型计算我们的正则化值,来量化MAML与转移学习相比的班级分离程度。我们发现,实际上,MAML表现出比相同体系结构的经典训练模型更差的特征分离。
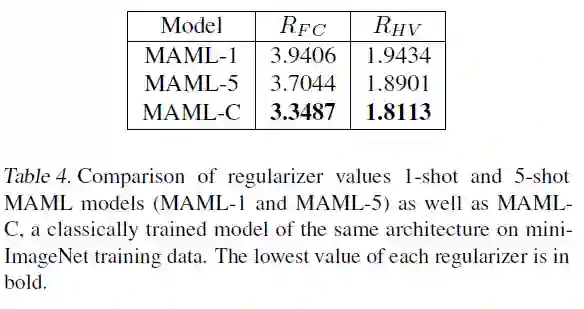
3总结
在这项工作中,阐明了元学习网络与经过经典训练的对等网络之间的两个关键区别。我们发现有证据表明,相对于类之间的差异,元学习算法将类中特征向量之间的差异最小化。将类内特征的变化减至最少对few-shot性能至关重要。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。




