
【导读】小样本学习是学术界和工业界近年来关注的焦点。2020年以来,AAAI、WSDM、ICLR、CVPR会议论文公布,专知小编整理了最新8篇关于知识图谱的论文,来自Google、PSU、人大、微软、腾讯、阿里巴巴等,包含元迁移学习、图神经网络、小样本文本分类等,请大家查看!
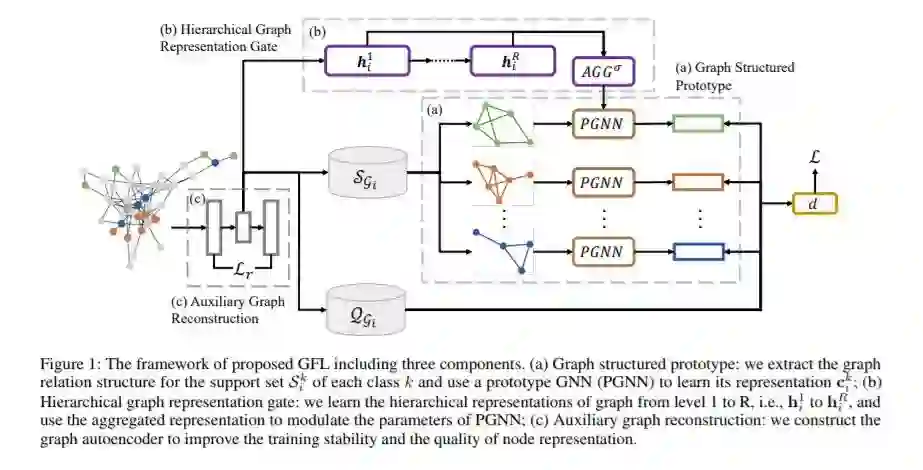
1、Graph Few-shot Learning via Knowledge Transfer(通过知识迁移的图小样本学习),AAAI2020
摘要:对于具有挑战性的半监督节点分类问题,已有广泛的研究。图神经网络(GNNs)作为一个前沿领域,近年来引起了人们极大的兴趣。然而,大多数gnn具有较浅的层,接收域有限,并且可能无法获得令人满意的性能,特别是在标记节点数量很少的情况下。为了解决这一问题,我们创新性地提出了一种基于辅助图的先验知识的图小样本学习(GFL)算法,以提高目标图的分类精度。具体来说,辅助图与目标之间共享一个可转移的度量空间,该空间以节点嵌入和特定于图的原型嵌入函数为特征,便于结构知识的传递。对四个真实世界图形数据集的大量实验和消融研究证明了我们提出的模型的有效性
论文地址:
https://arxiv.org/abs/1910.03053
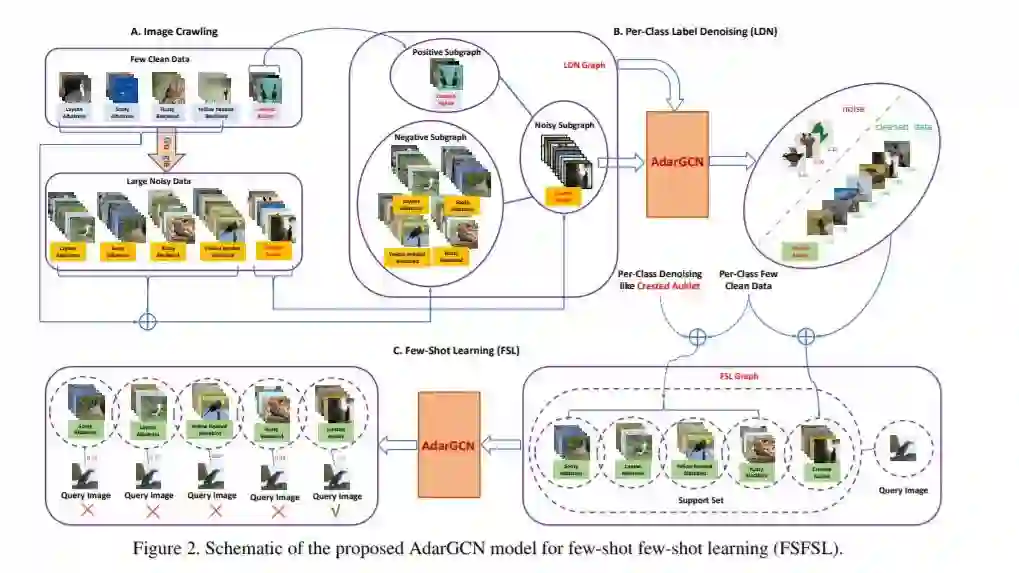
2、AdarGCN: Adaptive Aggregation GCN for Few-Shot Learning(自适应聚合GCN的小样本学习)
摘要:现有的小样本学习(FSL)方法假设源类中存在足够的训练样本,可以将知识转移到训练样本较少的目标类中。然而,这种假设通常是无效的,特别是在细粒度识别方面。在这项工作中,我们定义了一个新的FSL设置,称为few-shot fewshot learning (FSFSL),在这种情况下,源类和目标类都只有有限的训练样本。为了克服源类数据稀缺的问题,一个自然的选择是从web中抓取具有类名作为搜索关键字的图像。然而,爬行图像不可避免地会受到大量噪声(不相关的图像)的破坏,从而影响性能。针对这一问题,我们提出了一种基于GCN的图形卷积网络标签去噪(LDN)方法来去除不相关的图像。在此基础上,我们提出了一种基于gcn的清洁web图像和原始训练图像的FSL方法。针对LDN和FSL任务,提出了一种新的自适应聚合GCN (AdarGCN)模型。利用AdarGCN,可以自动确定每个图节点所携带的信息在图结构中传播了多少以及传播了多远,从而减轻了噪声和边缘训练样本的影响。大量的实验表明,我们的AdarGCN在新的FSFSL和传统的FSL设置下的优越性能。
论文地址:
https://www.zhuanzhi.ai/paper/5189982e35b0950b3dd3da91d68a5d07
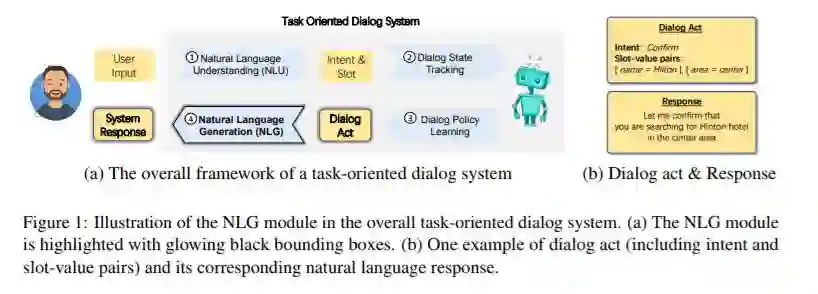
3、Few-shot Natural Language Generation for Task-Oriented Dialog(面向任务对话的小样本自然语言生成)
摘要:自然语言生成(NLG)模块是面向任务的对话系统的重要组成部分,它将语义形式的对话行为转化为自然语言的响应。传统的基于模板或统计模型的成功通常依赖于大量注释的数据,这对于新领域来说是不可行的。因此,在实际应用中,如何利用有限的标记数据很好地推广NLG系统至关重要。为此,我们提出了第一个NLG基准测试FewShotWoz来模拟面向任务的对话系统中的小样本学习设置。进一步,我们提出了SC-GPT模型。通过对大量的NLG标注语料库进行预训练,获得可控的生成能力,并通过少量的领域特定标签进行微调,以适应新的领域。在FewShotWoz和大型的多领域woz数据集上进行的实验表明,所提出的SC-GPT显著优于现有的方法(通过各种自动指标和人工评估进行测量)。
论文地址:
https://www.zhuanzhi.ai/paper/16510460dca11e426c62e6d82031c7fc
4、Meta-Transfer Learning for Zero-Shot Super-Resolution(元迁移学习的零样本超分)CVPR2020
摘要:卷积神经网络(CNNs)通过使用大规模的外部样本,在单幅图像的超分辨率(SISR)方面有了显著的改善。尽管它们基于外部数据集的性能非常出色,但它们无法利用特定图像中的内部信息。另一个问题是,它们只适用于它们所监督的数据的特定条件。例如,低分辨率(LR)图像应该是从高分辨率(HR)图像向下采样的“双三次”无噪声图像。为了解决这两个问题,零样本超分辨率(ZSSR)被提出用于灵活的内部学习。然而,他们需要成千上万的梯度更新,即推理时间长。在这篇论文中,我们提出了一种利用零样本超分辨的元转移学习方法。准确地说,它是基于找到一个适合内部学习的通用初始参数。因此,我们可以利用外部和内部信息,其中一个梯度更新可以产生相当可观的结果。(见图1)。通过我们的方法,网络可以快速适应给定的图像条件。在这方面,我们的方法可以应用于一个快速适应过程中的一个大光谱的图像条件。
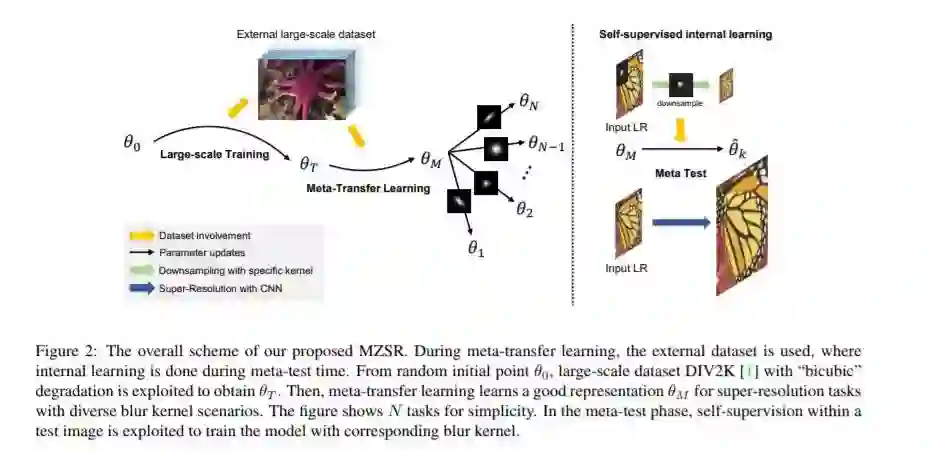
论文地址:
https://www.zhuanzhi.ai/paper/060b612853dfdd5af41688d50ce946d0
5、Few-shot Text Classification with Distributional Signatures(小样本文本分类)ICLR2020
摘要:在本文中,我们探讨了元学习在小样本文本分类中的应用。元学习在计算机视觉方面表现出了很强的性能,在计算机视觉中,低级模式可以在学习任务之间转移。然而,直接将这种方法应用于文本是具有挑战性的——对于一个任务来说信息丰富的词汇特性对于另一个任务来说可能是无关紧要的。因此,我们的模型不仅从单词中学习,还利用它们的分布特征,这些分布特征编码相关的单词出现模式。我们的模型在元学习框架内进行训练,将这些特征映射到注意力分数,然后用注意力分数来衡量单词的词汇表示。我们证明,我们的模型在6个基准数据集(1-shot分类平均20.0%)上,在词汇知识学习的原型网络(Snell et al., 2017)上,在小样本文本分类和关系分类上都显著优于原型网络。
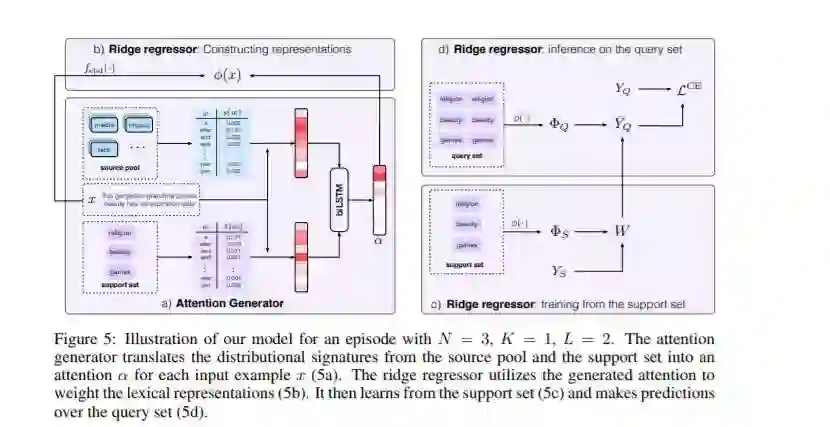
论文地址:
https://arxiv.org/abs/1908.06039
- Evolving Losses for Unsupervised Video Representation Learning(无监督视频表示学习的损失演化)CVPR2020
摘要:我们提出了一种从大规模无标记视频数据中学习视频表示的新方法。理想情况下,这种表现形式应该是通用的、可转移的,可以直接用于新的任务,比如动作识别和零或少样本学习。我们将无监督表示法学习描述为一个多模态、多任务学习问题,其中表示法通过精馏在不同的模式之间共享。在此基础上,我们引入了损失函数演化的概念,利用进化搜索算法自动寻找包含多个(自监督)任务和模式的损失函数的最优组合。在此基础上,我们提出了一种基于Zipf法则的无监督表示法评价指标,该指标使用对一个大的未标记数据集的分布匹配作为先验约束。这种不受监督的约束,不受任何标记的引导,与受弱监督的、特定于任务的约束产生类似的结果。提出的无监督表示学习方法在单RGB网络中取得了良好的学习效果,并优于已有的学习方法。值得注意的是,它也比几种基于标签的方法(如ImageNet)更有效,除了大型的、完全标记的视频数据集。
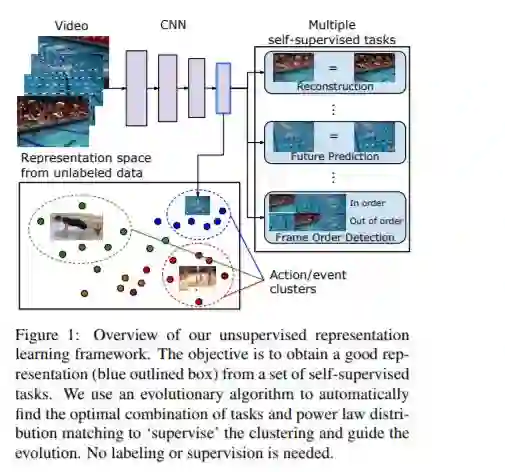
论文地址:
https://www.zhuanzhi.ai/paper/1cd13817179b2c3e512bbf00a320b4eb
- Few-shot acoustic event detection via meta-learning(元学习的小概率语音事件检测)ICASSP 2020
摘要:本文研究了小样本语音事件检测技术。少样本学习能够用非常有限的标记数据检测新事件。与计算机视觉等其他研究领域相比,语音识别的样本学习研究较少。我们提出了小样本AED问题,并探索了不同的方法来利用传统的监督方法,以及各种元学习方法,这些方法通常用于解决小样本分类问题。与有监督的基线相比,元学习模型具有更好的性能,从而显示了它对新音频事件的泛化效果。我们的分析包括初始化和领域差异的影响,进一步验证了元学习方法在小样本AED中的优势。
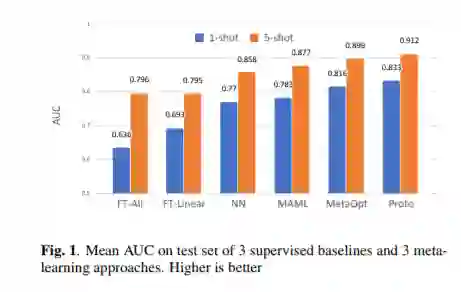
论文地址:
https://www.zhuanzhi.ai/paper/1600398c5662ddbea82187c132819ea4
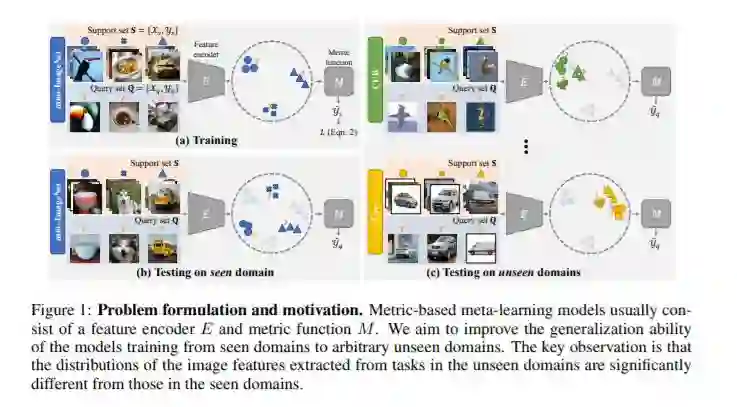
- Cross-Domain Few-Shot Classification via Learned Feature-Wise Transformation(跨域小样本分类)ICLR2020
摘要:小样本分类旨在识别每个类别中只有少数标记图像的新类别。现有的基于度量的小样本分类算法通过使用学习度量函数将查询图像的特征嵌入与少数标记图像(支持示例)的特征嵌入进行比较来预测类别。虽然已经证明了这些方法有很好的性能,但是由于域之间的特征分布存在很大的差异,这些方法往往不能推广到不可见的域。在这项工作中,我们解决了基于度量的方法在领域转移下的少样本分类问题。我们的核心思想是在训练阶段利用仿射变换增强图像的特征,模拟不同领域下的各种特征分布。为了捕获不同领域中特性分布的变化,我们进一步应用了一种学习-学习方法来搜索Feature-Wise转换层的超参数。我们使用5个小样本分类数据集:mini-ImageNet、CUB、Cars、Places和Plantae,在域概化设置下进行了大量的实验和消融研究。实验结果表明,所提出的特征变换层适用于各种基于度量的模型,并对域转移下的小样本分类性能提供了一致的改进。。
论文地址:


