论文浅尝 | 利用知识图谱增强神经网络来解决自然语言处理的任务

Citation: K. M. Annervaz, Somnath Basu Roy Chowdhury, and AmbedkarDukkipati. Learning beyond datasets: Knowledge graph augmented neural networksfor natural language processing. CoRR, abs/1802.05930, 2018.
URL:https://arxiv.org/pdf/1802.05930.pdf
Motivation
机器学习一直是许多AI问题的典型解决方案,但学习过程仍然严重依赖于特定的训练数据。一些学习模型可以结合贝叶斯建立中的先验知识,但是这些学习模型不具备根据需要访问任何结构化的外部知识的能力。本文的目标是开发一种深度学习模型,可以根据任务使用注意力机制从知识图谱中提取相关的先验知识。本文意在证明,当深度学习模型以知识图谱的形式访问结构化的知识时,可以用少量的标记训练数据进行训练,从而降低传统的深度学习模型对特定训练数据的依赖。
Model
模型的输入是一组句中的词构成的词向量序列 x=[x_1, x_2,...,x_T],经过一个 LSTM 单元得到每个词向量的隐藏层状态 h_t = f(x_t, h_{t-1}),然后将得到的隐藏层状态向量加和平均得到 o = 1/T(\sum_{t=1}^{T}h_t)。根据可以计算上下文向量 C=ReLU(o^T W)。实体和关系对应的上下文向量分别与实体和关系的向量相乘,经过softmax操作,算出每个实体和关系的权重 \alpha_{e_i}, \alpha_{r_i}。其中,实体和关系的向量是通过DKRL模型(一种结合文本描述的知识图谱表示学习模型,论文链接https://aaai.org/ocs/index.php/AAAI/AAAI16/paper/view/12216/12004)计算得到。
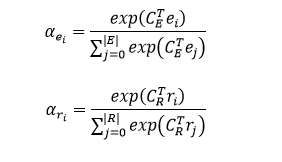
然后将文本中的所有实体和关系分别根据前面算出的权重进行加权平均,从而得到文本中所有实体和关系的向量 e, r。
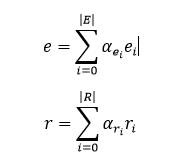
根据TransE的假设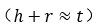
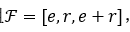
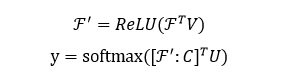
计算文本中实体和关系表示的原始模型架构如下图所示。
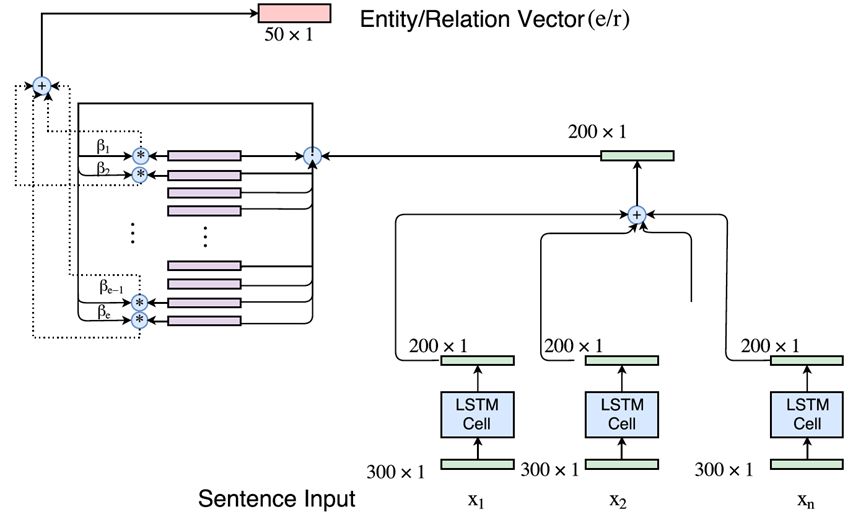
将计算实体和关系表示的模型与文本分类的LSTM模块进行联合训练,联合模型架构如下图所示。
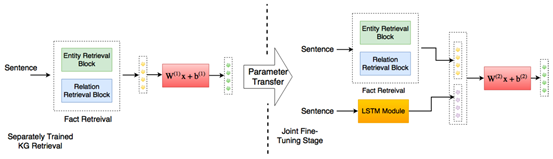
文本中实体和关系的数目很大,为每一个实体和关系分别计算权重开销不菲。为了减少注意力空间,本文利用k-means算法对实体和关系向量进行聚类,并引入了基于卷积的模型来学习知识图谱实体和关系集的表示。
Experiments
本文使用了News20,DBPedia数据集来解决文本分类的任务,使用斯坦福自然语言推理(SNLI)数据集进行自然语言推断的任务。还使用了Freebase (FB15k)和WordNet (WN18)作为相关的知识库输入。
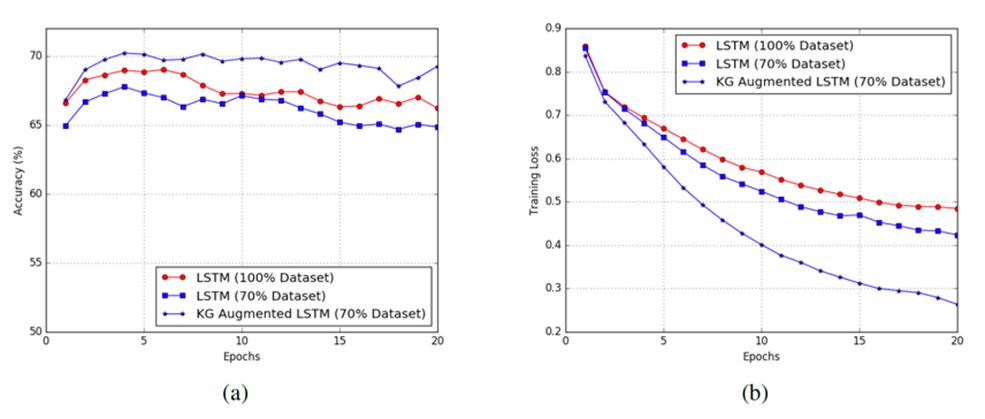
图(a)、图(b)分别表明,在SNLI数据集上训练的准确度和损失函数值。实验中分别比较100%数据集,70%数据集,以及70%数据集+KG三种情况输入的结果。可以发现,引入KG不仅可以降低深度学习模型对训练数据的依赖,而且还可以显著提高预测结果的准确度。此外,本文提出的方法对大量的先验信息的处理是高度可扩展的,并可应用于任何通用的NLP任务。
笔记整理:邓淑敏,浙江大学计算机学院2017级直博生,研究方向为知识图谱与文本联合表示学习,时序预测。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。


