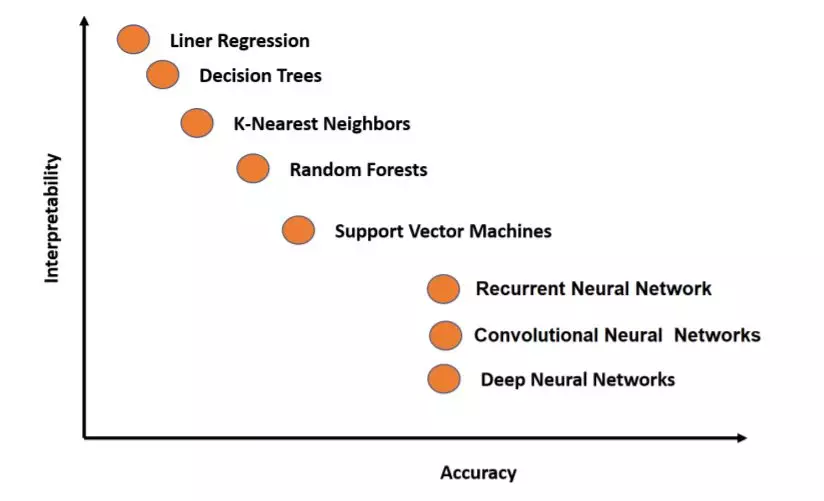
导读: 文本分类,是NLP的基础任务,旨在对给定文本预测其类别。然而,基础任务不代表简单任务:文本来源复杂多样,文本粒度有大有小,文本标签之间也有各种关系。面对各种问题,文本分类,仍在飞速发展中。来自美国弗吉尼亚大学的Kamran Kowsari博士等人,用了68页A4纸的篇幅,从0开始,细致的总结了文本分类近些年的发展,循序渐进,新手友好!

近年来,复杂文档和文本的数量呈指数级增长,需要对机器学习方法有更深刻的理解,才能在许多应用中准确地对文本进行分类。许多机器学习方法在自然语言处理方面取得了卓越的成绩。这些学习算法的成功依赖于它们理解复杂模型和数据中的非线性关系的能力。然而,为文本分类找到合适的结构、体系和技术对研究人员来说是一个挑战。本文简要介绍了文本分类算法。本文概述了不同的文本特征提取、降维方法、现有的分类算法和技术以及评估手段。最后,讨论了每种技术的局限性及其在实际问题中的应用。
代码详解: https://github.com/kk7nc/Text_Classification
文本分类流程:

- 特征提取:一般来说,文本和文档都是非结构化数据集。然而,当使用数学建模作为分类器的一部分时,这些非结构化文本序列必须转换到结构化的特征空间。首先,需要清除数据,以省略不必要的字符和单词。在数据被清除之后,可以使用形式化的特征提取方法。常用的特征提取技术有词频逆文档频率(TF- idf)、词频、Word2Vec和用于单词表示的全局向量(GloVe)。在第2节中,我们将这些方法分为单词嵌入技术和加权单词技术,并讨论了技术实现细节。

-
特征降维:由于文本或文档数据集通常包含许多独特的单词,数据预处理步骤可能会因时间和内存复杂性而滞后。这个问题的一个常见解决方案就是简单地使用廉价的算法。然而,在一些数据集中,这些类型的廉价算法并没有预期的那么好。为了避免性能下降,许多研究人员倾向于使用降维来减少应用程序的时间和内存复杂度。使用降维进行预处理可能比开发廉价的分类器更有效。在第3节中,我们概述了降维最常用的技术,包括主成分分析(PCA)、线性判别分析(LDA)和非负矩阵因子分解(NMF)。我们还讨论了用于无监督特征提取降维的新技术,如随机投影、自编码和t分布随机邻居嵌入(T-SNE).
-
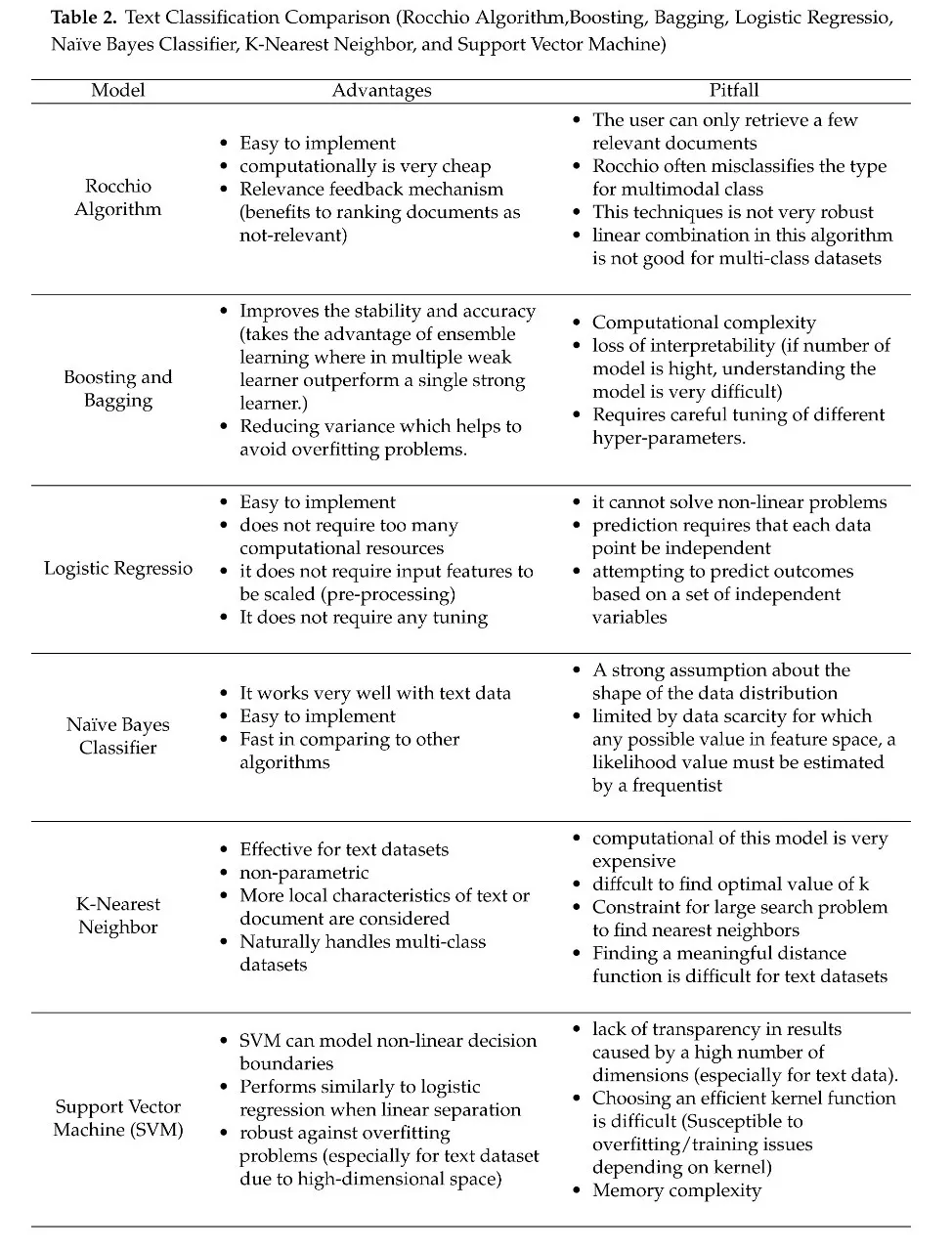
分类技术:文本分类管道中最重要的步骤是选择最佳分类器。如果对每种算法没有一个完整的概念理解,我们就不能有效地确定文本分类应用程序的最有效模型。在第四部分中,我们将讨论最流行的文本分类技术。首先,我们介绍了传统的文本分类方法,如Rocchio分类。接下来,我们将讨论基于ensemble的学习技术,如boost和Bagging,这些技术主要用于查询学习策略和文本分析。最简单的分类算法之一是Logistic回归(Logistic Regression, LR),它已经在大多数数据挖掘领域得到了解决。在信息检索作为一种可行的应用的最早历史上,朴素贝叶斯分类器(NBC)是非常流行的。我们有一个简单的概述朴素贝叶斯分类器,这是计算成本低,也需要非常低的内存。
非参数技术被应用于k近邻(KNN)等分类任务中。支持向量机(SVM)是另一种使用判别分类器进行文档分类的常用技术。该技术也可应用于生物信息学、图像、视频、人类活动分类、安全与保障等数据挖掘的各个领域。这个模型也被用作许多研究人员与他们自己的作品进行比较的基准,以突出新颖性和贡献。本文还研究了基于树的决策树和随机森林分类器在文档分类中的应用。每个基于树的算法将在单独的小节中介绍。近年来,图形分类被认为是一种分类任务,如条件随机域(CRFs)。然而,这些技术主要用于文档摘要和自动关键字提取。
近年来,深度学习方法在图像分类、自然语言处理、人脸识别等任务上取得了超过以往机器学习算法的效果。这些深度学习算法的成功依赖于它们在数据中建模复杂非线性关系的能力。

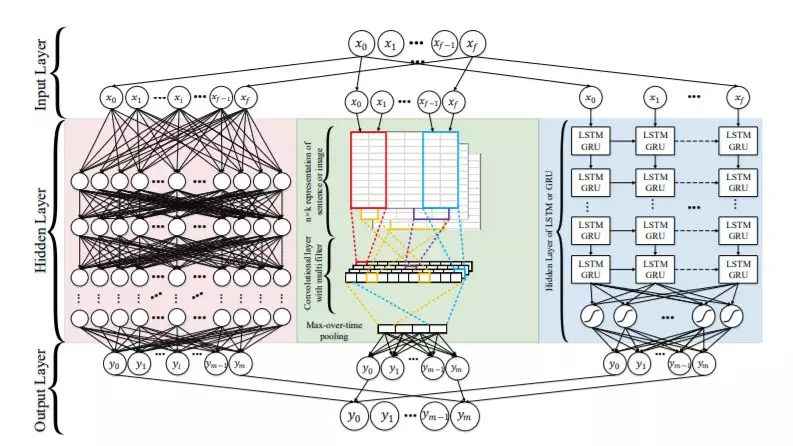
CNN文本分类
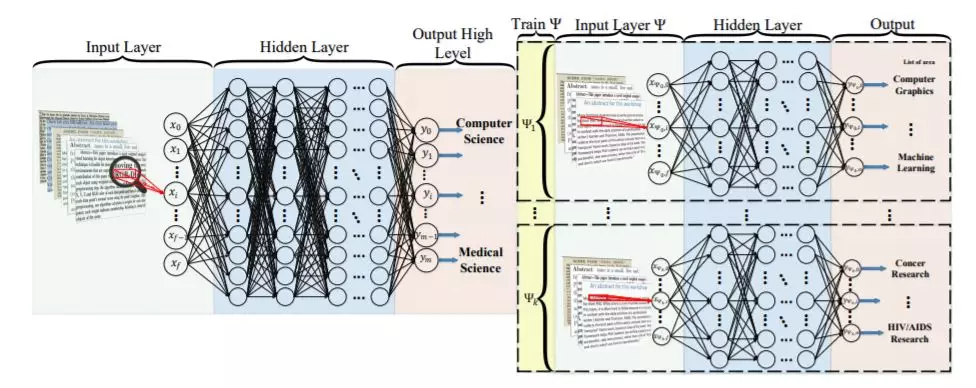
多模型文本分类
DNN框架

- 评价方法:文本分类管道的最后一部分是评估。理解模型如何执行对于文本分类方法的使用和开发至关重要。评价监督技术的方法有很多。精度计算是最简单的评估方法,但不适用于不平衡数据集。在第五节中,我们概述以下评价方法用于文本分类算法:Fβ分数,马修斯相关系数(MCC)[30],接收机工作特性(ROC),和ROC曲线下面积(AUC) 。