
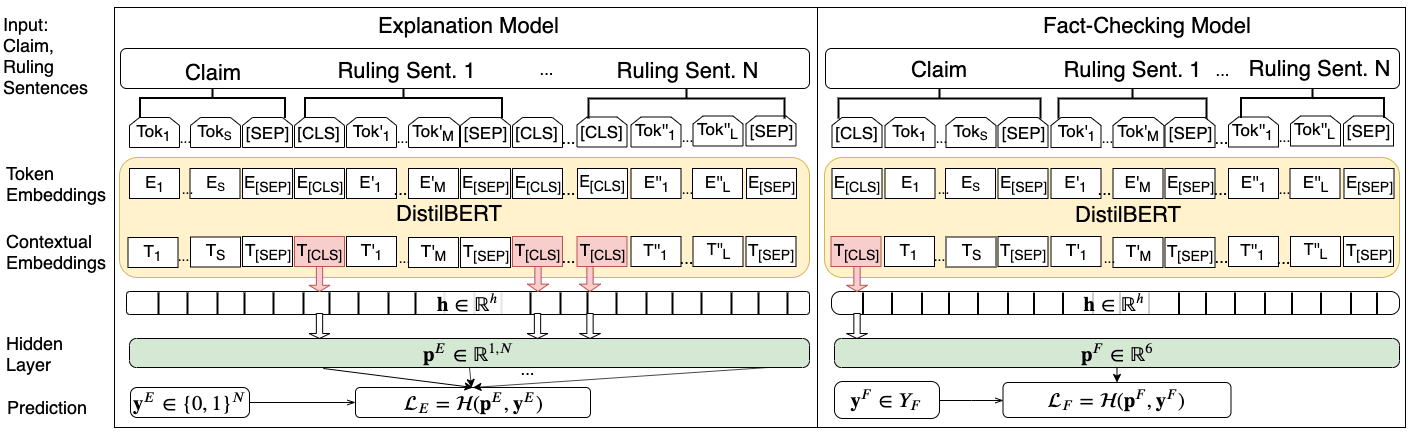
大多数关于自动事实核查的现有工作都是基于元数据、社会网络传播、声明中使用的语言,以及最近支持或否认声明的证据,来预测声明的准确性。这个谜题中仍然缺失的一个关键部分是,理解如何自动化这个过程中最复杂的部分——为声明的裁决生成理由。本文首次研究了如何根据可用的声明上下文自动生成这些解释,以及如何将此任务与准确性预测联合建模。我们的结果表明,同时优化这两个目标,而不是分别训练它们,可以提高事实核查系统的性能。手工评估的结果进一步表明,在多任务模型中生成的解释的信息量、覆盖率和整体质量也得到了提高。
成为VIP会员查看完整内容
相关内容
专知会员服务
99+阅读 · 2020年7月3日
专知会员服务
13+阅读 · 2020年4月16日
专知会员服务
17+阅读 · 2020年3月23日
专知会员服务
52+阅读 · 2020年1月20日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
相关VIP内容
专知会员服务
99+阅读 · 2020年7月3日
专知会员服务
13+阅读 · 2020年4月16日
专知会员服务
17+阅读 · 2020年3月23日
专知会员服务
52+阅读 · 2020年1月20日
相关资讯
相关论文
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日