
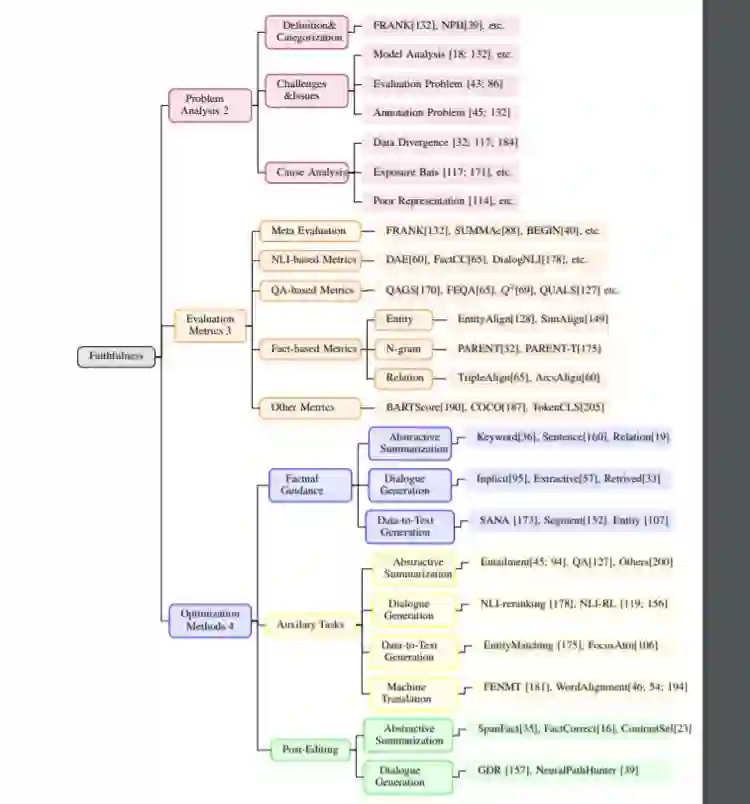
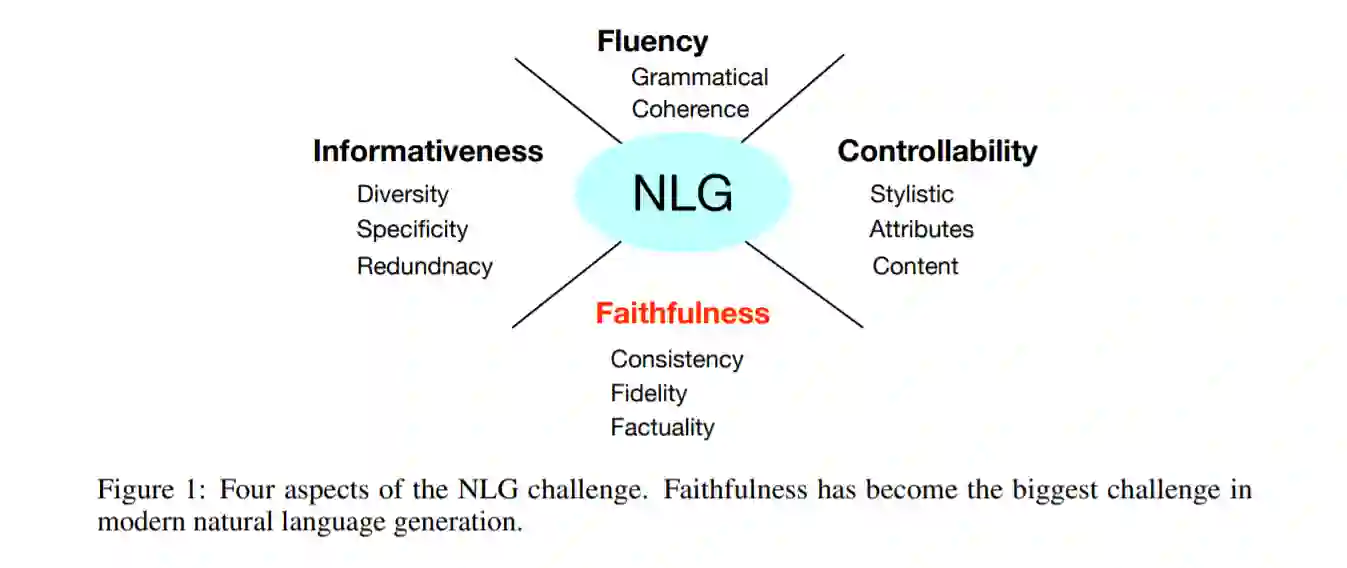
由于预训练语言模型等深度学习技术的发展,自然语言生成(NLG)近年来取得了很大的进展。这一进步导致了更流畅、连贯甚至属性可控(例如,文体、情感、长度等)的生成,自然地导致了下游任务的发展,如抽象摘要、对话生成、机器翻译和数据到文本的生成。然而,生成的文本通常包含不保真或不真实的信息,这一问题已经成为文本生成的最大挑战,使得文本生成的性能在许多现实场景的实际应用中不能令人满意。针对不同的任务提出了许多关于忠诚度问题的分析、评价和优化方法的研究,但并没有结合起来进行组织、比较和讨论。本文从问题分析、评价指标和优化方法三个方面,系统地综述了近年来NLG保真性问题的研究进展。我们将不同任务的评估和优化方法组织成一个统一的分类,以便于任务之间的比较和学习。并进一步讨论了今后的研究方向。
成为VIP会员查看完整内容
相关内容

专知会员服务
65+阅读 · 2020年5月12日
Arxiv
0+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月18日


相关VIP内容
专知会员服务
65+阅读 · 2020年5月12日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月18日