AAAI 2022 | 基于预训练-微调框架的图像差异描述任务

论文链接: https://www.zhuanzhi.ai/paper/ccffad6c8b192de0cd9569ea05d05019
图像差异描述生成(Image Difference Captioning,简称IDC) 的目标是对比两张相似图片、捕捉它们之间的视觉差异,然后用自然语言将这些差异描述出来,如图1所示。相比于经典的图像描述生成任务(Image Captioning, 为一张图片生成内容描述),它涉及两张相似图片的内容理解与对比,更富有挑战性。这个任务在现实生活中有广泛的应用,比如协助鸟类学家区分并记录相似的鸟类品种,自动检测和描述监控视频中的场景变化等等。

图1 图像差异描述任务的两个例子
IDC任务主要有两方面的挑战:
· 一方面,相似图片之间的差异是非常细粒度的,捕捉并描述出这种细粒度差异,需要建立(图片1,图片2,文本)三者之间更强的联系;
· 另一方面,该任务所需的三元组数据,人工标注的成本非常高,导致已有数据集的规模都较小,且不同数据集之间domain差异较大。
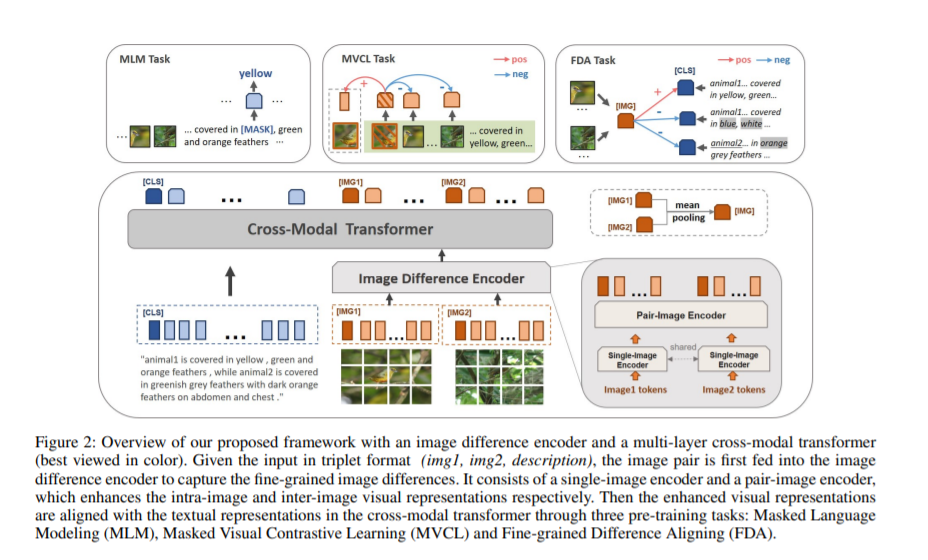
受到近期视觉-语言预训练(VLP)工作的启发,我们为IDC任务提出了一种预训练-微调的新范式。
对于IDC的第一个挑战,我们结合对比学习设计了三个自监督任务,在细粒度层面对视觉和语言的特征表示进行了对齐。对于第二个挑战,我们额外使用了来自其他任务的同域数据,来缓解标注数据较少的问题。我们的框架能灵活地处理这些形式不一的额外数据。实验表明,我们的模型在CLEVR-Change和Birds-to-words两个数据集上都取得了最佳效果。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“IDCL” 就可以获取《AAAI 2022 | 基于预训练-微调框架的图像差异描述任务》专知下载链接



登录查看更多
相关内容
Arxiv
15+阅读 · 2021年5月19日
Arxiv
26+阅读 · 2020年12月29日



相关VIP内容
相关资讯
相关论文
Arxiv
15+阅读 · 2021年5月19日
Arxiv
26+阅读 · 2020年12月29日