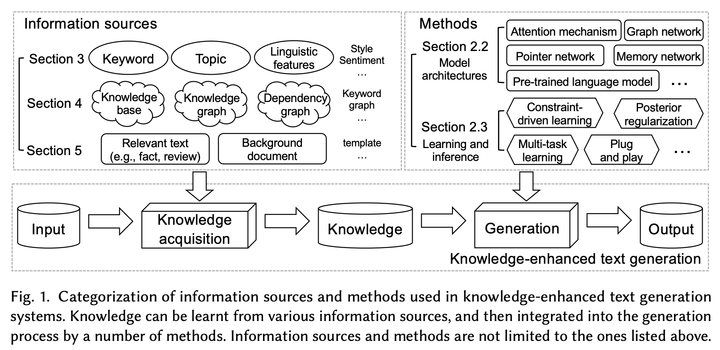
文本生成是目前自然语言处理(NLP)领域一个非常重要且有挑战的任务。文本生成任务通常是以文本作为输入(例如序列,关键词),通过将输入文本数据处理成语义表示,生成可以理解的自然语言文本。几个具有代表性的文本生成任务,例如机器翻译,文件摘要,对话系统。自从2014年Seq2Seq框架提出以来,文本生成迅速成为研究热点,包括一系列经典而有效的模型,例如循环神经网络(RNN),卷积神经网络(CNN),Transformer。基于这些模型,注意力机制(attention)和拷贝机制(copy/pointer-generator)的提出也极大促进了文本生成的研究。但是,研究人员发现,传统的文本生成任务只依靠输入文本进行生成,缺乏更加丰富的“知识”信息,因此生成的文本往往非常乏味,缺少有意思的内容。例如在对话系统中,如果只提供一段输入文本而没有其他上下文,对话机器人往往会回答“我也是一样”,“我听不懂你在说什么”等。相比之下,人类通过从外界获取、学习和储存知识,可以迅速理解对话里的内容从而做出合适的回复。所以,“知识”对于文本生成任务而言,可以超越输入文本中的语义限制,帮助文本生成系统生成更加丰富、有意思的文本。在文本生成任务中,“知识”是对输入文本和上下文的一种“补充”,可以由不同方法和信息源获得,包括但不限于关键词,主题,语言学特征,知识库,知识图谱等,可以参考下图1中的 Information Sources。这些“知识”可以通过不同的表示方法学习到有效的知识表示,用于增强文本生成任务的生成效果,这就被称为知识增强的文本生成(Knowledge-Enhanced Text Generation)。因此,知识增强的文本生成主要有两个难点:如何获取有用的知识(图1 Information Sources),以及如何理解并借助知识促进文本生成(图1 Methods)。接下来的内容将主要围绕着这两个问题进行展开。