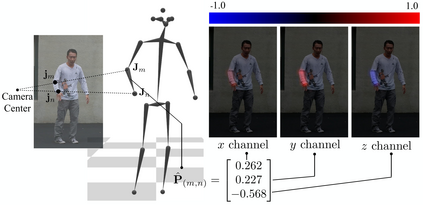
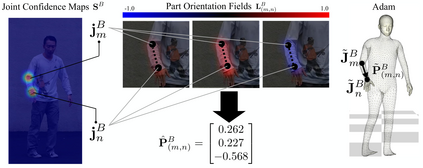
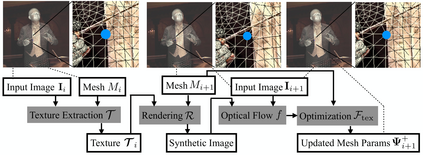
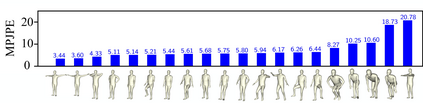
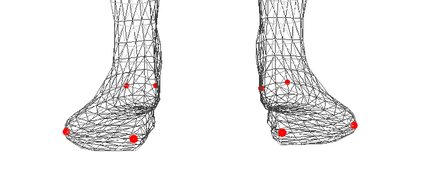
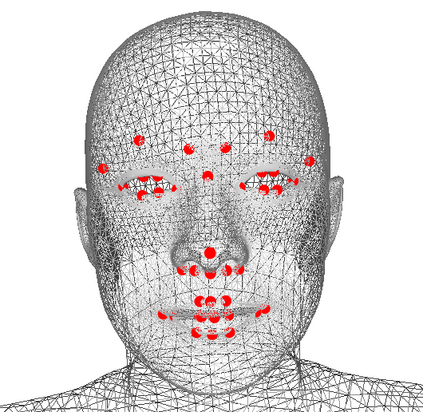
We present the first method to capture the 3D total motion of a target person from a monocular view input. Given an image or a monocular video, our method reconstructs the motion from body, face, and fingers represented by a 3D deformable mesh model. We use an efficient representation called 3D Part Orientation Fields (POFs), to encode the 3D orientations of all body parts in the common 2D image space. POFs are predicted by a Fully Convolutional Network (FCN), along with the joint confidence maps. To train our network, we collect a new 3D human motion dataset capturing diverse total body motion of 40 subjects in a multiview system. We leverage a 3D deformable human model to reconstruct total body pose from the CNN outputs by exploiting the pose and shape prior in the model. We also present a texture-based tracking method to obtain temporally coherent motion capture output. We perform thorough quantitative evaluations including comparison with the existing body-specific and hand-specific methods, and performance analysis on camera viewpoint and human pose changes. Finally, we demonstrate the results of our total body motion capture on various challenging in-the-wild videos. Our code and newly collected human motion dataset will be publicly shared.
翻译:我们提出第一个方法,从单视视图输入中捕捉目标人的3D全动。根据图像或单视视频,我们的方法从3D变形网格模型代表的身体、面部和手指重建运动。我们使用一个名为 3D 部分方向字段(POFs) 的有效代表,以编码通用 2D 图像空间中所有身体部位的3D方向。 POFs 是由一个完整的进化网络(FCN ) 和共同信任地图预测的。为了培训我们的网络,我们收集了一个新的 3D 人类运动数据集,在多视图系统中捕捉40个对象的全体运动。我们利用一个3D 变形人模型,通过在模型之前的形状和形状来重建CNN的全体。我们还提出了一个基于纹理的跟踪方法,以获得时间一致的运动捕捉产出。我们进行了彻底的定量评估,包括与现有的机构特有和手特有的方法进行比较,以及对相机观点和人造型变化的绩效分析。最后,我们展示了在各种具有挑战性的人类图象中进行全体运动拍摄的结果。我们将在新的和公开收集的人类图象中显示。