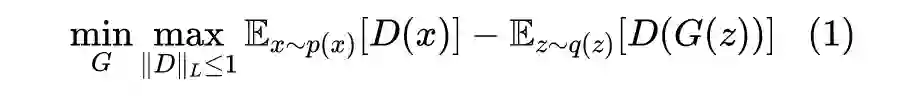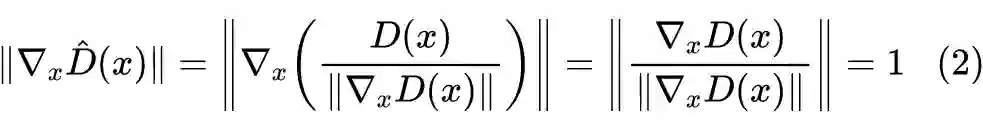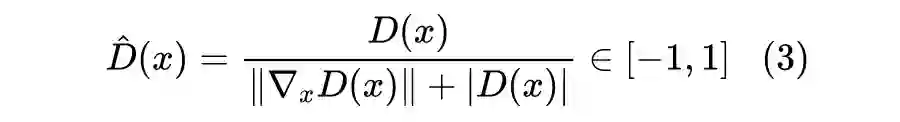©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 追一科技
研究方向 | NLP、神经网络
当前,WGAN 主流的实现方式包括参数裁剪(Weight Clipping)、谱归一化(Spectral Normalization)、梯度惩罚(Gradient Penalty),本来则来介绍一种新的实现方案:梯度归一化(Gradient Normalization),该方案出自两篇有意思的论文,分别是《Gradient Normalization for Generative Adversarial Networks》 [1] 和《GraN-GAN: Piecewise Gradient Normalization for Generative Adversarial Networks》 [2] 。
有意思在什么地方呢?从标题可以看到,这两篇论文应该是高度重合的,甚至应该是同一作者的。但事实上,这是两篇不同团队的、大致是同一时期的论文,一篇中了 ICCV,一篇中了 WACV,它们基于同样的假设推出了几乎一样的解决方案,内容重合度之高让我一直以为是同一篇论文。果然是巧合无处不在啊~
基础回顾
这里的关键是判别器
是一个带约束优化问题,需要在优化过程中满足 L 约束
,所以 WGAN 的实现难度就是如何往
里边引入该约束。
这里再普及一下,如果存在某个常数
,使得定义域中的任意
都满足
,那么我们称
满足 Lipschitz 约束 (L 约束),其中
的最小值,我们称为 Lipschitz 常数(L 常数),记为
。所以,对于 WGAN 判别器来说,要做到两步:1、
要满足 L 约束;2、L 常数要不超过 1。
事实上,当前我们主流的神经网络模型,都是“线性组合+非线性激活函数”的形式,而主流的激活函数是“近线性的”,比如 ReLU、LeakyReLU、SoftPlus 等,它们的导函数的绝对值都不超过 1,所以当前主流的模型其实都满足 L 约束,所以关键是如何让 L 常数不超过 1,当然其实也不用非 1 不可,能保证它不超过某个固定常数就行。
参数裁剪和谱归一化的思路是相似的,它们都是通过约束参数,保证模型每一层的 L 常数都有界,所以总的 L 常数也有界;而梯度惩罚则是留意到
的一个充分条件是
,所以就通过惩罚项
来施加“软约束”。
本文介绍的梯度归一化,也是基于同样的充分条件,它利用梯度将
变换为
,使其自动满足
。具体来说,我们通常用 ReLU 或 LeakyReLU 作为激活函数,在这个激活函数之下,
实际上是一个“分段线性函数”,这就意味着,除了边界之外,
在局部的连续区域内都是一个线性函数,相应地,
就是一个常向量。
当然,这样可能会有除 0 错误,所以两篇论文提出了不同的解决方案,第一篇(ICCV论文)直接将
也加到了分母中,连带保证了函数的有界性:
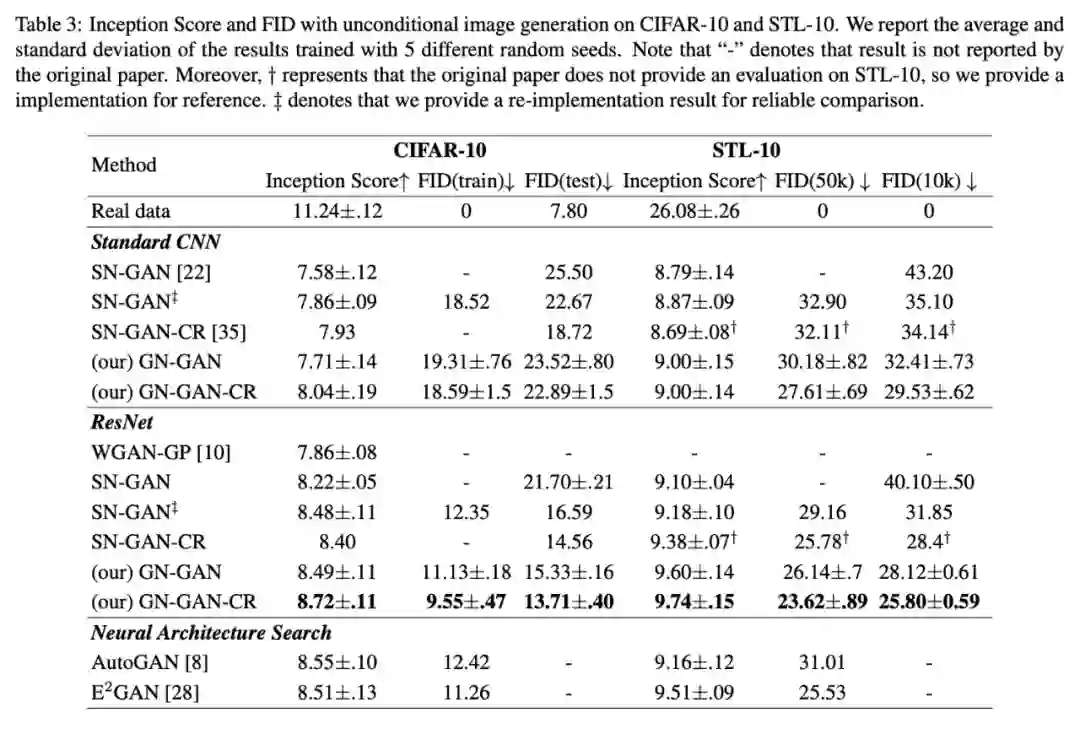
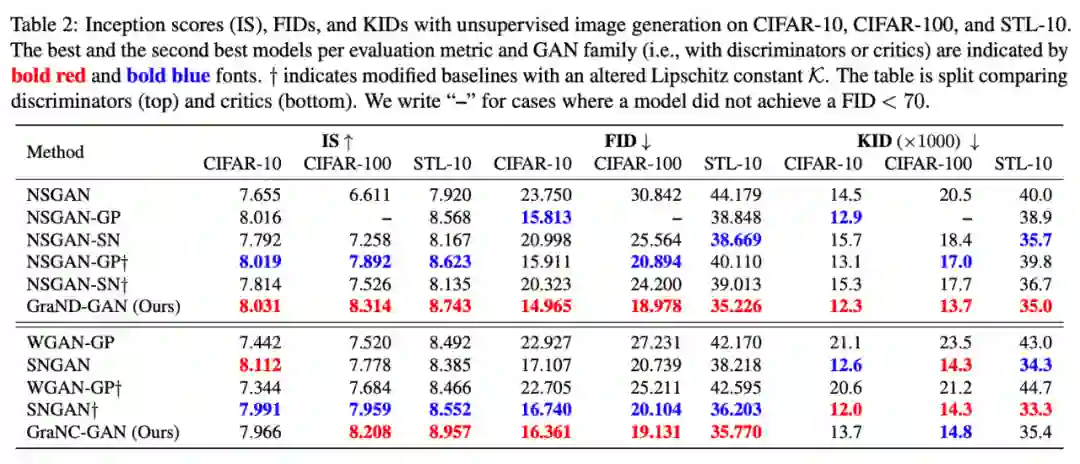
现在我们先来看看实验结果。当然,能双双中顶会,实验结果肯定是正面的,部分结果如下图:
结果看上去很好,理论看上去也没问题,还同时被两个顶会认可,看上去是一个好工作无疑了。然而,笔者的困惑才刚刚开始。
该工作最重要的问题是,如果按照分段线性函数的假设,那么
的梯度虽然在局部是一个常数,但整体来看它是不连续的(如果梯度全局连续又是常数,那么就是一个线性函数而不是分段线性了),然而
本身是一个连续函数,那么
就是连续函数除以不连续函数,结果就是一个不连续的函数!
所以问题就来了,不连续的函数居然可以作为判别器,这看起来相当不可思议。要知道这个不连续并非只在某些边界点不连续,而是在两个区域之间的不连续,所以这个不连续是不可忽略的存在。在 Reddit 上,也有读者有着同样的疑问,但目前作者也没有给出合理的解释(链接)。
另一个问题是,如果分段线性函数的假设真的有效,那么我用
效果极差。所以,有一种可能性就是,梯度归一化确实是有效的,但其作用的原因并不像上面两篇论文分析的那么简单,也许有更复杂的生效机制我们还没发现。此外,也可能是我们对 GAN 的理解还远远不够充分,也就是说,对判别器的连续性等要求,也许远远不是我们所想的那样。
最后,在笔者的实验结果中,梯度归一化的效果并不如梯度惩罚,并且梯度惩罚仅仅是训练判别器的时候用到了二阶梯度,而梯度归一化则是训练生成器和判别器都要用到二阶梯度,所以梯度归一化的速度明显下降,显存占用量也明显增加。所以从个人实际体验来看,梯度归一化不算一个特别友好的方案。
本文介绍了一种实现 WGAN 的新方案——梯度归一化,该方案形式上比较简单,论文报告的效果也还不错,但个人认为其中还有不少值得疑问之处。
[1] https://arxiv.org/abs/2109.02235
[2] https://arxiv.org/abs/2111.03162
[3]https://www.reddit.com/r/MachineLearning/comments/pjdvi4/r_iccv_2021_gradient_normalization_for_generative/
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学术热点剖析 、科研心得 或竞赛经验讲解 等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品 ,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬 ,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱: hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02 )快速投稿,备注:姓名-投稿
△长按添加PaperWeekly小编
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧