机器之心 & ArXiv Weekly Radiostation
本周论文包括来自阿伯丁大学、MIT 等机构的研究者对 ML 三要素中的算力需求进行了研究,发现自 2010 年以来,ML 算力需求增长 100 亿倍,每 6 个月翻番,深度学习成分水岭;CMU 创建一个开源的 AI 代码生成模型,C 语言表现优于 Codex。
Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
The evolution, evolvability and engineering of gene regulatory DNA
An Image Patch is a Wave: Quantum Inspired Vision MLP
COMPUTE TRENDS ACROSS THREE ERAS OF MACHINE LEARNING
GroupViT: Semantic Segmentation Emerges from Text Supervision
A SYSTEMATIC EVALUATION OF LARGE LANGUAGE MODELS OF CODE
OUR-GAN: One-shot Ultra-high-Resolution Generative Adversarial Networks
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
摘要:
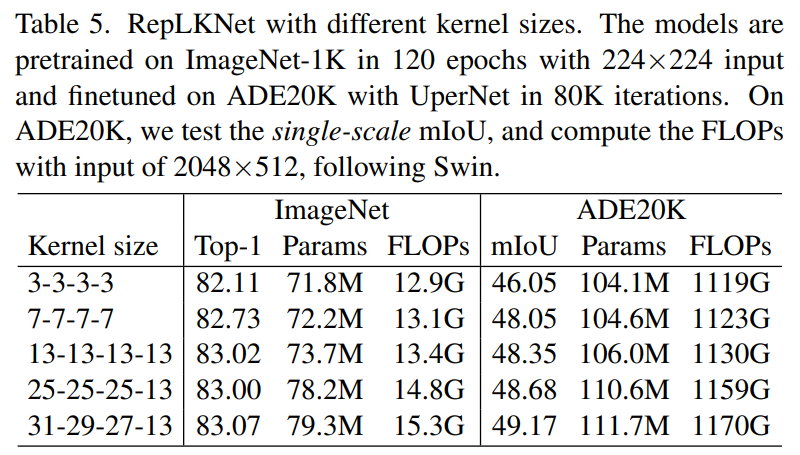
近日,清华大学、旷视科技等机构的研究者发表于 CVPR 2022 的工作表明,CNN 中的 kernel size 是一个非常重要但总是被人忽略的设计维度。在现代模型设计的加持下,卷积核越大越暴力,既涨点又高效,甚至大到 31x31 都非常 work(如下表 5 所示,左边一栏表示模型四个 stage 各自的 kernel size)!
即便在大体量下游任务上,该研究提出的超大卷积核模型 RepLKNet 与 Swin 等 Transformer 相比,性能也更好或相当!
1. 通过一系列探索性的实验,总结了在现代 CNN 中应用超大卷积核的五条准则:
用 depth-wise 超大卷积,最好再加底层优化(已集成进开源框架 MegEngine)
加 shortcut
用小卷积核做重参数化(即结构重参数化方法论,见去年的 RepVGG,参考文献 [1])
要看下游任务的性能,不能只看 ImageNet 点数高低
小 feature map 上也可以用大卷积,常规分辨率就能训大 kernel 模型
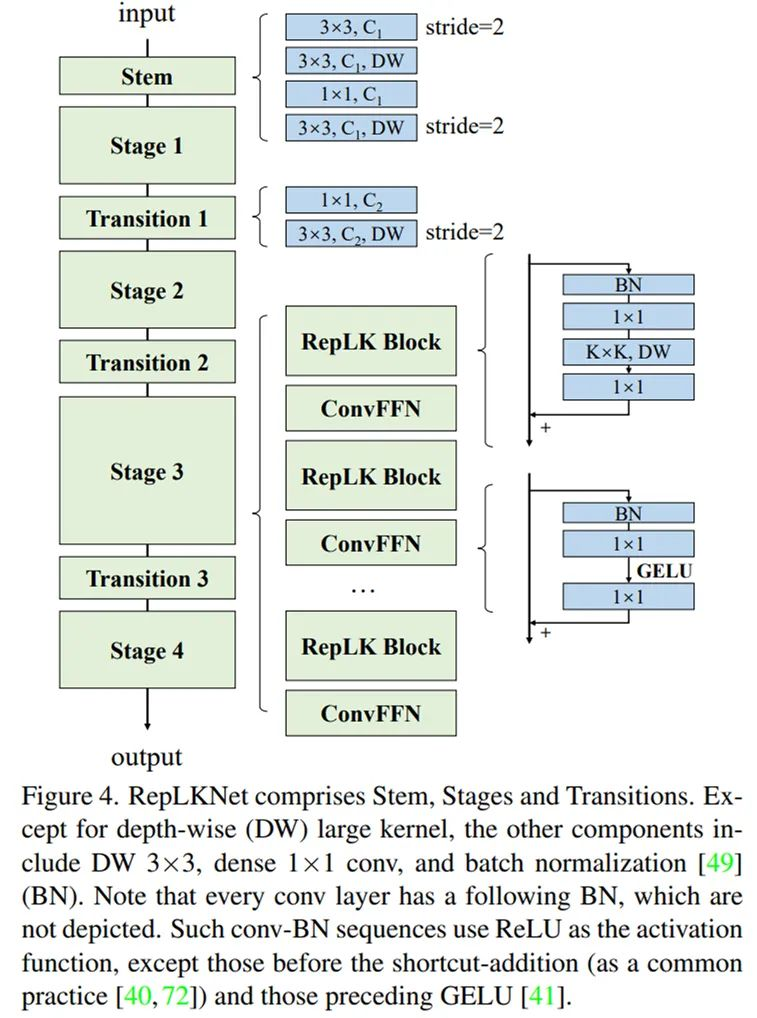
2. 基于以上准则,简单借鉴 Swin Transformer 的宏观架构,该研究提出了一种架构 RepLKNet,其中大量使用超大卷积,如 27x27、31x31 等。这一架构的其他部分非常简单,都是 1x1 卷积、Batch Norm 等喜闻乐见的简单结构,不用任何 attention。
3. 基于超大卷积核,对有效感受野、shape bias(模型做决定的时候到底是看物体的形状还是看局部的纹理?)、Transformers 之所以性能强悍的原因等话题的讨论和分析。该研究发现,ResNet-152 等传统深层小 kernel 模型的有效感受野其实不大,大 kernel 模型不但有效感受野更大而且更像人类(shape bias 高),Transformer 可能关键在于大 kernel 而不在于 self-attention 的具体形式。
例如,下图 1 分别表示 ResNet-101、ResNet-152、全为 13x13 的 RepLKNet、kernel 大到 31x31 的 RepLKNet 的有效感受野,可见较浅的大 kernel 模型的有效感受野非常大。
该研究以 Swin 作为主要的对比对象,并无意去刷 SOTA,所以简单借鉴 Swin 的宏观架构设计了一种超大卷积核架构。这一架构主要在于把 attention 换成超大卷积和与之配套的结构,再加一点 CNN 风格的改动。根据以上五条准则,RepLKNet 的设计元素包括 shortcut、depth-wise 超大 kernel、小 kernel 重参数化等。
推荐:
大到 31x31 的超大卷积核,涨点又高效,解读 RepLKNet。
论文 2:The evolution, evolvability and engineering of gene regulatory DNA
摘要:
近日,来自麻省理工学院和哈佛大学博德研究所等机构的研究者开发了一种新框架来研究调控 DNA 的适应度地形。该研究利用在数亿次实验测量结果上进行训练的神经网络模型,预测酵母菌 DNA 中非编码序列的变化及其对基因表达的影响,登上了最新一期《自然》杂志的封面。
该研究还设计了一种以二维方式表示适应度地形的独特方式,使其对于酵母以外的其他生物也能够理解已有的实验结果并预测非编码序列的未来演变,甚至有望为基因治疗和工业应用设计自定义的基因表达模式。
麻省理工学院研究生 Eeshit Dhaval Vaishnav、哥伦比亚大学助理教授 Carl de Boer(论文共同一作)等人创建了一个神经网络模型来预测基因表达。他们在一个数据集上训练模型,并观察每个随机序列如何影响基因表达,该数据集是通过将数百万个完全随机的非编码 DNA 序列插入酵母菌中生成的。他们专注于非编码 DNA 序列的一个特定子集——启动子,它是蛋白质的结合位点,可以打开或关闭附近的基因。
首先,为了确定他们的模型是否有助于合成生物学应用,如生产抗生素、酶和食物,研究人员使用它来设计能够为任何感兴趣的基因产生所需表达水平的启动子。然后,他们查阅了其他的科学论文,以确定基本的演化问题,看看他们的模型能否帮助解答这些问题。该团队甚至还从一项现有研究中获取了真实世界的种群数据集,其中包含了世界各地酵母菌株的遗传信息。通过这些方法,他们能够描绘出过去数千年的选择压力,这种压力塑造了今天的酵母基因组。
但是,为了创造一个可以探测所有基因组的强大工具,研究人员需要找到一种方法,在没有这样一个全面的种群数据集的情况下预测非编码序列的进化。为了实现这一目标,Vaishnav 和他的同事们设计了一种计算方法,允许他们将来自框架的预测绘制到二维图上。这帮助他们以非常简单的方式展示了任何非编码 DNA 序列如何影响基因表达和适应度,而无需在实验室工作台进行任何耗时的实验。
推荐:
MIT 设计深度学习框架登 Nature 封面,预测非编码区 DNA 突变。
论文 3:An Image Patch is a Wave: Quantum Inspired Vision MLP
摘要:
来自华为诺亚方舟实验室、北京大学、悉尼大学的研究者提出了一种受量子力学启发的视觉 MLP 架构,在 ImageNet 分类、COCO 检测、ADE20K 分割等多个任务上取得了 SOTA 性能。
该研究受量子力学中波粒二象性的启发,将 MLP 中每个图像块 (Token) 表示成波函数的形式,从而提出了一个新型的视觉 MLP 架构——Wave-MLP,在性能上大幅超越了现有 MLP 架构以及 Transformer。
量子力学是描述微观粒子运动规律的物理学分支,经典力学可被视为量子力学的特例。量子力学的一个基本属性是波粒二象性,即所有的个体(比如电子、光子、原子等)都可以同时使用粒子的术语和波的术语来描述。一个波通常包括幅值和相位两个属性,幅值表示一个波可能达到的最大强度,相位指示着当前处在一个周期的哪个位置。将一个经典意义上的粒子用波(比如,德布罗意波)的形式来表示,可以更完备地描述微观粒子的运动状态。
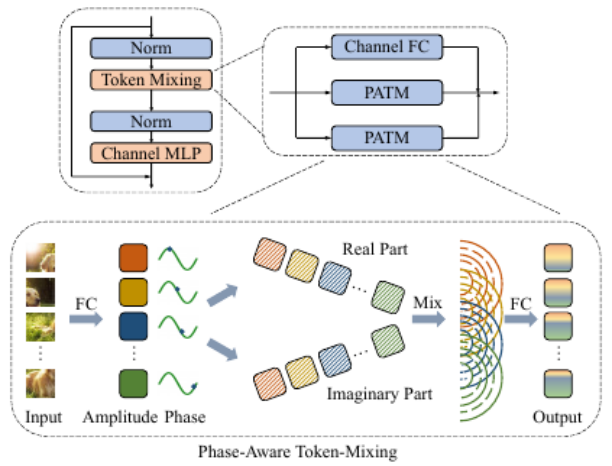
那么,对于视觉 MLP 中的图像块,能不能也把它表示成波的形式呢?该研究用幅值表达每个 Token 所包含的实际信息,用相位来表示这个 Token 当前所处的状态。在聚集不同 Token 信息的时候,不同 Token 之间的相位差会调制它们之间的聚合过程(如图 3 示)。考虑到来自不同输入图像的 Token 包含不同的语义内容,该研究使用一个简单的全连接模块来动态估计每个 Token 的相位。对于同时带有幅度和相位信息的 Token,作者提出了一个相位感知 Token 混合模块(PATM,如下图 1 所示)来聚合它们的信息。交替堆叠 PATM 模块和 MLP 模块构成了整个 Wave-MLP 架构。
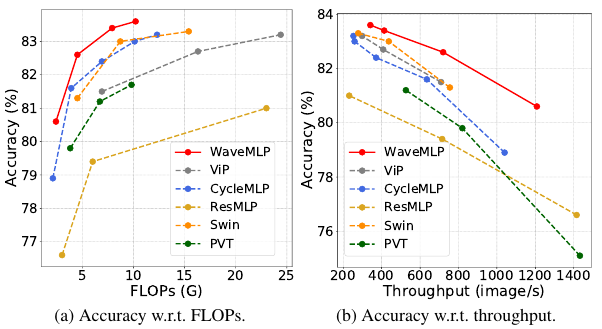
相比现有的视觉 Transformer 和 MLP 架构,Wave-MLP 有着明显的性能优势(如下图 2 所示)。在 ImageNet,Wave-MLP-S 模型上以 4.5G FLOPs 实现了 82.6% 的 top-1 准确率,比相似计算代价的 Swin-T 高 1.3 个点。此外,Wave-MLP 也可以推广到目标检测和语义分割等下游任务,展现出强大的泛化性能。
图 2:Wave-MLP 与现有视觉 Transformer、MLP 架构的比较
推荐:
图像也是德布罗意波!华为诺亚 & 北大提出量子启发 MLP,性能超越 Swin Transfomer。
论文 4:COMPUTE TRENDS ACROSS THREE ERAS OF MACHINE LEARNING
摘要:
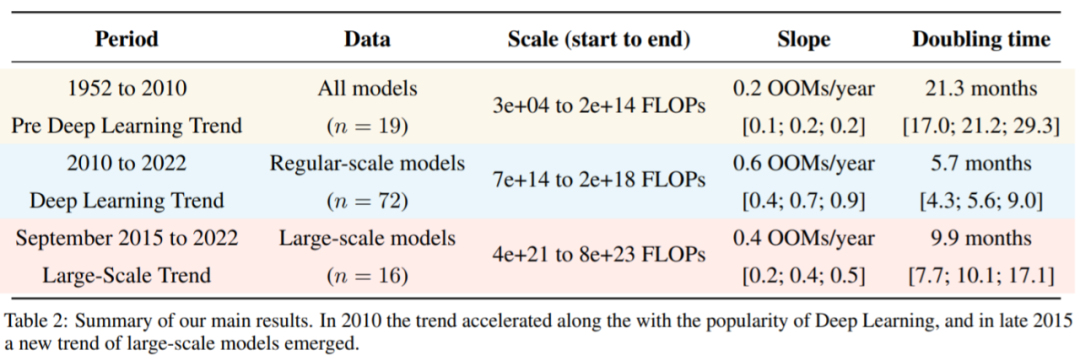
近日来自阿伯丁大学、MIT 等机构的研究者对 ML 三要素中的算力需求进行了研究。他们发现,在 2010 年之前训练所需的算力增长符合摩尔定律,大约每 20 个月翻一番。自 2010 年代初深度学习问世以来,训练所需的算力快速增长,大约每 6 个月翻一番。2015 年末,随着大规模 ML 模型的出现,训练算力的需求提高了 10 到 100 倍,出现了一种新的趋势。
基于上述发现,研究者将 ML 所需算力历史分为三个阶段:前深度学习时代;深度学习时代;大规模时代。总的来说,该论文详细研究了里程碑式 ML 模型随时间变化的算力需求。
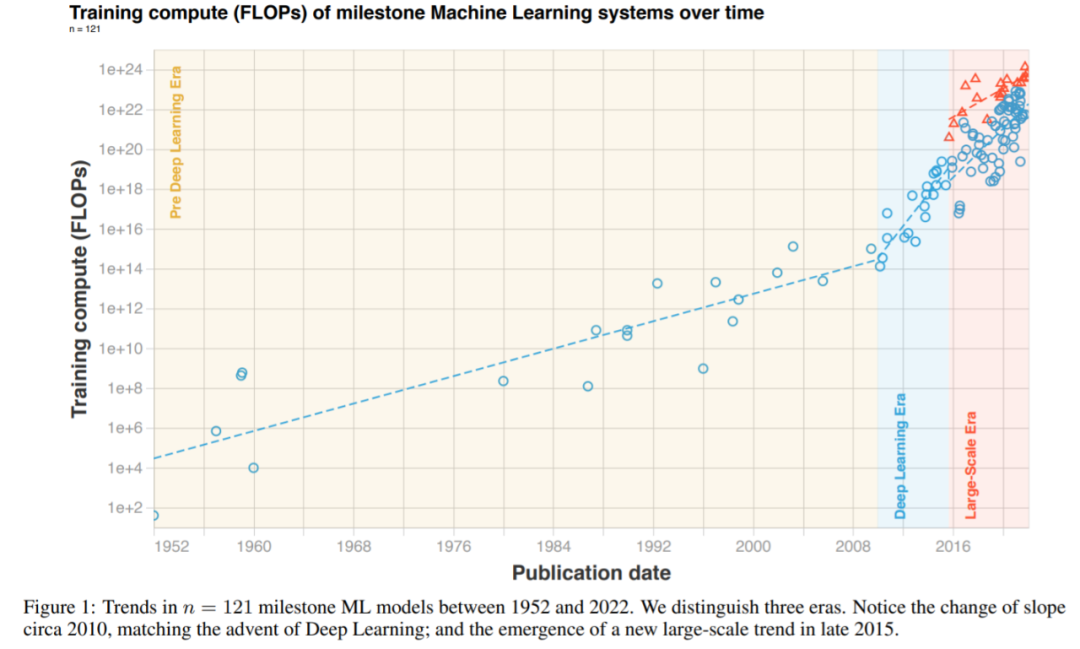
研究者根据三个不同的时代和三种不同的趋势来解读他们整理的数据。简单来说,在深度学习起飞前,有一个缓慢增长的时代。大约在 2010 年,这一趋势加速并且此后一直没有放缓。另外,2015 至 2016 年大规模模型出现了一个新趋势,即增长速度相似,但超越以往两个数量级(orders of magnitude, OOM)。具体可见下图 1 和表 2。
图 1:1952 年以来,里程碑式 ML 系统随时间推移的训练算力(FLOPs)变化。
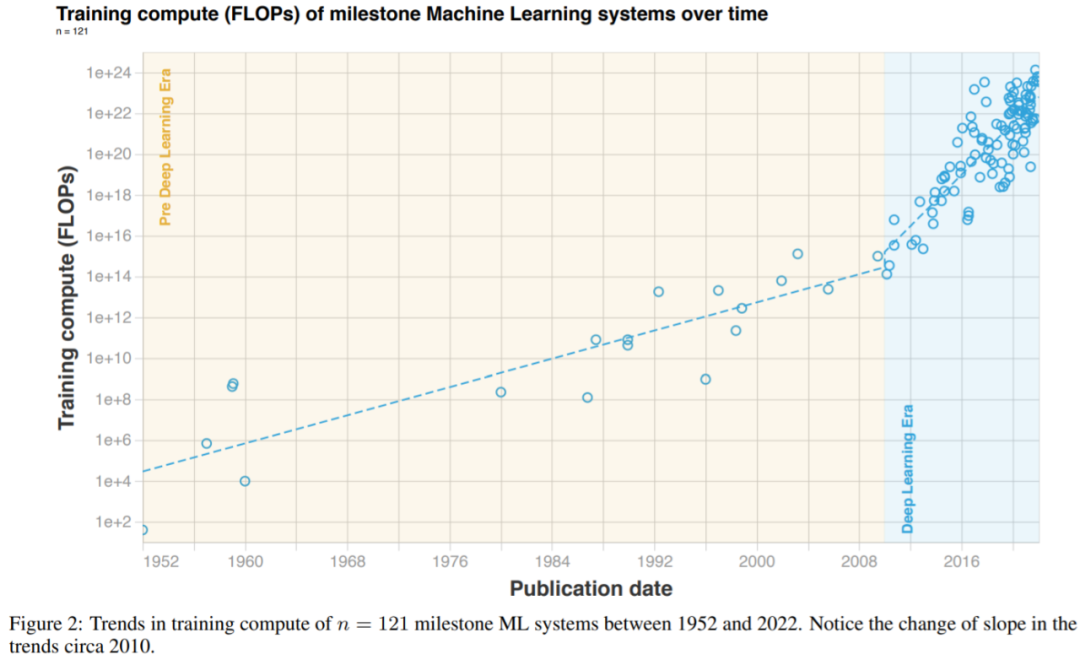
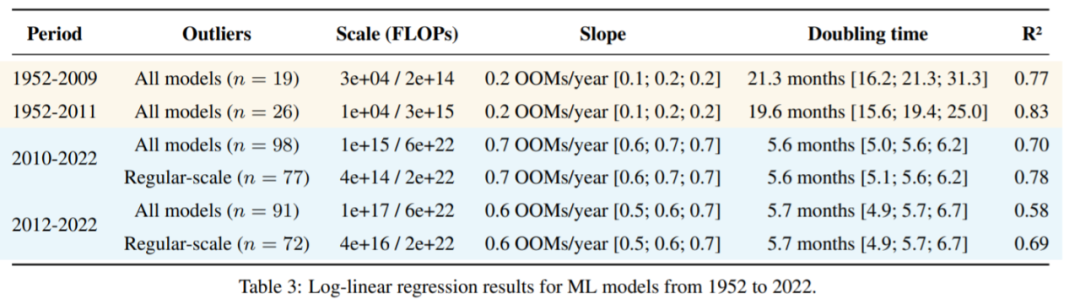
如果将深度学习时代的开始定为 2010 或 2012 年,研究者的结果几乎没有变化,具体如下表 3 所示。
图 2:1952 至 2022 年期间,里程碑式 ML 系统的算力变化趋势。请特别注意 2010 年左右的坡度变化。
表 3:1952 至 2022 年 ML 模型的对数线性回归结果。
推荐:
2010 年以来,ML 算力需求增长 100 亿倍,每 6 个月翻番,深度学习成分水岭。
论文 5:GroupViT: Semantic Segmentation Emerges from Text Supervision
摘要:
来自加州大学圣圣地亚哥分校和英伟达的研究者提出这样一个问题:我们是否也可以学习一个纯文本监督的语义分割模型,无需做任何像素标注,就能够以零样本方式泛化到不同对象类别或词汇集?
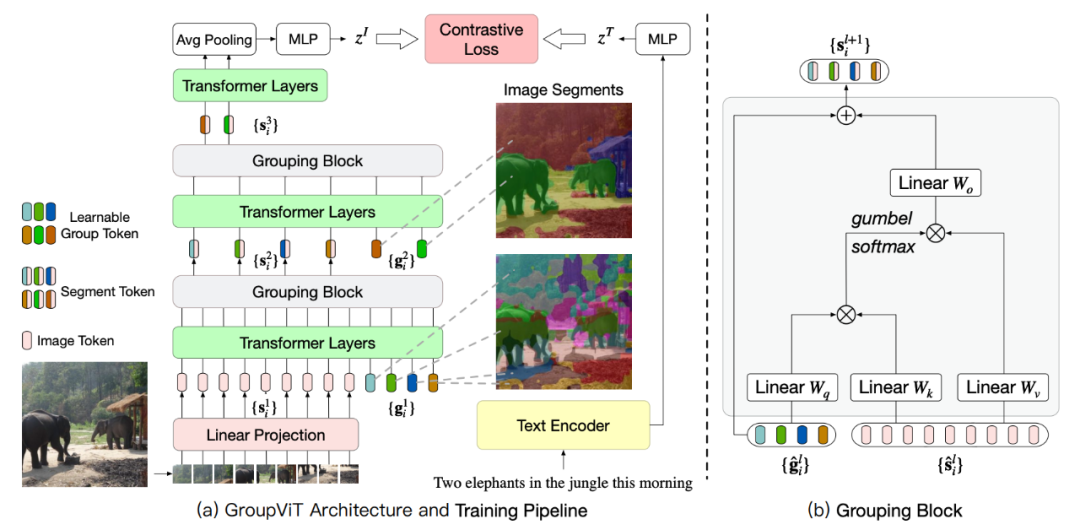
为了实现这一点,他们提出将分组机制加入深度网络。只要通过文本监督学习,分组机制就可以自动生成语义片段。方法概览如下图 1 所示,通过对具有对比损失的大规模配对图文数据进行训练,可以让模型不需要任何进一步的注释或微调的情况下,能够零样本迁移学习得到未知图像的语义分割词汇。
该研究的关键思想是利用视觉 Transformer(ViT)在其中加入新的视觉分组模块,研究者将新模型称为 GroupViT(分组视觉 Transformer)。
![]()
GroupViT 包含按阶段分组的 Transformer 层的分层结构,每个阶段会处理逐渐放大的视觉片段。右侧的图像显示了在不同分组阶段要处理的视觉片段。在初期阶段模型将像素分组为局部对象,例如大象的鼻子和腿。在更高的阶段进一步将它们合并成整体,例如整个大象和背景森林。
每个分组阶段都以一个分组块结束,该块会计算学习到的组标记和片段(图像)标记之间的相似度。相似度高的组会分配给同一组的段标记并合并在一起,并做进入下一个分组阶段的新段标记。
图 2:(a) GroupViT 的架构和训练流程。(b) 分组块的架构。
推荐:
做语义分割不用任何像素标签,UCSD、英伟达在 ViT 中加入分组模块,入选 CVPR 2022。
论文 6:A SYSTEMATIC EVALUATION OF LARGE LANGUAGE MODELS OF CODE
摘要:
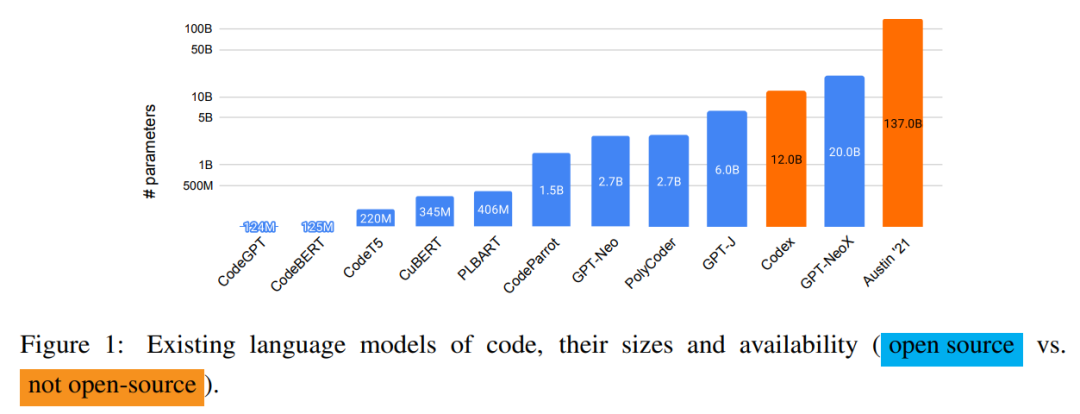
在近日一篇论文中,来自 CMU 计算机科学学院的几位研究者对跨不同编程语言的现有代码模型——Codex、GPT-J、GPT-Neo、GPT-NeoX 和 CodeParrot 进行了系统评估。他们希望通过比较这些模型来进一步了解代码建模设计决策的前景,并指出关键的缺失一环,即迄今为止,没有大规模开源语言模型专门针对多编程语言的代码进行训练。研究者推出了三个此类模型,参数量从 160M 到 2.7B,并命名为「PolyCoder」。
研究者首先对 PolyCoder、开源模型和 Codex 的训练语评估设置进行了广泛的比较;其次,在 HumanEval 基准上评估这些模型,并比较了不同大小和训练步的模型如何扩展以及不同的温度如何影响生成质量;最后,由于 HumanEval 只评估自然语言和 Python 生成,他们针对 12 种语言中的每一种都创建了相应未见过的评估数据集,以评估不同模型的困惑度。
结果表明,尽管 Codex 声称最擅长 Python 语言,但在其他编程语言中也表现出奇得好,甚至优于在 Pile(专为训练语言模型设计的 825G 数据集)上训练的 GPT-J 和 GPT-NeoX。不过,在 C 语言中,PolyCoder 模型取得的困惑度低于包括 Codex 在内的所有其他模型。
下图 1 展示了现有语言代码模型及它们的大小和可用性,除 Codex 和 Austin'21 之外全部开源。
研究者还讨论了代码语言建模中使用的三种流行的预训练方法,具体如下图 2 所示。
推荐:
CMU 创建一个开源的 AI 代码生成模型,C 语言表现优于 Codex。
论文 7:OUR-GAN: One-shot Ultra-high-Resolution Generative Adversarial Networks
摘要:
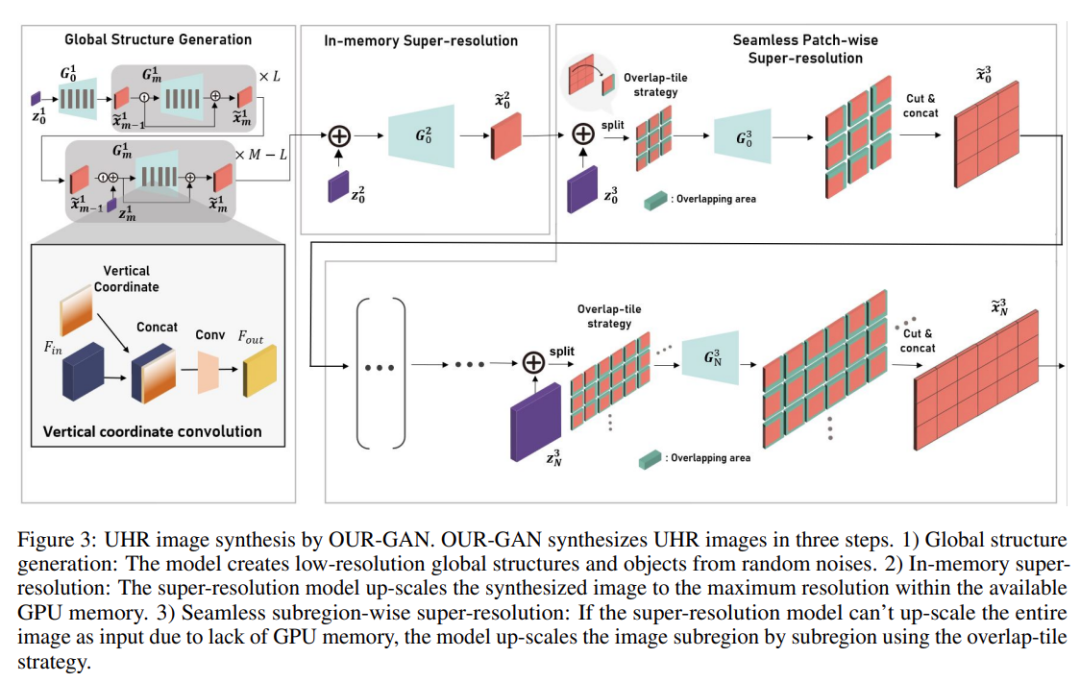
传统生成模型通常从相对较小的图像数据集中,基于 patch 分布学习生成大型图像,这种方法很难生成视觉上连贯的图像。OUR-GAN 以低分辨率生成视觉上连贯的图像,然后通过超分辨率逐渐提升分辨率。由于 OUR-GAN 从真实的 UHR 图像中学习,它可以合成具有精细细节的大规模形状,同时保持远距离连贯性。
OUR-GAN 应用无缝衔接的子区域超分辨率,在内存受限的条件下合成 4K 或更高分辨率的 UHR 图像,并解决了边界不连续的问题。此外,OUR-GAN 通过向特征图添加垂直位置嵌入来提高多样性和视觉连贯性。在 ST4K 和 RAISE 数据集上的实验结果表明:与现有方法相比,OUR-GAN 表现出更高的保真度、视觉连贯性和多样性。
我们来看一下 OUR-GAN 的合成效果,下图(上)是 OUR-GAN 训练使用的单个 4K 图像,(下)是 OUR-GAN 合成的 16K (16384 x 10912) 图像。
以下几组是 OUR-GAN 合成的 4K 风景图:
OUR-GAN 成功合成了具有多种图案的高质量纹理图像:
OUR-GAN 通过三个步骤合成占用有限 GPU 内存的 UHR 图像,如下图 3 所示。首先,OURGAN 生成低分辨率的全局结构。然后通过 in-memory 超分辨率在内存限制内尽可能提高分辨率。最后,OURGAN 通过逐个子区域应用超分辨率来进一步提高超出内存限制的分辨率来合成 UHR 图像。
超分辨率模型的输出分辨率受限于训练图像的分辨率。然而,ZSSR 和 MZSR 已经证明,通过利用信息的内部循环,超分辨率模型可以生成比训练图像大 2 到 4 倍的图像。
推荐:
首个单样本(one-shot)超高分辨率(UHR)图像合成框架 OUR-GAN,能够从单个训练图像生成具有 4K 甚至更高分辨率的非重复图像。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
本周 10 篇 NLP 精选论文是:
1. Imputing Out-of-Vocabulary Embeddings with LOVE Makes Language Models Robust with Little Cost. (from Gaël Varoquaux)
2. Don't Say What You Don't Know: Improving the Consistency of Abstractive Summarization by Constraining Beam Search. (from Daniel S. Weld)
3. Ask to Understand: Question Generation for Multi-hop Question Answering. (from Yang Gao)
4. Long Document Summarization with Top-down and Bottom-up Inference. (from Bo Pang, Silvio Savarese)
5. ConTinTin: Continual Learning from Task Instructions. (from Jia Li)
6. Continual Prompt Tuning for Dialog State Tracking. (from Minlie Huang)
7. EVA2.0: Investigating Open-Domain Chinese Dialogue Systems with Large-Scale Pre-Training. (from Minlie Huang)
8. elBERto: Self-supervised Commonsense Learning for Question Answering. (from Lawrence Carin)
9. Label Semantics for Few Shot Named Entity Recognition. (from Dan Roth)
10. Staged Training for Transformer Language Models. (from Kurt Keutzer)
本周 10 篇 CV 精选论文是:
1. Object discovery and representation networks. (from Evan Shelhamer, Andrew Zisserman)
2. Masked Visual Pre-training for Motor Control. (from Trevor Darrell, Jitendra Malik)
3. Progressive End-to-End Object Detection in Crowded Scenes. (from Xiangyu Zhang, Jian Sun)
4. PETR: Position Embedding Transformation for Multi-View 3D Object Detection. (from Xiangyu Zhang, Jian Sun)
5. Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs. (from Xiangyu Zhang, Jian Sun)
6. Unsupervised Semantic Segmentation by Distilling Feature Correspondences. (from Noah Snavely, William T. Freeman)
7. Integrating Language Guidance into Vision-based Deep Metric Learning. (from Oriol Vinyals)
8. Non-isotropy Regularization for Proxy-based Deep Metric Learning. (from Oriol Vinyals)
9. Continual Learning Based on OOD Detection and Task Masking. (from Bing Liu)
10. DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection. (from Quoc V. Le, Alan Yuille)
1. Invariance in Policy Optimisation and Partial Identifiability in Reward Learning. (from Stuart Russell)
2. Machine Learning Based Multimodal Neuroimaging Genomics Dementia Score for Predicting Future Conversion to Alzheimer's Disease. (from Alzheimer's Disease Neuroimaging Initiative)
3. Fine-tuning Global Model via Data-Free Knowledge Distillation for Non-IID Federated Learning. (from Dacheng Tao)
4. Do We Really Need a Learnable Classifier at the End of Deep Neural Network?. (from Zhouchen Lin, Dacheng Tao)
5. Gradient Correction beyond Gradient Descent. (from Wen Gao)
6. Task-Agnostic Robust Representation Learning. (from Philip Torr)
7. No free lunch theorem for security and utility in federated learning. (from Kai Chen)
8. Generalized Bandit Regret Minimizer Framework in Imperfect Information Extensive-Form Game. (from Yang Gao)
9. Non-Linear Reinforcement Learning in Large Action Spaces: Structural Conditions and Sample-efficiency of Posterior Sampling. (from Tong Zhang)
10. Multi Stage Screening: Enforcing Fairness and Maximizing Efficiency in a Pre-Existing Pipeline. (from Avrim Blum)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com