你有多久没调过 kernel size 了?虽然常常被人忽略,但只要将其简单加大,就能给人惊喜。
当你在卷积网络(CNN)的深度、宽度、groups、输入分辨率上调参调得不可开交的时候,是否会在不经意间想起,有一个设计维度 kernel size,一直如此显而易见却又总是被忽视,总是被默认设为 3x3 或 5x5?
当你在 Transformer 上调参调得乐不思蜀的时候,是否希望有一种简单、高效、部署容易、下游任务性能又不弱于 Transformer 的模型,带给你朴素的快乐?
近日,清华大学、旷视科技等机构的研究者发表于 CVPR 2022 的工作表明,CNN 中的 kernel size 是一个非常重要但总是被人忽略的设计维度。在现代模型设计的加持下,
卷积核越大越暴力,既涨点又高效,甚至大到 31x31 都非常 work
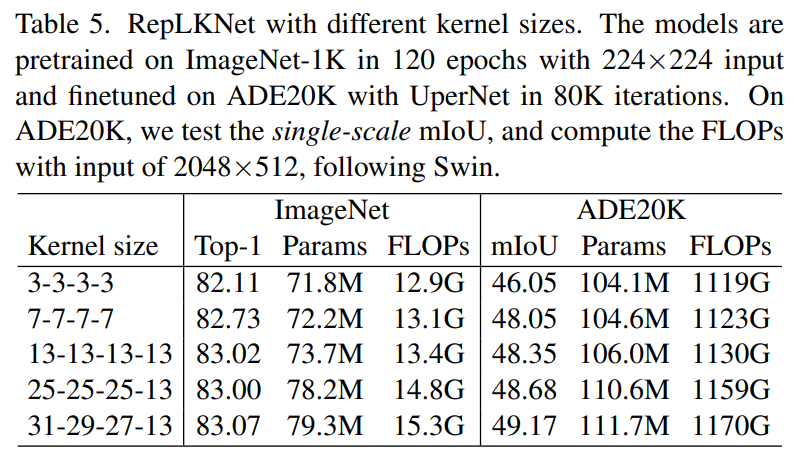
(如下表 5 所示,左边一栏表示模型四个 stage 各自的 kernel size)!
即便在大体量下游任务上,我们提出的超大卷积核模型 RepLKNet 与 Swin 等 Transformer 相比,性能也更好或相当!
![]()
论文地址:https://arxiv.org/abs/2203.06717
MegEngine 代码和模型:https://github.com/megvii-research/RepLKNet
PyTorch 代码和模型:https://github.com/DingXiaoH/RepLKNet-pytorch
![]()
A. 我们对业界关于 CNN 和 Transformer 的知识和理解有何贡献?
1. 超大卷积不但不涨点,而且还掉点?我们证明,
超大卷积在过去没人用,不代表其现在不能用
。人类对科学的认知总是螺旋上升的,在现代 CNN 设计(shortcut、重参数化等)的加持下,kernel size 越大越涨点!
2. 超大卷积效率很差?我们发现,
超大 depth-wise 卷积并不会增加多少 FLOPs。如果再加点底层优化,速度会更快,31x31 的计算密度最高可达 3x3 的 70 倍
!
3. 大卷积只能用在大 feature map 上?我们发现,
在 7x7 的 feature map 上用 13x13 卷积都能涨点
。
4. ImageNet 点数说明一切?我们发现,下游(目标检测、语义分割等)任务的性能可能跟 ImageNet 关系不大。
5. 超深 CNN(如 ResNet-152)堆叠大量 3x3,所以感受野很大?我们发现,
深层小 kernel 模型有效感受野其实很小。反而少量超大卷积核的有效感受野非常大
。
6. Transformers(ViT、Swin 等)在下游任务上性能强悍,是因为 self-attention(Query-Key-Value 的设计形式)本质更强?我们用超大卷积核验证,发现
kernel size 可能才是下游涨点的关键
。
1. 通过一系列探索性的实验,总结了在现代 CNN 中应用超大卷积核的五条准则:
用 depth-wise 超大卷积,最好再加底层优化(已集成进开源框架 MegEngine)
加 shortcut
用小卷积核做重参数化(即结构重参数化方法论,见我们去年的 RepVGG,参考文献 [1])
要看下游任务的性能,不能只看 ImageNet 点数高低
小 feature map 上也可以用大卷积,常规分辨率就能训大 kernel 模型
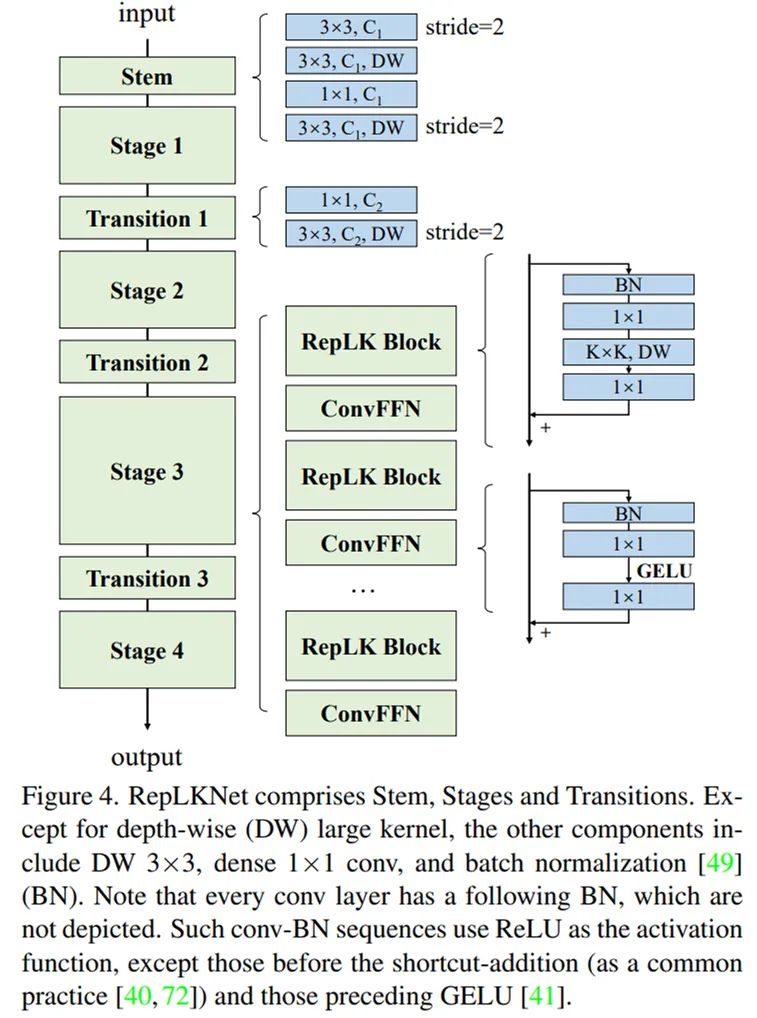
2. 基于以上准则,简单借鉴 Swin Transformer 的宏观架构,我们提出了一种架构 RepLKNet,其中大量使用超大卷积,如 27x27、31x31 等。这一架构的其他部分非常简单,都是 1x1 卷积、Batch Norm 等喜闻乐见的简单结构,不用任何 attention。
3. 基于超大卷积核,对
有效感受野、shape bias
(模型做决定的时候到底是看物体的形状还是看局部的纹理?)、
Transformers 之所以性能强悍
的原因等话题的讨论和分析。我们发现,ResNet-152 等传统深层小 kernel 模型的有效感受野其实不大,大 kernel 模型不但有效感受野更大而且更像人类(shape bias 高),Transformer 可能关键在于大 kernel 而不在于 self-attention 的具体形式。
例如,下图 1 分别表示 ResNet-101、ResNet-152、全为 13x13 的 RepLKNet、kernel 大到 31x31 的 RepLKNet 的有效感受野,可见较浅的大 kernel 模型的有效感受野非常大。
![]()
1. ImageNet 上,与 Swin-Base 相当。在额外数据训练下,超大量级模型最高达到 87.8% 的正确率。超大卷积核本来不是为刷 ImageNet 设计的,这个点数也算是可以让人满意。
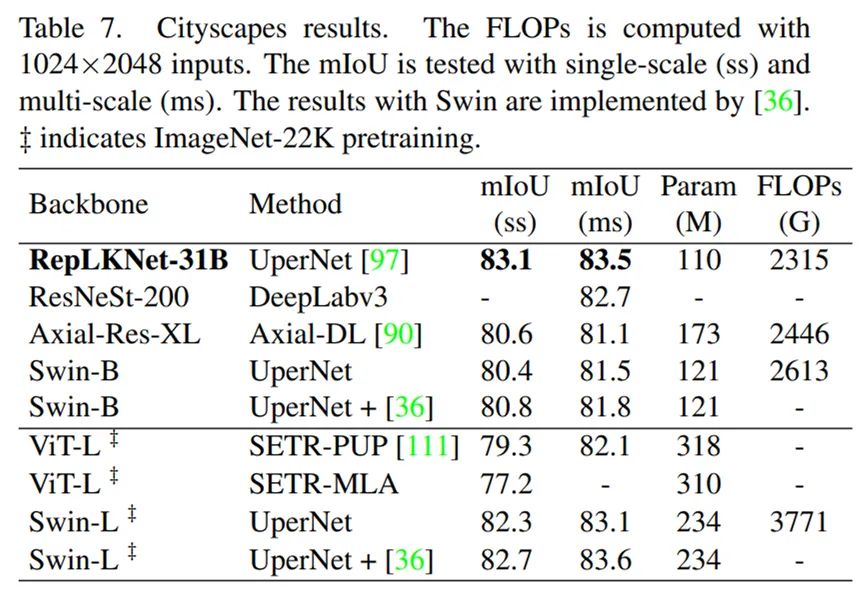
2. Cityscapes 语义分割上,仅用
ImageNet-1K pretrain 的 RepLKNet-Base
,甚至超过了
ImageNet-22K pretrain 的 Swin-Large
。这是
跨模型量级、跨数据量级的超越
。
3. ADE20K 语义分割上,ImageNet-1K pretrain 的模型大幅超过 ResNet、ResNeSt 等小 kernel 传统 CNN。
Base 级别模型显著超过 Swin
,Large 模型与 Swin 相当。超大量级模型达到
56% 的 mIoU
。
4. COCO 目标检测上,大幅超过同量级的传统模型 ResNeXt-101(
超了 4.4 的 mAP
),与 Swin 相当,在超大量级上达到
55.5% 的 mAP
。
初衷:我们为什么需要超大 kernel size?
在当今这个时代,我们再去研究听起来就很复古的大 kernel,是为什么呢?
1.
复兴被「错杀」的设计元素,为大 kernel 正名
。在历史上,AlexNet 曾经用过 11x11 卷积,但在 VGG 出现后,大 kernel 逐渐被淘汰了,这标志着
从浅而 kernel 大到深而 kernel 小的模型设计范式的转变
。这一转变的原因包括大家发现大 kernel 的效率差(卷积的参数量和计算量与 kernel size 的平方成正比)、加大 kernel size 反而精度变差等。但是时代变了,在历史上不 work 的大 kernel,在现代技术的加持下能不能 work 呢?
2.
克服传统的深层小 kernel 的 CNN 的固有缺陷
。我们
曾经相信
大 kernel 可以用若干小 kernel 来替换,比如一个 7x7 可以换成三个 3x3,这样速度更快(3x3x3< 1x7x7),效果更好(更深,非线性更多)。有的同学会想到,虽然深层小 kernel 的堆叠容易产生优化问题,但这个问题已经被 ResNet 解决了(ResNet-152 有 50 层 3x3 卷积),那么这种做法还有什么缺陷呢?——ResNet 解决这个问题的代价是,模型即便理论上的最大感受野很大,实质上的有效深度其实并不深(参考文献 2),所以有效感受野并不大。这也可能是传统 CNN 虽然在 ImageNet 上跟 Transformer 差不多,但在下游任务上普遍不如 Transformer 的原因。也就是说,ResNet 实质上帮助我们
回避
了「深层模型难以优化」的问题,而并没有真正解决它。
既然深而 kernel 小的模型有这样的本质问题,浅而 kernel 大的设计范式效果会如何呢
?
3.
理解 Transformer 之所以 work 的原因
。已知 Transformer 性能拔群,特别是在检测、分割等下游任务上。Transformer 的基本组件是 self-attention,而 self-attention 的实质是在
全局尺度或较大的窗口内
进行
Query-Key-Value 运算
。那么 Transformer 性能强悍的原因是什么,是
Query-Key-Value
的设计形式吗?我们猜测,会不会「
全局尺度或较大的窗口
」才是关键?对应到 CNN 中,这就需要用超大卷积核来验证。
为了搞明白大 kernel 到底应该怎么用,我们在 MobileNet V2 上进行了一系列探索实验,总结出五条准则。这里略去细节只说结论:
1.
用 depth-wise 大 kernel
,完全可以做到相当高效。在我们的优化(
已经集成进开源框架 MegEngine
)下,31x31 depth-wise 卷积的用时最低可达 3x3 卷积的 1.5 倍,而前者的 FLOPs 是后者的 106 倍(31x31/9),这意味着前者的效率是后者的 71 倍!
2. 不带 identity shortcut,增大 kernel 会大幅掉点(ImageNet 掉了 15%);
带 shortcut
,增大 kernel 才会涨点。
3. 如果要想进一步加大 kernel size,从大 kernel 到超大 kernel,可以
用小 kernel 做结构重参数化
(参考文献 1)。也就是说,在训练的时候并行地加一个 3x3 或 5x5 卷积,训练完成后将小 kernel 等价合并到大 kernel 里面去。这样,模型就可以有效捕捉到不同尺度的特征。不过我们发现,数据集越小、模型越小,重参数化越重要。反之,在我们的超大规模数据集 MegData73M 上,重参数化提升很小(0.1%)。这一发现跟 ViT 类似:数据规模越大,inductive bias 越不重要。
4. 我们要的是在目标任务上涨点,而不是 ImageNet 上涨点,
ImageNet 的精度跟下游任务不一定相关
。随着 kernel size 越来越大,ImageNet 上不再涨点,但是 Cityscapes、ADE20K 语义分割上还能涨一到两个点,而增大 kernel 带来的额外的参数量和计算量很少,性价比极高!
5. 有点反直觉的是,在 7x7 的小 feature map 上用 13x13 也可以涨点!也就是说,
大 kernel 模型不一定需要大分辨率来训
,跟小 kernel 模型差不多的训练方法就可以,又快又省!
我们以 Swin 作为主要的对比对象,并无意去刷 SOTA,所以简单借鉴 Swin 的宏观架构设计了一种超大卷积核架构。这一架构主要在于把 attention 换成超大卷积和与之配套的结构,再加一点 CNN 风格的改动。根据以上五条准则,RepLKNet 的设计元素包括 shortcut、depth-wise 超大 kernel、小 kernel 重参数化等。
![]()
我们给 RepLKNet 的四个 stage 设定不同的 kernel size,在 ImageNet 和 ADE20K 语义分割数据集上进行实验,结果颇为有趣:ImageNet 上从 7x7 增大到 13x13 还能涨点,但从 13x13 以后不再涨点;但是在 ADE20K 上,从四个 stage 均为 13 增大到四个 stage 分别为 31-29-27-13,涨了 0.82 的 mIoU,参数量只涨了 5.3%,FLOPs 只涨了 3.5%。
所以,后面的实验主要用 31-29-27-13 的 kernel size,称为 RepLKNet-31B,并将其整体加宽为 1.5 倍,称为 RepLKNet-31L。
![]()
RepLKNet-31B 的体量略小于 Swin-Base,在仅仅用 ImageNet-1K pretrain 前提下,mIoU 超过 Swin-Large + ImageNet-22K,完成了
跨模型量级、跨数据量级的超越
。
![]()
RepLKNet 相当能打,特别是 Base 级别。跟量级差不多的 ResNet 相比,
mIoU 高了 6.1
,体现出了少量大 kernel 相对于大量小 kernel 的显著优势。(COCO 目标检测上也有相同结论,RepLKNet-31B 的 mAP 比体量相当的 ResNeXt-101 高了
4.4
)RepLKNet-XL 是更大级别的模型,用私有数据集 MegData-73M 进行预训练,达到了
56.0 的 mIoU
(跟 ViT-L 相比,这个模型其实并不算很大)。
![]()
ImageNet 分类、COCO 目标检测结果参见「太长不看」部分或论文。
有效感受野:大 kernel 模型远超深层小 kernel 模型
我们可视化了 RepLKNet-31、RepLKNet-13(前文所说的每个 stage 都是 13x13 的模型)、ResNet-101、ResNet-152 的有效感受野(方法详见论文)发现 ResNet-101 的有效感受野其实很小,而且
ResNet-152 相对于 101 的提升也很小
;RepLKNet-13 的有效感受野很大,而 RepLKNet-31
通过增大 kernel size 进一步将有效感受野变得非常大
。
![]()
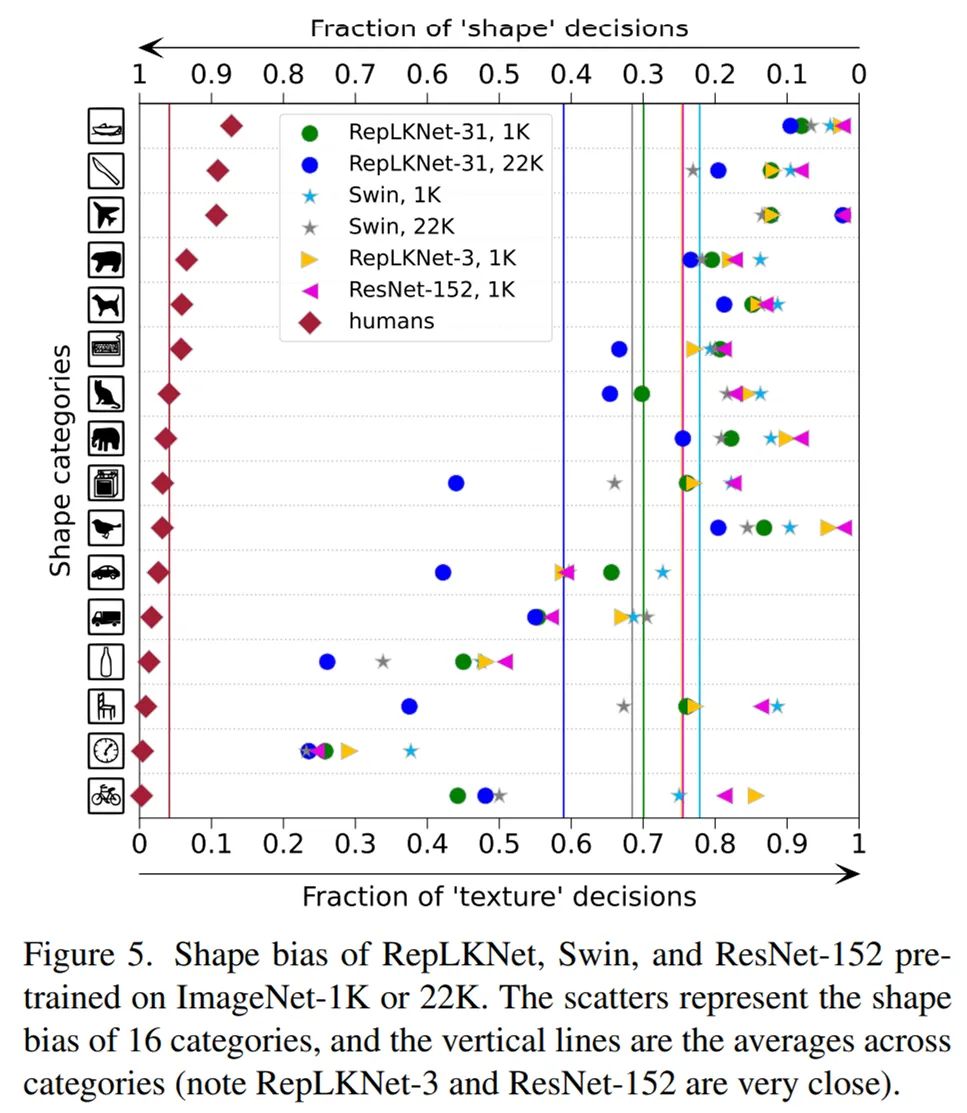
Shape bias:大 kernel 模型更像人类
我们又研究了模型的 shape bias(即模型有多少比例的预测是基于形状而非纹理做出的),
人类的 shape bias 在 90% 左右
,见下图左边的菱形点。我们选用的模型包括 Swin、ResNet152、RepLKNet-31 和 RepLKNet-3(前文提到的每个 stage 都是 3x3 的小 kernel baseline),发现 RepLKNet-3 和 ResNet-152 的 kernel size 一样大(3x3),shape bias 也非常接近(图中的两条竖直实线几乎重合)。
有意思的是,关于 shape bias 的一项工作提到 ViT(
全局 attention
)的 shapebias 很高(参见参考文献 3 中的图),而我们发现 Swin(
窗口内局部 attention
)的 shape bias 其实不高(下图),这似乎说明
attention 的形式不是关键,作用的范围才是关键
,这也解释了
RepLKNet-31 的高 shape bias(即更像人类)
。
![]()
MegEngine 对大 kernel 的强力优化
以往大家不喜欢用大 kernel 的其中一个原因是其较低的运行效率。但旷视开源的深度学习框架 MegEngine 通过分析和实验发现大 kernel depth-wise 卷积仍有很大的优化潜力,其运行时间可能不会显著慢于小 kernel(延展阅读 https://zhuanlan.zhihu.com/p/479182218)。
MegEngine 针对大 kernel depthwise 卷积做了多种深度优化,优化后的 MegEngine 性能比 PyTorch 最高快 10 倍,31x31 大小卷积核上的运行时间几乎和 9x9 大小卷积核的运行时间差不多,可以打满设备的浮点理论峰值。MegEngine 用实际数据在一定意义上打消了大家对大 kernel 卷积运行效率的疑虑。这些优化已经集成到了 MegEngine 中,欢迎使用~
知乎原文:https://zhuanlan.zhihu.com/p/481445076?utm_source=wechat_session&utm_medium=social&utm_oi=56560353017856&utm_campaign=shareopn
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com