论嵌入在 OpenAI 的 5v5 DOTA2 AI 中的妙用

AI 科技评论按:OpenAI 的 DOTA2 5v5 AI 「OpenAI Five」是人工智能界今年的一大亮点。作为「有挑战性的多智能体连续控制任务」、DOTA2 玩家们的课外娱乐活动,以及 OpenAI 自己的重要技术展示和宣传机会,OpenAI 不仅有数人的团队专门负责这个 AI 的研发调试,投入了 256 个 V100 GPU、128000 个 CPU、长达几个月的训练时间(高昂的成本),也前前后后请了许多 DOTA 爱好者及(前)职业选手参与测试和调试。
成果自然是可圈可点的。从比赛结果来看,OpenAI Five 不仅多次战胜了业余人类玩家和前职业选手团队,即便对战现役职业选手以及中国老职业选手们的比赛输了,也仍有积极主动、有一些还十分亮眼的表现;技术方面,OpenAI 不仅发现用相对简单的网络结构配合大规模分布式的先进算法就已经可以有不错的表现,也在训练过程设计、超参数选择、人类目标如何量化等方面有了许多心得。(参见往期文章 DOTA 5v5 AI 的亮点不是如何「学」的,而是如何「教」的)甚至后来 OpenAI 的 CTO Greg Brockman 都发推表示,他们根据比赛中的表现对模型又做一些更新,AI 的表现也来到了新的高峰。
如果深入探究的话,虽然 OpenAI 自己没有给出详细的模型设计解释,但是也有热心研究人员在查找资料,试图找到更多解释这个 AI 能有如此表现的原因。比如塔尔图大学计算机学院计算神经科学实验室的 Tambet Matiisen,他找到的其中一个重要原因,就是模型对嵌入的妙用。AI 科技评论把他的解析文章全文翻译如下。

虽然关于 OpenAI 的 AI 的举止以及关于这些比赛对于整个 AI 界的意义的讨论已经不少了,但关于这些 AI 的训练方法和网络架构的技术分析异常地少。到目前为止,技术分析主要都源于最初 OpenAI Five 的博客文章。在某种程度上他们确实说得挺合理,他们使用标准 PPO 算法(几年前他们自己发明的)和经过验证确实有效的自我训练方案(也在他们的论文 https://arxiv.org/abs/1710.03748 中记录)是合理的。但博客文章中有一个容易错过的细节,那就是指向他们的网络架构图的一个超链接。
在这篇博文中,我想集中讨论他们网络架构的一个方面,即他们创造性地使用嵌入来处理数量巨大并且可变的策略输入和输出。虽然嵌入以及注意力机制的点乘积的应用是自然语言处理中的标准技术,但它们并未广泛用于强化学习中。
更新:在撰写此博客文章后,我了解到后来的一篇 OpenAI 博客文章中有一个较新版本的网络架构图 http://t.cn/RDtrHx1 。由于嵌入的使用没有太多差异,我决定不重新更新这篇文章的图像了,新网络的分析可以作为大家的作业。
什么是嵌入?
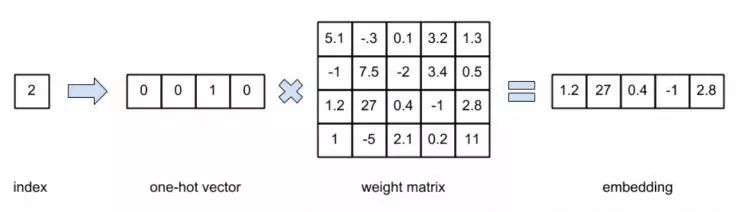
在数学中,嵌入指的是从空间 X 到 Y 的映射,同时保留对象的一些结构(例如它们的距离)。然而,在神经网络的上下文中使用嵌入通常意味着将分类(离散)变量(例如,单词索引)转换为连续向量。直接将单词索引作为输入传递给网络将使其工作变得非常困难,因为它需要为每个索引值都提供一个二进制特征(假设它们是不相关的)。于是,我们通过一个网络将分类值转换为 one-hot (独热)矢量。如果将独热矢量与权重矩阵相乘,这就相当于从权重矩阵中选择一个给定的行。在各类神经网络开发库中,通常会跳过转换为独热矢量并乘以权重矩阵的步骤,而是直接使用索引从权重矩阵中选择一行,并将其视为查找表。其中最重要的方面是,嵌入向量是通过学习得到的,就像使用独热向量学习权重矩阵一样。
自然语言处理是嵌入应用最有名的领域,其中单词索引被转换为词向量(或嵌入)。已经有充足的例子表明,当训练网络从字向量预测其周围单词的向量时,词向量就能学习到一些语义信息,并且它们之间可以进行算术运算。例如「woman - man + king」产生接近「queen」的矢量。你可以看作是「woman - man」产生性别转移向量,添加「king」将其转换为女性统治者。另一种理解方式是,你构造了「king - man + woman」,那么「king - man」产生「ruler」(统治者)的矢量,并添加「woman」产生「queen」。
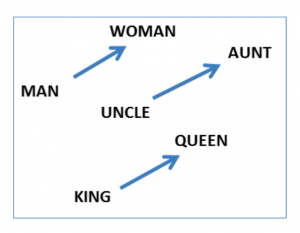
图片来自 https://www.aclweb.org/anthology/N13-1090
OpenAI Five 网络
在我们深入研究具体细节之前,先简单介绍一下 OpenAI Five 的总体网络架构。
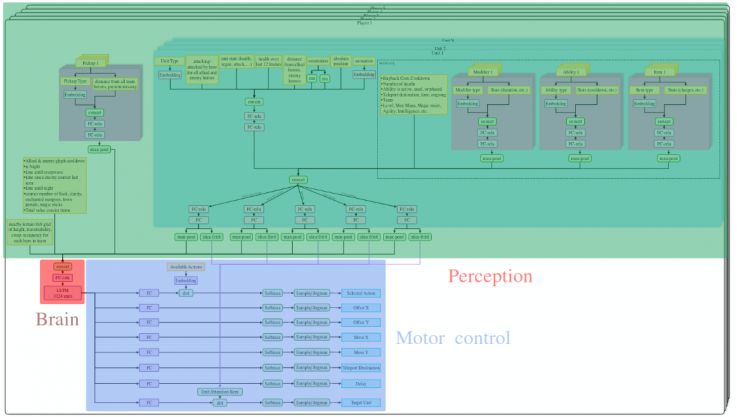
OpenAI Five 的五个 AI 玩家每一个都有自己单独网络,有自己的输入和动作。(不确定五个网络的参数是否共享。)五个 AI 之间唯一的联系是通过游戏,我个人开始想象他们会不会采用类似于「蜜蜂舞」的行为将敌人的位置传达给彼此,但我不认为他们真的会这样做,甚至不需要这样做。更新:在较新版本的网络中,AI 之间有一个共享的最大池化层,可以将其视为单向广播通信信道。
图中网络的上半部分处理观察结果。它将来自各种来源的数据连接起来,并将所有内容传递到一个 LSTM 单元格中。该 LSTM 单元的输出由网络的下半部分用于产生动作。简而言之,就是观察过程,将它们提供给 LSTM 并产生动作的一个简单过程。当然,细节决定一切,这将是我们在下一节中讨论的内容。
观察的嵌入
OpenAI Five 的 AI 使用 Dota 2 的 API 来「看到」周围的单位和建筑物。这会产生可变长度的单位列表(英雄,小兵,塔等)及其属性。OpenAI 在他们的博客文章中对观测空间和动作空间可视化做的很好,我建议大家去原博客里感受一下 https://blog.openai.com/openai-five/#dota-diagram 。


下图总结了对于列表中的某一个单位的处理过程。
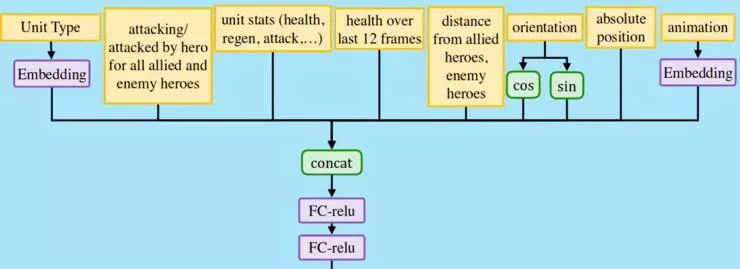
在左上方我们可以看到每个单位被编码成一个嵌入,这是完全可行的,因为 Dota2 中的 116 个英雄可以根据不同方式进行分类:
主要属性:力量,灵活性,智力。
攻击类型:远程或近战。
作用:核心,控制,对线辅助,先手,打野,辅助,耐久,爆发,推进,逃生。
其中的每一个特性都可能在嵌入向量中形成一个维度,并且网络可以自动学习每个英雄中的核心、辅助或打野的成分是多少。 相同的嵌入也适用于小兵和建筑物,例如塔也有远程攻击。这样就形成了一种通用的方式,在网络内表示各种不同的单位。嵌入向量与其他单位属性(如血量,英雄距离等)联系在一起。
嵌入不仅仅可以用于单位的类型,它们也用于天赋、技能和物品。
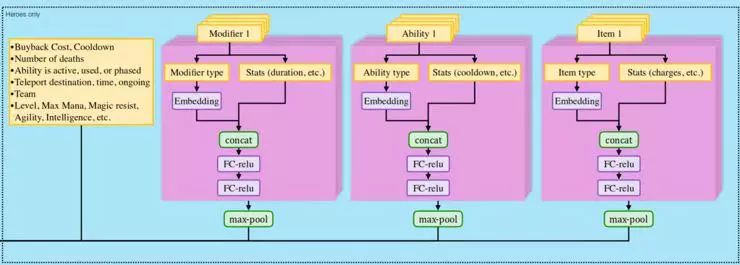
同样它也是有理可依的——虽然所有英雄的技能都不同,但它们肯定有一些共性,例如:他们的技能是主动施放还是被动,如果他们需要目标,那么这个目标是另一个单位还是一个区域等。对于物品的话,有用于治疗的血瓶,有增加魔法值的,有立即消耗的,还有用于升级的物品。嵌入是一种自然的方式,用来表示具有许多不同特性但可能有交叉特性的东西,以及表示那些在不同程度上可能具有相似效果的东西。
请注意,虽然天赋、技能和物品的数量是可变的,但最大池化层会覆盖到每个列表。这意味着只有所有这些维度中的最高值才能被输出。乍一看这样似乎不太合理,因为以人的思路来考虑的话,你拥有的能力是所有现有能力的组合,例如:远程+被动治疗。但它似乎对 AI 来说很有用。
以上处理是针对每个相邻的单位独立完成的,一般属性、英雄天赋、技能和物品的结果都会连接在一起。然后应用不同的后处理,根据它是敌方非英雄(如敌方塔)、友方非英雄(己方塔)、中立(野怪)、友方英雄或者敌方英雄。
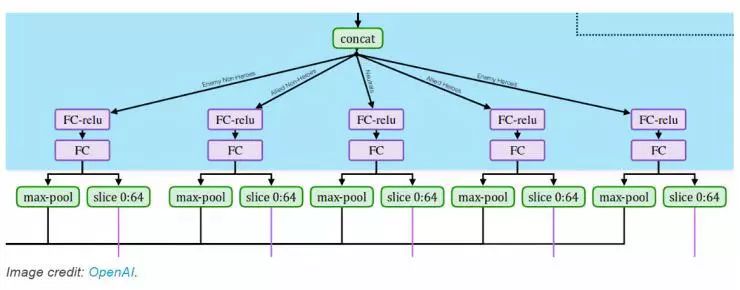
最后,后处理的结果在该类型的所有单元上取最大值。同样,乍一看这似乎是有问题的,因为邻近单元的不同特性会被组合,例如,如果其中一个维度代表一个单位的健康状况(血量),那么网络只会看到相同类型单位的最大健康状况。 但是,再一次,从模型的表现看来并不是不行。
最大池化将每种单元类型的最大结果连接起来,然后输入给 LSTM。输出的前半部分也有分片,不过下面我们讲到动作目标的时候再接着说这件事。
动作的嵌入
Dota 2 中大概有 170,000 个不同的动作,包括正常的动作,如移动和攻击,还包括技能施放、物品使用、状态升级等。在每个时间点上并非所有操作都可以使用——比如可能还没有学这个技能,或者背包里没有这个装备。但你仍然可以使用大约 1000 种不同的操作。此外,许多动作都有参数,例如你想要移动到什么区域或你想要攻击哪个敌人。OpenAI在博文中也展示了很好的动作空间的可视化。

这其实给强化学习带来了一个巨大的探索问题,因为智能体最初是通过尝试随机动作开始学习的。最直白的方法是计算所有 170,000 个动作的分数,并将 softmax 限制为 1000 个当前可以进行动作。但 OpenAI 通过嵌入和可变长度的 softmax 层巧妙地解决了这个难题。
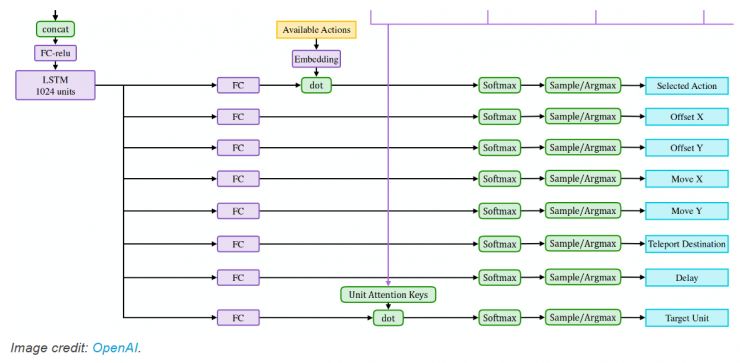
正如这张图最上方显示的,每个动作都有一个嵌入,例如,无论是远程攻击还是使用物品进行治疗或传送到某个目的地。动作嵌入和 LSTM 输出结果的点乘积用于产生不同动作的分数。这些分数会经过 softmax层,结果的概率分布用于选择一个可用的动作。
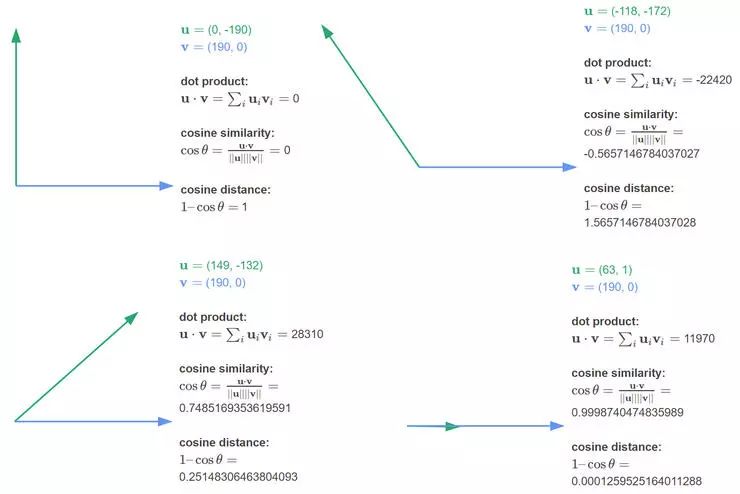
旁注:两个向量之间的点乘积会把向量中的元素分别相乘,并对相乘后的结果求和。有时它也被称为标量积,因为它产生单个标量值。它与余弦相似性有着密切的关系——当向量指向相同方向时,它倾向于产生高值,而当指向相反方向时,它往往产生低值。它通常用作两个向量相似性的快速评分方法。实际上,这正是卷积运算所做的——它产生了滤波器和输入之间相似性的特征图。
我猜测,选择一个行动的过程实际上是让 LSTM 产生的一个原则上可以被称为「意图向量」的东西。例如,如果你处于困境并且血量非常低,那么意图就是「离开这里」。将此意图与可用操作匹配,如果与其中一个操作相一致,则会产生高分。例如,「移动」和「TP」两个动作可能与「离开这里」的意图很好地对齐。TP 可能稍微对齐的更好些,因为你不会被敌人追到,因此它在 softmax 之后产生更高的分数和更高的概率。但是如果目前 TP 不可用,那么这种嵌入就不匹配了,「移动」可能是得分和概率最高的。
某些操作具有参数,如目的地或目标。所有这些都使用 softmax 层以简单直接的方式建模。例如,X 和 Y 坐标被离散化为范围,而不是使用连续输出和高斯分布。我猜测 softmax 可以更好地处理多模态分布。这里我们发现了一个重要的点是,动作输出似乎并不能对动作以及动作目标之间的联合分布建模。我认为这不是问题,因为所有动作输出都以 LSTM 输出为条件。因此,LSTM 输出已经编码了「意图」,而那些全连接层只是解码了这个「意图」的不同方面——动作及其目标。
我最喜欢的部分是 OpenAI Five 如何处理目标。还记得那些来自单位观测输出的奇怪切片吗?这些在图上用蓝色表示,这意味着它们是对每个单位都有一个单独的切片。这些向量称为「单元注意键」,并与 LSTM「意图」匹配,以产生对于每个单位的分数。这些分数通过 softmax 并确定攻击单位。选取被观察到的单位时再次使用了 softmax,从可用的动作的中选取动作的时候也是一样。
我猜测模型是这样工作的:根据观察的结果,网络确定某个单位的血量确实很低,AI 有机会去抢这个人头。LSTM 产生意图「尝试最后一击」,与「攻击」行动很好地对齐。此次「尝试最后一击」意图与观察处理的每单位输出相匹配,并与血量低的单位很好地对齐。Bang——你完成最后一击并获得额外的赏金。
更新:在更新版本的网络中,他们先用动作嵌入来调制 LSTM 输出,再使用单位注意键产生点乘积前,我猜如果不做这个更改的话,不同的动作(例如攻击和治疗)就会锁定到一个单位上去。
总结
在分析 OpenAI Five 网络之后,很明显网络的大多数部分都在处理感知(观察预处理)和运动控制(解码动作)任务。而所有战略和策略必须由同一个地方产生——即 1024 个神经元的 LSTM。
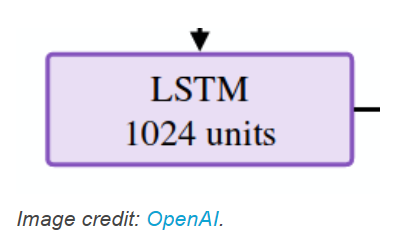
我认为这样一个相对简单的数学结构就可以产生如此复杂的行为是令人惊奇的。或者,我不是很确定,但是其实这表明 Dota 2游戏的复杂性也不过如此?短期策略与快速反应时间的结合已经可以击败长期策略了吗?
感谢 Jaan Aru,TanelPärnamaa,Roman Ring 和 Daniel Majoral 的提出的精彩见解和讨论。
via neuro.cs.ut.ee,AI 科技评论编译





