DeepMind高赞课程:24小时看完深度强化学习最新进展(视频)

新智元推荐
新智元推荐
来源:DeepMind & UCL
编辑:肖琴,文强
【新智元导读】一直走在深度学习研究最前沿的DeepMind,终于公开了它联合UCL的“高级深度强化学习课程”!18节课24小时,一天看完Deep RL及其2018最新进展。
今天,DeepMind 官推贴出一则告示,将 DeepMind 研究人员今年在 UCL 教授的深度强化学习课程“Advanced Deep Learning and Reinforcement Learning” 资源全部公开。
一共18节课,走过路过不能错过。

深度强化学习是人工智能领域的一个新的研究热点,从AlphaGo开始,DeepMind便在这一领域独占鳌头。
深度强化学习以一种通用的形式将深度学习的感知能力与强化学习的决策能力相结合,并能够通过端对端的学习方式实现从原始输入到输出的直接控制。自提出以来, 在许多需要感知高维度原始输入数据和决策控制的任务中都取得了实质性的突破。
2018年,南京大学的AI单机训练一天,击败《星际争霸》最高难度内置Bot,OpenAI 打 DOTA2 超越了Top 1%的人类玩家,深度强化学习不断在进展。
结合算法的发展和实际应用场景,DeepMind在UCL教授的这门课程内容也是最前沿的。
还有关键一点,那就是视频的质量和清晰度超赞啊(需要科学上网)。
这门课程是DeepMind与伦敦大学学院(UCL)的合作项目,由于DeepMind的研究人员去UCL授课,内容由两部分组成,一是深度学习(利用深度神经网络进行机器学习),二是强化学习(利用强化学习进行预测和控制),最后两条线结合在一起,也就成了DeepMind的拿手好戏——深度强化学习。
关于深度强化学习,DeepMind一直在努力,比如最新发表的研究让 AI 行动符合人类意图。
这门课也是结合案例讲解的,值得一提,最后一课“第18节:深度强化学习的经典案例”,讲师是 David Silver,这位AlphaGo背后的英雄以及AlphaZero灵魂人物,他讲的课程无论如何也应该听一听。

David Silver在UCL讲课的视频截图
在深度学习部分,课程简要介绍了神经网络和使用TensorFlow的监督学习,然后讲授卷积神经网络、递归神经网络、端到端并基于能量的学习、优化方法、无监督学习以及注意力和记忆。讨论的应用领域包括对象识别和自然语言处理。
强化学习部分将涵盖马尔科夫决策过程、动态规划、无模型预测和控制、价值函数逼近、策略梯度方法、学习与规划的集成以及探索/开发困境。讨论的可能应用包括学习玩经典的棋盘游戏和电子游戏。
总体来说,这是一门偏向实践的课程,需要PyTorch和编码基础,学完以后,学生能够在TensorFlow上熟练实现深度学习、强化学习以及深度强化学习相关的一系列算法。
因此,除了深度学习、强化学习和深度强化学习的基础知识,深度神经网络的训练以及优化方法,这门课更加注重如何在TensorFlow中实现深度学习算法,以及如何在复杂动态环境中应用强化学习。

课程团队
深度学习1:介绍基于机器学习的AI
深度学习2:介绍TensorFlow
深度学习3:神经网络基础
强化学习1:强化学习简介
强化学习2:开发和利用
强化学习3:马尔科夫决策过程和动态编程
强化学习4:无模型的预测和控制
深度学习4:图像识别、端到端学习和Embeddings之外
强化学习5:函数逼近和深度强化学习
强化学习6:策略梯度和Actor Critics
深度学习5:机器学习的优化方法
强化学习7:规划和模型
深度学习6:NLP的深度学习
强化学习8:深度强化学习中的高级话题
深度学习7:深度学习中的注意力和记忆
强化学习9:深度RL智能体简史
深度学习8:无监督学习和生成式模型
强化学习10:经典游戏的案例学习
下面我们介绍第14节“深度强化学习中的高级话题”。讲课人是DeepMind研究科学家Hado Van Hasselt。Hado Van Hasselt的研究兴趣包括人工智能、机器学习、深度学习,尤其是强化学习。加入DeepMind之前,他在阿尔伯塔大学与Richard Sutton教授合作过。
Hado Van Hasselt是许多前沿论文的共同作者,包括Double Q-learning、Dueling DQN、rainbow DQN、强化学习的Ensemble算法等。
第14节视频

在这一节,Hasselt讲了深度强化学习中一些积极的研究主题,这些主题很好地突出了这一领域中正在取得的进展。

前面已经介绍过的强化学习研究主题包括:学习在bandit问题中做决策;序列决策问题;model-free的预测和控制;deep RL中的函数逼近;策略梯度和actor-critic方法;以及从模型中学习。

而高级话题,是这些。
最主要的问题是:如何将未来的奖励最大化?
这个大问题可以分解成一些子问题:
学习什么?(预测、模型、策略……)
如何学习这些?(TD、规划……)
如何表示这些学习到的知识?(深度网络、sample buffers,……)
如何利用这些学习到的知识?
其中一些活跃研究主题包括:
在完全序列,函数逼近设置中的“探索”(Exploration)
利用延迟奖励的credit assignment
局部规划或不精确的模型
样本效率模型
Appropriate generalization
构建有用、通用且信息丰富的agent state

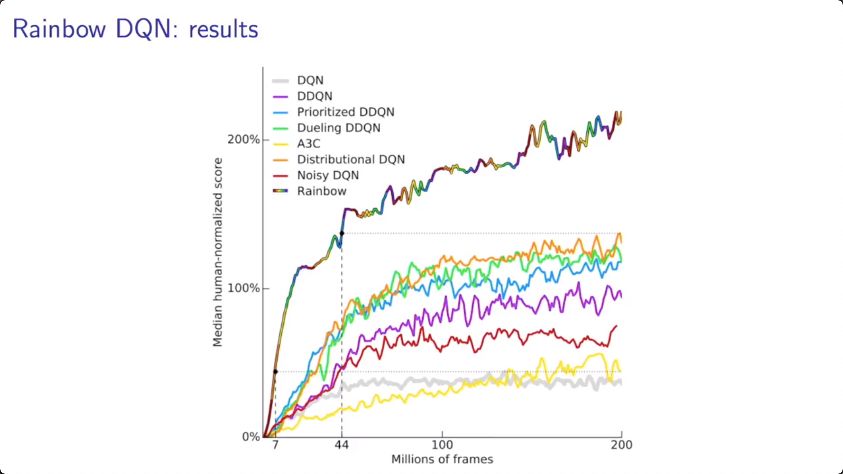
Case study:rainbow DQN(Hasselt et al. 2018)
在这个研究中,Hasselt等人提出rainbow DQN,整合了DQN算法的6种变体,并证明它们很大程度上是互补。DQN的基本想法是利用target networks和experience replay。
这节课接下来的大部分内容围绕这个case,介绍了最新的技术和思想,请观看视频获得更详细的解释。



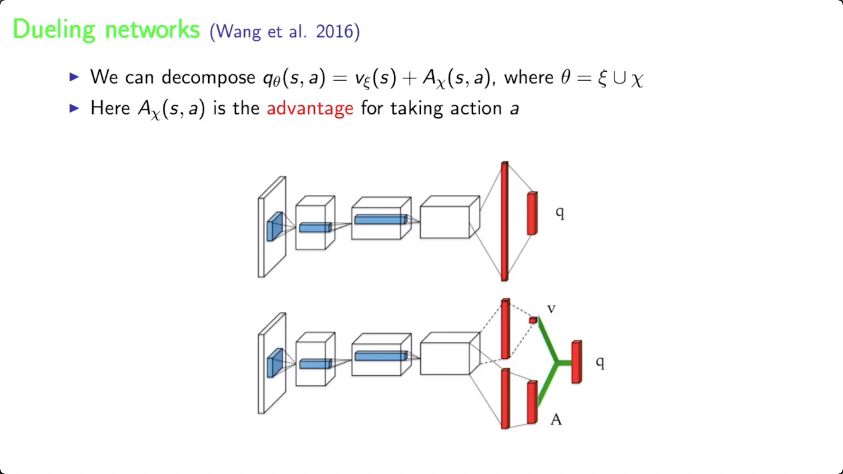

理解了分布(distribution),或许能对任务有所帮助。这是分布式强化学习的想法。分布式强化学习也意味着representation(例如深度神经网络)被迫要学习更多。
这可以加快学习:因为学习更多意味着更少的样本。
以下是分布式强化学习的具体案例。






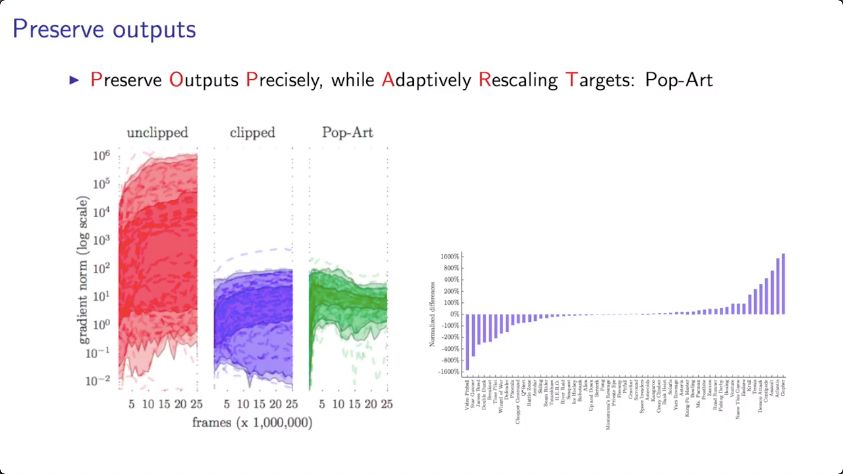
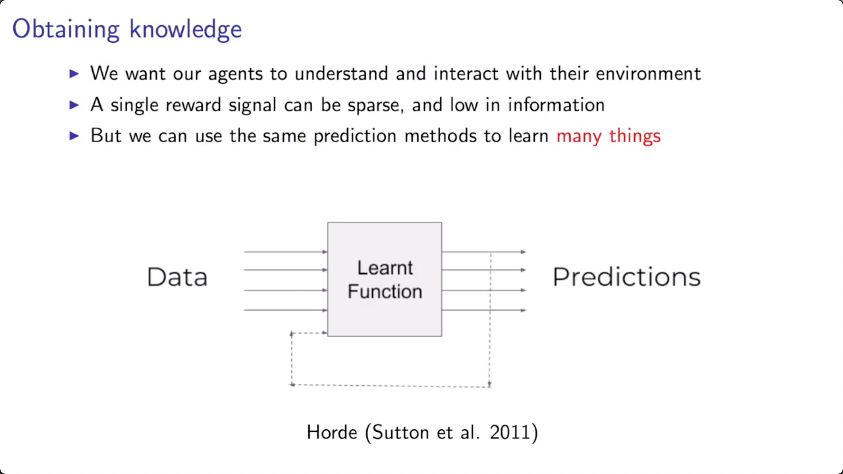

全部视频列表:
https://www.youtube.com/playlist?list=PLqYmG7hTraZDNJre23vqCGIVpfZ_K2RZs
【加入社群】
新智元 AI 技术 + 产业社群招募中,欢迎对 AI 技术 + 产业落地感兴趣的同学,加小助手微信号:aiera2015_2 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。




