一张图看懂AlphaGo Zero

编辑 | Vincent
编译 | 陈利鑫
更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)

上图是根据在《自然》上发表的文章绘制,解释了 AlphaGo Zero 是怎样将深度学习和蒙特卡洛树搜索结合,使之具有超强的强化学习算法能力。
简单来说,AlphaGo Zero 的训练可以分为三个同时进行的阶段:自我对战、再训练网络、评估网络。
在自我对战阶段, AlphaGo Zero 创建一个训练集合,自我完成对战 25000 次。棋局每变动一次,博弈、搜索可能性和胜出者的信息将被存储。
训练网络阶段,是神经网络权值得到优化的过程。在一次完整的训练循环中, AlphaGo Zero 将从 50 万局博弈中选取 2048 个移动位置作为样品,并对这些位置的神经网络进行训练。之后,通过损失函数,来对比神经网络预测与搜索可能性和实际胜出方的信息。每完成一千次这样的训练循环,就对神经网络进行一次评估。
在评估网络阶段,测试新的神经网络是否得到优化。在这个过程中,博弈双方都通过各自的神经网络评估叶节点,并使用蒙特卡洛树搜索进行下一步棋路的选择。
这样,在没有任何人类专业知识和数据输入的情况下,AlphaGo Zero 完成了了神经网络的“自学”过程。
目前,人类的专业知识资源相对昂贵,可靠性具有不确定性,而且获取难度较大,AI 的目的之一,就包括克服这个难题,发现在无需巨大人力投入前提下,可执行庞大计算的解决方案。
进阶版 AlphaGo Zero 的出世,让人类离这个目标更近了一些。这个版本比 AlphaGo 更加强大,后者在经过人类业余和专业围棋选家数千次对战训练之后,才学会如何玩围棋。而 AlphaGo Zero 直接跳过这些步骤,从随机对战开始,靠自身对战就学会博弈。

AlphaGo Zero 并没有被输入围棋比赛相关知识,仅了解简单的游戏规则,但其在 3 天内即超越曾打败世界围棋冠军李世石的 AlphaGo Lee,21 天超越曾战胜 60 位全球最顶尖专业围棋选手和柯洁的 AlphaGo Master,40 天后超越另一版本的 AlphaGo,成为迄今为止最强大的 AlphaGo。
视频链接:https://v.qq.com/x/page/i05626amo4e.html
与之前版本的 AlphaGo 相比,AlphaGo Zero 性能更优,凭借新型的强化学习方法,AlphaGo Zero 成为自身的“老师”。这个系统通过对围棋游戏一无所知的神经网络,结合强大的搜索算法,自学博弈。在对战过程中,神经网络可以感知并预测对手的下一步动作。
总而言之,AlphaGo Zero 之所以比之前版本更加强大,是因为其不受人类知识的限制,而是能够从世界上最强大的玩家——自身,学习并发明自己的战略。
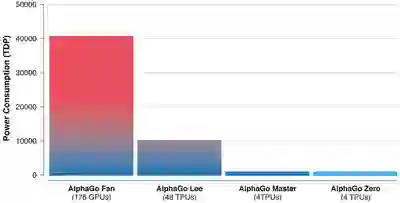
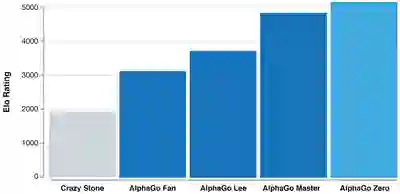
在 AlphaGo 和 AlphaGo Zero 的数百万次对战中,AlphaGo Zero 不断从博弈中学习,在几天之内就将人类数千年凝聚的智慧学到手。不仅如此,AlphaGo Zero 还发现了新的知识,在对战中创造了自己的策略和创新性的招数。
AlphaGo Zero 的创新性“举动”,一定程度上证明了 AI 可以超越人类的智慧,帮助人类解决困难和挑战,更多 AI 技术如果在蛋白质折叠、减少能源消耗、发现新材料等领域得到突破性的应用,将会对社会产生巨大的积极影响。






