【干货】Entity Embeddings : 利用深度学习训练结构化数据的实体嵌入
【导读】本文是数据科学家Rutger Ruizendaal撰写的一篇技术博客,文章提出深度学习在非结构数据中有不错的表现,当前通过实体嵌入也可以使之在结构化数据中大放异彩。具体讲解了如何利用深度学习训练结构化数据的实体嵌入,并且讨论了Entity Embeddings的各种优势:稠密向量、计算类别距离等。文末介绍了用t-SNE进行Embeddings可视化的两个实例。接下来让我们来看一下Entity Embeddings的独特之处吧。
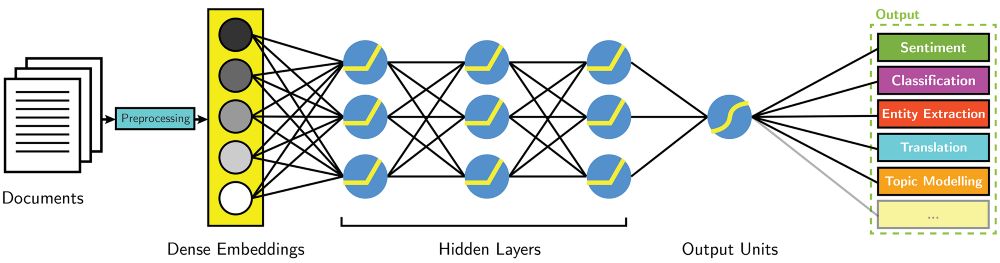
利用实体嵌入(Entity Embeddings)对结构化数据进行深度学习
向您展示深度学习可以处理结构化数据并且如何实现
作者首页:
http://www.rutgerruizendaal.com
嵌入的想法来自他们在NLP(word2vec)中的单词学习,这是从Aylien获得的图像
在本博客中,我们将着重介绍机器学习中两个不断重复出现的问题:第一个问题: 深度学习在处理文本和图像数据时的表现的不错, 但深度学习该怎么处理列表(tabular)数据呢? 第二个问题是在我们在构建机器学习模型的时候时常问的问题: 我改怎么处理数据集里的类别变量? 令人惊讶的是,我们可以用相同的答案回答这两个问题:实体嵌入(Entity Embedding)。
深度学习在许多方面都优于其他机器学习方法,图像识别,音频分类和自然语言处理仅仅是众多例子中的一部分。 这些研究领域都使用所谓的“非结构化数据”,即没有预定义结构的数据。 深度学习已成为处理非结构化数据的标准。但是深度学习是否也可以在结构化数据上有好的表现? 结构化数据是以表格格式组织的数据,其中列表示不同的特征,行表示不同的数据样本。这与数据在Excel工作表中的表现方式类似。 目前,结构化数据集的黄金标准是梯度增强树(GBDT)模型(Gradient Boosted Tree models , Chen&Guestrin,2016)。 特别的, 这一模型在Kaggle比赛以及学术文献中一直表现最好。 近期, 深度学习已经证明它在结构化数据上可以达到这些GBDT模型的性能。 实体嵌入在此扮演重要角色。
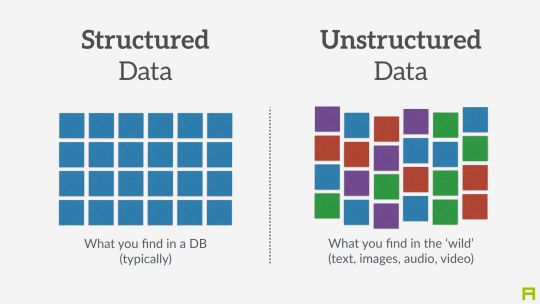
结构化数据VS非结构化数据
▌实体嵌入
在结构化数据上运用神经网络时,实体嵌入表现的很好。 例如,在Kaggle竞赛”预测出租车的距离问题”上获胜的解决方案,就是使用实体嵌入来处理每次乘坐的分类元数据(de Brébissonet al.,2015)。 同样,预测Rossmann药店销售任务的第三个解决方案使用了比前两个方案更简单的方法: 使用简单的前馈神经网络, 再加上类别变量的实体嵌入。它包括超过1000个类别的变量,如商店ID(Guo&Berkahn,2016)。
如果这是您第一次阅读有关嵌入(embeddings)的内容,我建议您先阅读这篇文章(https://towardsdatascience.com/deep-learning-4-embedding-layers-f9a02d55ac12)。简而言之,嵌入(embeddings)是把类别表示成向量。 让我们来演示一下下面这个短句是如何工作的:
“Deep learning is deep”
我们可以用向量来表示每个单词,因此“deep”这个单词变成了[0.20,0.82,0.45,0.67]。 在实践中,人们会用像1 2 3 1这样的整数来替换单词,并使用查找表来查找链接到每个整数的矢量。 这种做法在自然语言处理中非常常见,还能用于处理包含行为序列的数据,如在线用户的浏览记录。实体嵌入是指在分类变量上使用此原则,其中分类变量的每个类别都由向量表示。 让我们快速回顾一下在机器学习中处理分类变量的两种常用方法。
One-hot编码:创建二进制子特征,如word_deep,word_learning,word_is。 对于属于该数据点的类别,其值为1,其他值为0。 所以,对于“deep”这个词,特征word_deep将是1,并且word_learning,word_is等将是0。
标签编码(label encoding):像之前的例子中那样分配id,deep变为1,learning变为2等。这种方法适用于基于树的方法,但不适用于线性模型,因为它分配id的时候, 隐含了次序。
实体嵌入基本上将标签编码方法带到下一个层次,它不是将一个整数分配给一个类别,而是整个向量。 这个向量可以是任何大小,必须由研究人员指定。这么做有几个优点:
1. 实体嵌入解决了one-hot编码的缺点。如果类别过的的话one-hot编码会非常稀疏,导致计算不准确,并且使得难以达到最优。标签编码也解决了这个问题,但只能用于基于树的模型。
2. 嵌入提供有关不同类别之间距离的信息。 使用嵌入的优点在于,分配给每个类别的向量也在神经网络的训练期间被训练。 因此,在训练过程结束时,我们最终会得到一个代表每个类别的向量。 这些经过训练的嵌入(embeddings)可以被可视化,以提供对每个类别的解释。 在Rossmann销售预测任务中,德国国家的可视化嵌入显示了与各州地理位置相似的集群,即使这个地理信息没有提供给模型。
3. 训练好的嵌入(embeddings)可以保存并用于非深度学习模型。 例如,你可以一个月训练一次嵌入(embeddings)的分类特征, 然后保存嵌入(embeddings)。 之后,只需要加载学习到的分类特征的嵌入(embeddings),就可以使用这些嵌入(embeddings)来训练随机森林或梯度增强树模型。
▌选择嵌入(embeddings)的大小(size)
嵌入(embeddings)大小是指表示每个类别的向量的维度。 类似于神经网络中超参数的调整过程,选择嵌入(embeddings)的大小没有硬性规则。 在”出租车距离预测”任务中,研究人员使用每个特征的嵌入尺寸大小为10。 这些特征具有从7(一周中的某一天)到57106(客户端ID)的不同维度。 为每个类别选择相同的embeddings大小是一种简单明了的方法,但可能不是最优方法。
对于Rossmann商店销售预测任务,研究人员选择1和M-1之间的值(M为类别数量),最大embeddings大小为10.例如,一周中的某天(7个值)的嵌入大小为6, 而商店ID(1115个值)的嵌入大小为10.但是,对于选择1和M-1之间大小,作者没有给出明确的规则。
Jeremy Howard重建了Rossmann竞赛的解决方案,并提出了以下解决方案来选择嵌入尺寸:
# c is the amount of categories per feature
embedding_size = (c+1) // 2
if embedding_size > 50:
embedding_size = 50
▌可视化嵌入(Embeddings)
嵌入(Embeddings)的一个优点是已经学习的Embeddings可以被可视化以显示哪些类别彼此相似。 最流行的可视化方法是t-SNE,它是一种降维技术,特别适用于高维数据集的可视化。让我们看一下两个可视化嵌入例子。以下是可视化嵌入(Embeddings)家得宝公司的产品及其该产品所属类别。 相似的产品,如烤箱、冰箱和微波炉非常接近。 对于充电器、电池和钻头等产品也是如此。
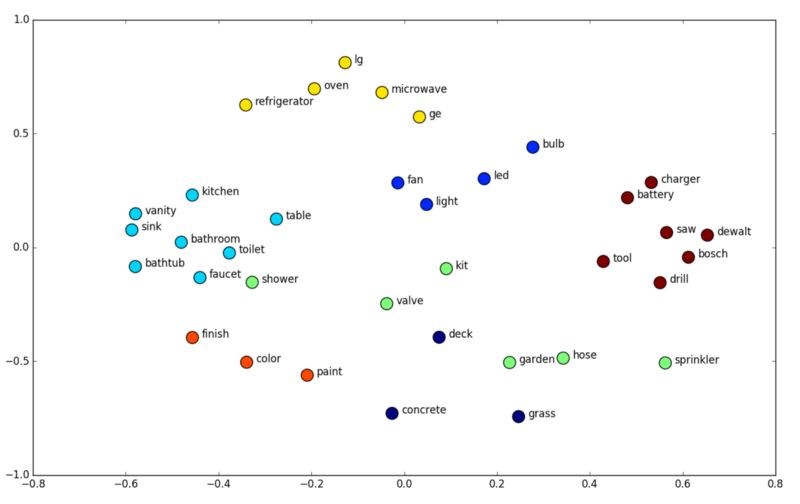
经过学习的家用产品的嵌入(Embeddings)
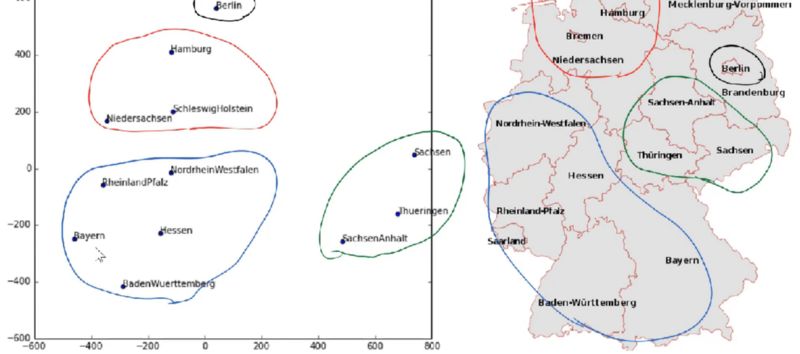
另一个例子是从Rossmann销售预测任务中学习的德国各个州的Embeddings。Embeddings中之间的邻近程度与它们的地理位置相似。
▌深度学习系列的其余部分:
1、Setting up AWS & Image Recognition
2、Convolutional Neural Networks
3、More on CNNs & Handling Overfitting
4、Why You Need to Start Using Embedding Layers
链接:
https://medium.com/towards-data-science/deep-learning-1-1a7e7d9e3c07
https://medium.com/towards-data-science/deep-learning-2-f81ebe632d5c
https://medium.com/towards-data-science/deep-learning-3-more-on-cnns-handling-overfitting-2bd5d99abe5d
https://towardsdatascience.com/deep-learning-4-embedding-layers-f9a02d55ac12
▌参考文献
Chen, T., & Guestrin, C. (2016, August). Xgboost: A scalable tree
boosting system. In Proceedings of the 22nd acm sigkdd international
conference on knowledge discovery and data mining (pp. 785–794).
ACM.
De Brébisson, A., Simon, É., Auvolat, A., Vincent, P., & Bengio, Y.
(2015). Artibcial neural networks applied to taxi destination
prediction. arXiv preprint arXiv:1508.00021.
Guo, C., & Berkhahn, F. (2016). Entity embeddings of categorical
variables. arXiv preprint arXiv:1604.06737.
参考文献:
https://towardsdatascience.com/deep-learning-structured-data-8d6a278f3088
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知

