开发者正广泛使用 AI 代码生成模型,以提升生产力与效率。然而,人们也对 AI 生成代码的质量提出了担忧。此类生成代码来自于在公开可用代码上训练的模型,而这些公开代码已知包含缺陷与质量问题。这些问题可能在开发过程中引发信任与维护方面的挑战。已有研究报告了多种与 AI 生成代码相关的质量问题,包括 bug 和缺陷。然而,这些发现通常分散,缺乏系统化的总结。目前仍缺乏一项全面的综述来揭示这些错误的类型与分布、可能的修复策略,以及它们与具体模型之间的关联。
在本文中,我们系统性地分析了现有关于 AI 生成代码的研究文献,以建立对生成代码中 bug 与缺陷的整体认识,为未来的模型改进与质量评估提供参考。我们的目标是理解 AI 生成代码中 bug 的性质与程度,并给出不同模型生成代码中 bug 类型与模式的分类。此外,我们还讨论了用于消除生成代码中 bug 的可能修复与缓解策略。
1 引言
由 AI 驱动的代码生成工具正在重塑软件开发。代码生成是近期关键 AI 技术——大语言模型(LLMs)——快速发展中的重要受益者。这类模型通过迁移学习,从现有代码示例中学习[137],随后能够基于自然语言描述或其他编程上下文生成代码。AI 代码生成工具已成为开发者的重要资源,通过自动化编码任务、提供代码片段建议[155]、代码补全[159]、代码翻译[146],甚至协助程序调试[79, 85]与修复流程[110, 121],显著提升了开发效率。最新的开发者调研显示,绝大多数开发者已在实际开发中广泛采用代码生成工具[100]。近年来也出现了多种代码生成模型,每种模型均面向软件开发流程中的不同阶段提供独特的功能与能力,例如 GPT 系列[98]、Claude[7]、Gemini[132]、Llama[113]、DeepSeek-Coder[54] 等。
尽管 AI 代码生成模型在多项代码相关任务上展现出杰出的性能,但仍存在一些关键挑战[24, 72]。AI 生成代码的准确性与正确性依然令人担忧[30],因为此类代码常常包含缺陷[128, 157]与安全漏洞[52, 86, 141]。这些缺陷往往源于模型的训练数据来自 GitHub、Stack Overflow 等公共代码仓库及其他编程平台,而这些平台中的公开代码已知存在 bug[108] 与安全问题[111]。这些缺陷可能导致运行时崩溃或意外行为[103],从而增加开发者的调试与修复工作量、降低生产效率,并可能延误项目进度、带来额外成本[136]。此外,AI 生成代码还常常缺乏可读性与一致性[32],例如使用非标准命名规范或未遵循团队代码风格[82],从而对软件可维护性产生负面影响。
为应对日益增长的关于 AI 生成代码可靠性的担忧,现有研究已经从多个角度探讨了生成代码的正确性[30]与代码质量[82]。这些研究针对不同模型、编程语言以及特定 bug 类别,评估了生成代码在多种场景下的质量表现。然而,这些研究碎片化严重,每项研究通常聚焦于某一孤立维度,例如特定模型类型、特定 bug 类型,或某一领域的使用场景。因此,我们仍然缺乏对 AI 生成代码中 bug 类型、模式与根因的整体性、系统化理解。在代码生成模型快速走向实际软件开发流程的当下,对这些研究结果的综合性梳理尤为关键。如果没有统一视角来理解这些反复出现的失败模式及其影响,就难以构建有效的评估框架、制定针对性的缓解策略,或设计更加稳健与可靠的模型。此外,识别跨模型的通用 bug 模式与失败机理,可能揭示出迄今为止由于研究割裂而未被察觉的系统性弱点。
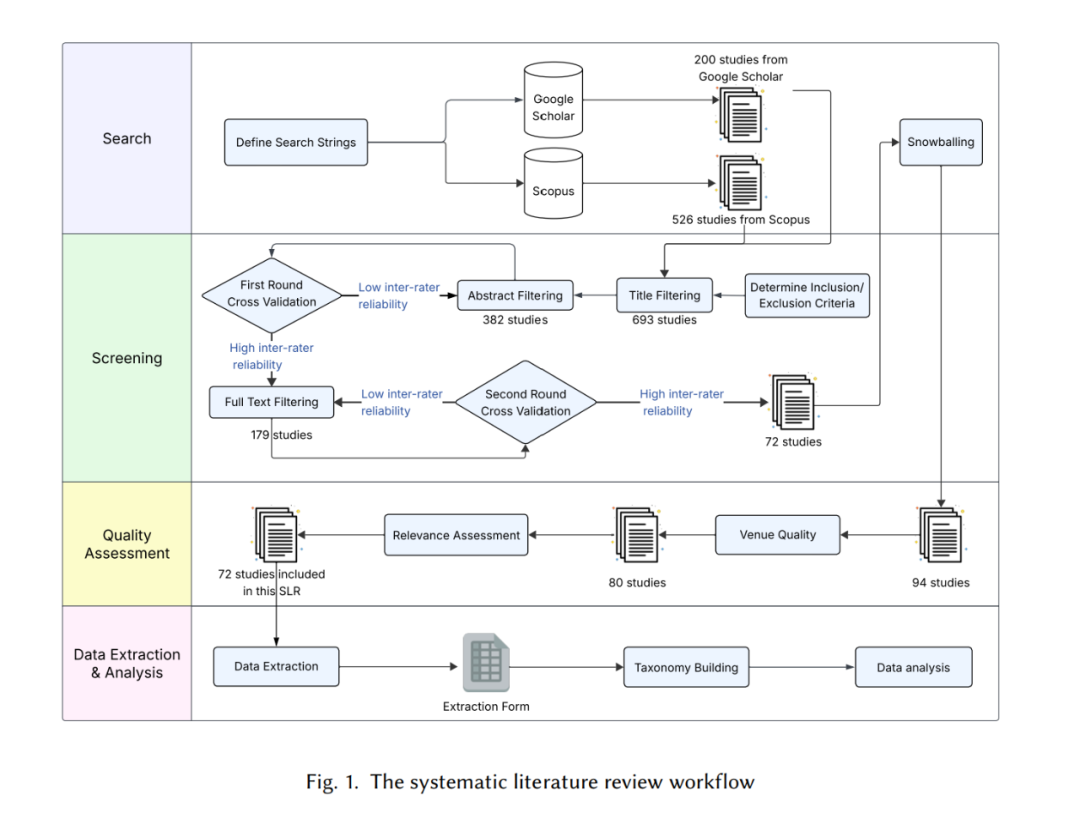
为弥补这一关键空缺,本文提出了首个关于 AI 生成代码缺陷的系统性文献综述(SLR)。我们的目标是汇总并分析既有实证研究结果,揭示常见 bug 类型、反复出现的模式、易生成缺陷的 AI 模型及其潜在成因。我们还探讨了现有研究中用于处理这些缺陷的修复与缓解策略,并评估这些方法在不同情境下的适用性。本综述为理解 AI 生成代码的失败生态提供了一项亟需的基础工作,为研究者和实践者改进当前与未来的代码生成模型的可靠性提供可操作的洞见。
本综述的主要贡献如下:
对 72 篇有关 AI 生成代码缺陷的研究进行了深入回顾,全面总结了所涉及的编程语言、数据集、缺陷检测方法、缺陷类型、AI 模型以及用于缓解缺陷的相关方法。
构建了 AI 生成代码缺陷的全面分类体系,为未来研究与对比分析提供结构化框架。
分析了不同 AI 模型生成缺陷代码的倾向及其背后的潜在原因。
分析了现有的缺陷缓解方法,并提出了未来研究建议。