【导读】最近全国人们都在众志成城抗击新冠毒肺炎疫情,春节马上过去,疫情还比较严重,还是呆在家里好好学习吧!今天Google大脑研究团队发布了最新对话AI的研究成果,一个有26亿参数的端到端训练的神经会话模型-Meena聊天机器人,能够产生比肩人类的会话质量,可达到79%的开放域聊天满意度。来看看这篇研究成果,然后利用假期看下这篇论文。

摘要
我们介绍了Meena,一个多回合的开放域聊天机器人,它根据从公共域社交媒体对话中挖掘和过滤的数据进行端到端的训练。这个26亿的参数神经网络被训练来最小化困惑度,这是一个我们用来与人类判断的多回合对话质量进行比较的自动度量。为了捕捉这种判断,我们提出了一种新的人工评价指标,称为意义度Sensibleness 和具体度平均(SSA),它捕捉了良好交谈的关键元素。有趣的是,我们的实验显示了perplexity和SSA之间很强的相关性。如果我们能够更好地优化perplexity,端到端训练的最佳perplexity在SSA中的得分(多轮评估中为72%)表明86%的人类水平SSA是可以达到的。此外,完整版的Meena(带有过滤机制和调谐解码)得分79%,比我们评估的排名第二的聊天机器人高23%。
现代会话代理(聊天机器人)趋向于高度专门化——只要用户聊的内容不偏离其设定范围太远,它们就会表现得很好。为了更好地处理各种会话主题,开放域对话研究探索了一种互补的方法,试图开发一个聊天机器人,它不是专门的,但仍然可以谈论几乎任何用户想聊的东西。除了是一个令人着迷的研究课题外,这种对话机器人还可以带来许多有趣的应用,如进一步使计算机交互更加人性化,提高外语实践,以及制作相关的交互式电影和视频游戏角色。
然而,当前的开放域聊天机器人有一个严重的缺陷——它们说的很多通常没有意义。他们有时会说一些与目前所说的不一致的事情,或者缺乏对世界的常识和基本知识。此外,聊天机器人通常给出的响应并不与当前上下文相关。例如,“我不知道”是对任何问题的合理回答,但并不具体。目前的聊天机器人相比人类的表现经常这样做,因为它能够涵盖许多用户会话的回应。
在“向类人开放域聊天机器人”中,我们介绍了Meena,一个有26亿参数的端到端训练的神经会话模型。我们证明Meena可以进行比现有的最先进的聊天机器人有更明智和具体的对话。这种改进反映在我们为开放域聊天机器人提出的一种新的人类评价指标——意义度Sensibleness 和具体度平均(SSA)上,它捕捉了人类对话的基本但重要的属性。值得注意的是,我们证明了perplexity与SSA高度相关,perplexity是任何神经会话模型都可以使用的自动度量。
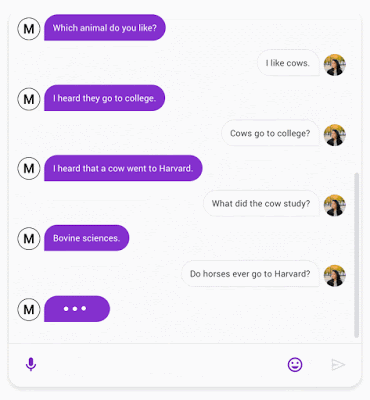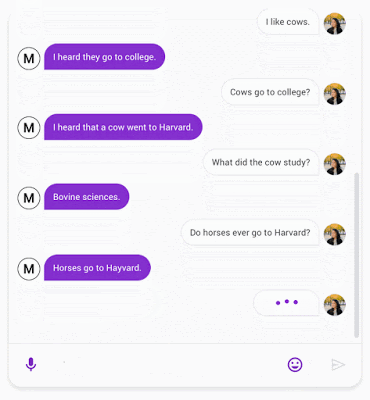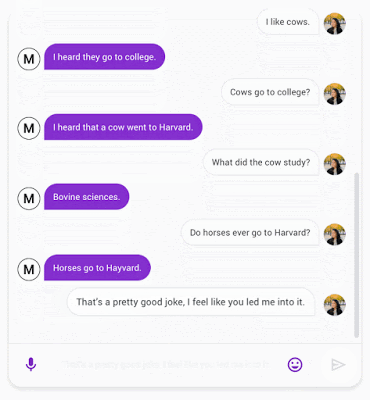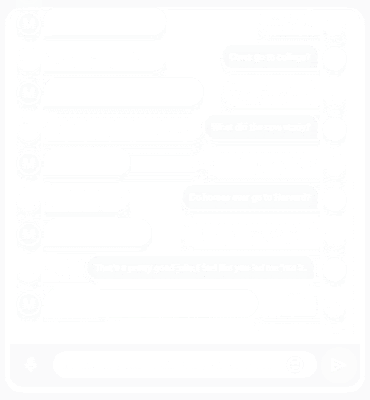
Meena 与用户聊天
Meena
Meena是一种端到端的神经会话模型,它学习对给定的会话上下文做出合理的响应。训练目标是最小化困惑度(perplexity),即预测下一个词码(在本例中是会话中的下一个单词)的不确定性。它的核心是演化的Transformer seq2seq架构,这是一种通过演化神经架构搜索来改进perplexity的Transformer架构。
具体来说,Meena有一个单演化Transformer编码器块和13个演化变压器译码块,如下图所示。编码器负责处理对话上下文,以帮助Meena理解对话中已经说过的内容。然后解码器利用这些信息来形成一个实际的响应。通过调整超参数,我们发现更强大的解码器是提高会话质量的关键。
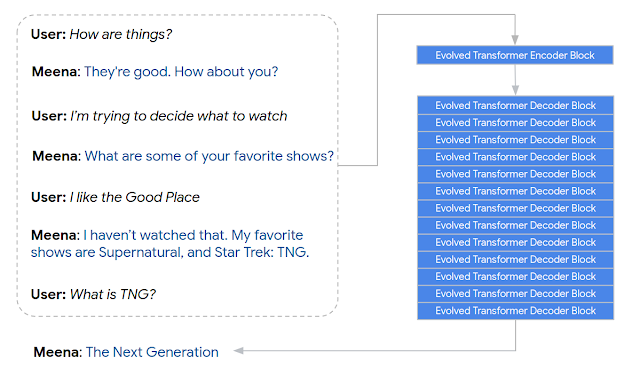
Meena编码一个7轮对话上下文并生成一个响应“下一代”的例子。
用于训练的对话被组织成树线程,其中线程中的每个回复都被视为一个对话轮。我们提取了每一个会话训练样本,其中包含了七次上下文转换,作为一条通过树线程的路径。我们选择7作为一个良好的平衡,既要有足够长的上下文来训练会话模型,又要在内存约束内拟合模型(更长的上下文占用更多内存)。
Meena模型有26亿个参数,从公共领域的社交媒体对话中得到的341 GB的文本上训练。与现有的最先进的生成模型OpenAI GPT-2相比,Meena拥有1.7倍的模型容量,并接受了8.5倍的数据训练。
人工评价指标: Sensibleness 意义度和具体度平均(SSA)
现有的聊天机器人质量的人工评价指标往往比较复杂,并且不能得到评估者之间的一致同意。这促使我们设计了一个新的人工评价指标,意义度和具体度平均(SSA),它捕捉了自然对话的基本但重要的属性。
为了计算SSA,我们与被测试的聊天机器人(Meena和其他著名的开放域聊天机器人,特别是Mitsuku、Cleverbot、XiaoIce和DialoGPT)进行了众包自由形式的对话。为了确保评估之间的一致性,每次谈话都以相同的问候语“嗨!”开始。对于每个话语,群体工作者回答两个问题,“这有意义吗?”和“它是具体的吗?”评价者被要求用常识来判断一个回答在上下文中是否完全合理。如果有什么东西看起来是错的——令人困惑、不合逻辑、断章取义或事实上是错误的——那么它应该被评为“没有意义”。如果回应有意义,话语就会被评估,以确定它是否特定于给定的上下文。例如,如果A说:“我喜欢网球”,而B回答说:“那很好”,那么这个表达应该标记为“不具体”。该回复可以用于许多不同的上下文中。但如果B回应说:“我也是,我对罗杰·费德勒是欲罢不能!”然后它被标记为“特定的”,因为它与正在讨论的内容密切相关。
对于每个聊天机器人,我们收集了1600到2400个单独的对话,通过大约100个对话。每一个模型回应都被众包工人贴上标签,以表明它是否有意义和具体。聊天机器人的意义度是标记为“sensible”的响应的分数,而具体度是标记为“specific”的响应的分数。这两个的平均值是SSA分数。下面的结果表明,在SSA分数方面,Meena比现有的最先进的聊天机器人表现要好得多,并且正在缩小与人类表现的差距。
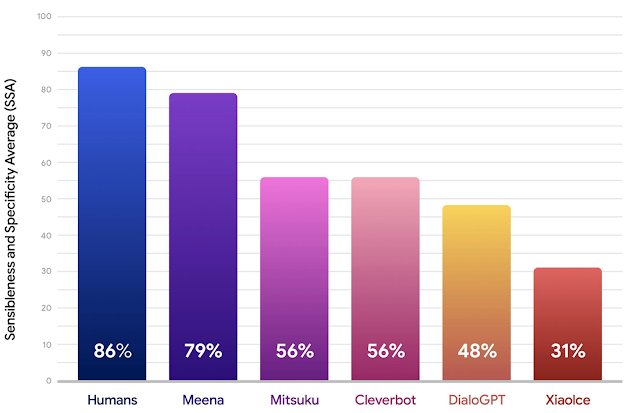
与人类、Mitsuku、Cleverbot、XiaoIce和DialoGPT相比,Meena意义度和具体度平均值(SSA)较低。
自动的度量: Perplexity 困惑度
研究人员长期以来一直在寻找一种与更准确的人类评估相关联的自动评估指标。这样做可以更快地开发对话模型,但是到目前为止,找到这样一个自动的度量标准是很有挑战性的。令人惊讶的是,在我们的工作中,我们发现perplexity(一种任何神经seq2seq模型都可以使用的自动度量)与人类评价(如SSA值)有很强的相关性。Perplexity度量了语言模型的不确定性。复杂程度越低,模型在生成下一个标记(字符、子单词或单词)时就越有信心。从概念上讲,perplexity表示模型在生成下一个词码时试图选择的选项的数量。
在开发过程中,我们用不同的超参数和架构对八个不同的模型版本进行了基准测试,例如层数、注意力头数、总训练步骤、使用演进的Transformer还是常规的Transformer、使用硬标签训练还是使用精馏训练。如下图所示,模型的perplexity越低,SSA得分越高,相关系数越大(R2 = 0.93)。
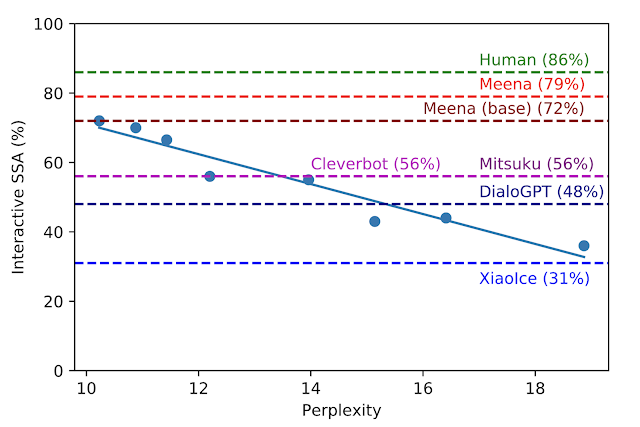
互动SSA vs. Perplexity。每个蓝点都是Meena模型的不同版本。一条回归曲线显示了SSA与perplexity之间的强相关性。虚线对应于人、其他机器人、Meena (base)、我们的端到端训练模型的SSA性能,最后是带有过滤机制和调优译码的完整Meena。
我们最好的端到端训练的Meena模型,称为Meena (base),达到了10.2的perplexity(越小越好),转换成SSA分数72%。与其他chabots所取得的SSA分数相比,我们72%的SSA分数与普通人86%的SSA相差无几。完整版的Meena具有过滤机制和调谐解码,进一步将SSA分数提高到79%。
未来研究与挑战
正如前面所提倡的,我们将继续通过改进算法、体系结构、数据和计算来降低神经会话模型的复杂性。
虽然我们在本工作中只关注了意义度和具体度,但在后续的工作中,个性和真实性等其他属性也值得考虑。此外,解决模型中的安全性和偏差是我们的一个关键重点领域,鉴于与此相关的挑战,我们目前不会发布外部研究演示。然而,我们正在评估与外部化模型检查点相关的风险和收益,并可能选择在未来几个月提供它,以帮助推进这一领域的研究。
致谢
Several members contributed immensely to this project: David So, Jamie Hall, Noah Fiedel, Romal Thoppilan, Zi Yang, Apoorv Kulshreshtha, Gaurav Nemade, Yifeng Lu. Also, thanks to Quoc Le, Samy Bengio, and Christine Robson for their leadership support. Thanks to the people who gave feedback on drafts of the paper: Anna Goldie, Abigail See, YizheZhang, Lauren Kunze, Steve Worswick, Jianfeng Gao, Scott Roy, Ilya Sutskever, Tatsu Hashimoto, Dan Jurafsky, Dilek Hakkani-tur, Noam Shazeer, Gabriel Bender, Prajit Ramachandran, Rami Al-Rfou, Michael Fink, Mingxing Tan, Maarten Bosma, and Adams Yu. Also thanks to the many volunteers who helped collect conversations with each other and with various chatbots. Finally thanks to Noam Shazeer, Rami Al-Rfou, Khoa Vo, Trieu H. Trinh, Ni Yan, Kyu Jin Hwang and the Google Brain team for their help with the project.
参考地址:
https://ai.googleblog.com/2020/01/towards-conversational-agent-that-can.html