观点 | 深度学习+符号表征=强大的多任务通用表征,DeepMind新论文可能开启AI新时代

融合两者优点
AI 科技评论按:在深度神经网络大行其道的现在,虽然大家总说要改善深度学习的可解释性、任务专一性等问题,但是大多数研究论文在这些方面的努力仍然只像是隔靴搔痒。而且,越是新的、具有良好表现的模型,我们在为模型表现感到开心的同时,对模型数学原理、对学习到的表征的理解也越来越进入到了放弃治疗的心态;毕竟,深度学习具有超出经典 AI 的学习能力,正是因为能够学习到新的、人类目前还无法理解的表征。
近期 DeepMind 的一篇论文《An Explicitly Relational Neural Network Architecture》(一种显式的关系性神经网络架构,arxiv.org/abs/1905.10307)似乎在这面高墙上打开了一个口子。他们想办法把深度学习和符号化的表征连接起来,而且着重在意表征的多任务通用和重复使用能力,而且取得了有趣的初步成果。AI 科技评论把这篇论文的内容简单介绍如下。
· 重新思考我们需要什么样的表征 ·
当人类遇到没有见过的新问题时,他们能回忆过往的经验,从那些乍一看没什么关系,但在更抽象、更结构化的层次上有不少相似度的事情中获得灵感。对于终生学习、持续学习来说,这种能力是非常重要的,而且也给人类带来了很高的数据效率、迁移学习的能力、泛化到不同数据分布的能力等等,这些也都是当前的机器学习无法比拟的。我们似乎可以认定,决定了所有这些能力的最根本因素都是同一个,那就是决策系统学习构建多种任务通用的、可重复使用的表征的能力。
一个多种任务通用、可重复使用的表征可以提高系统的数据效率,因为系统即便是遇到了新的任务也知道如何构建与它相关的表征,而不需要从零开始。理论上来说,一个能高效利用多种任务通用、可重复使用的表征的系统,实际上也就和能学习如何建立这样的表征的系统差不多。更进一步地,如果让系统学习解决需要使用到这样的表征的新任务,我们也可以期待这个系统能够学会更好地建立这样的表征。所以,假设一个系统从零开始学习不同的任务,那么除了它学习到的最初的表征之外,之后的所有的学习都像是迁移学习,学习的过程也将是一如既往地不断积累的、连续的、终生持续的。
在这篇论文中,DeepMind 提出的构建一个这样的系统的方法其实源于经典的符号化 AI 的启发。构建在一阶谓词计算的数学基础上的经典符号化 AI 系统,它们的典型工作方式是把类似逻辑的推理规则作用在类似语言的命题表征上,这样的表征自身由对象和关系组成。由于这样的表征有声明式的特性和复合式的结构,这样的表征天然地具有泛化性、可以重复使用。不过,与当代的深度学习系统不同,经典 AI 系统中的表征一般不是从数据学习的,而是由研究人员们手工构建的。目前这个方向研究的热点是想办法结合两种不同做法的优点,构建一个端到端学习的可微分神经网络,然后神经网络中也可以带有命题式的、关系性的先验,就像卷积网络带有空间和局部性先验一样。
这篇论文中介绍的网络架构基于非局部性网络架构的近期研究成果,这种网络架构可以学会发现并运用关系信息,典型的比如 relation nets 以及基于多头注意力的网络。不过,这些网络生成的表征都没有什么显式的结构,也就是说,找不到什么从表征中的一部分到符号化介质中的常用元素(命题、关系、对象)的映射。如果反过来探究这些元素在这样的表征中是如何分布的,可以说它们分散地遍布在整个嵌入向量中,从而难以解释,也难以利用它的命题性并在下游任务中运用。
· PrediNet 简介 ·
DeepMind 带来了新网络架构 PrediNet,它学习到的表征中的不同部分可以直接对应命题、关系和对象。
把命题作为知识的基础部件的想法由来已久。一则元素声明可以用来指出一组对象之间存在某种关系;声明之间可以用逻辑操作连接(和、或、否等等),也可以参与到推理过程中。PrediNet 的任务就是学习把图像之类的高维数据转换为命题形式的表征,而且这个表征可以用于下游任务。
PrediNet 模块可以看做是由三个阶段组成的流水线:注意力 attention,约束 binding 和评价 evaluation。注意力阶段会选择出成对的感兴趣的对象,约束阶段会借助选出的成对对象把一组三元谓词中的前两个实例化,最后评价阶段会计算三元谓词中的最后一个的(标量)值,判定得到的声明是否为真。(更具体的介绍见论文原文)
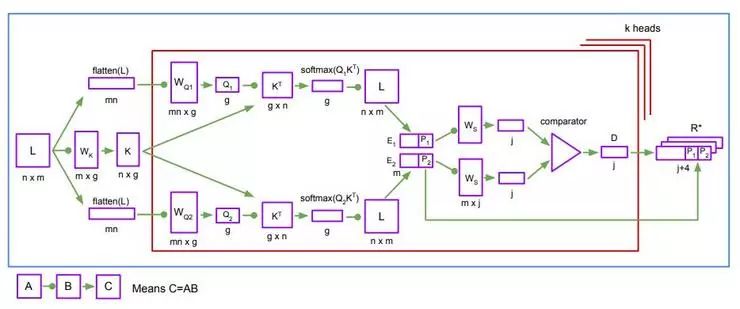
PrediNet 网络架构
· 实验测试 ·
目前还没法直接把 PrediNet 用于大规模复杂数据;而且为了对提出的架构有足够扎实的科学理解,以及便于和其它方法进行细致的比较,用小数据、小计算量做实验也是比较合适的。实验测试的目标有两个,1,验证 PrediNet 是否能学习到希望的多任务通用、可重复使用的表征;2,如果前一个目标为真,研究它成立的原因。
作者们设计了一组“猜测关系”游戏,是相对简单的分类任务。它的玩法是,首先要学习表征一组绘制在 3x3 网格中的图形,然后对于一张含有多个图形的大图,判断给出的一条关于大图中的图形间的关系的声明是否为真。虽然 PrediNet 本身学习到的命题都只是很对两两成对的对象的,这个猜测关系游戏需要的是学习可能会牵扯到多个对象的复合关系。
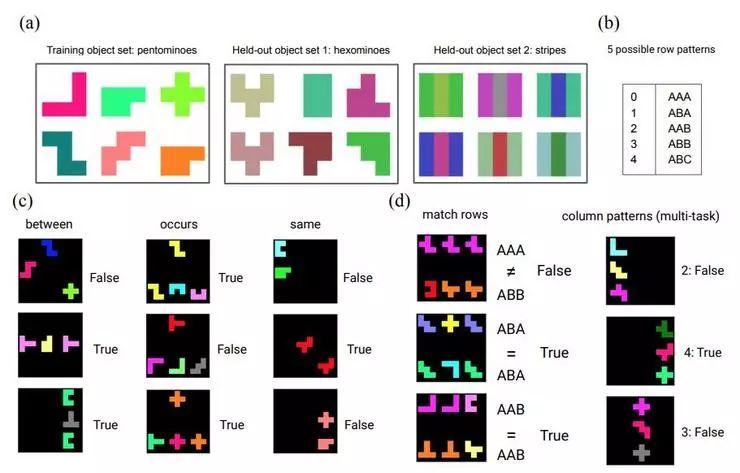
游戏介绍:(a)训练集中包含的样本对象 (b)五种不同的可能行/列排列模式 (c)单个任务预测的示例 (d)多任务预测示例
多种形状和关系的排列组合使得这个任务的变化有相当多种,是比较理想的测试表征及逻辑能力的设定。
作者们对比的几种模型都带有一个卷积输入层、中央模块、以及一个用于输出的多层感知机;中央模块是区别所在,PrediNet 或者其他的基准模型。
数据效率
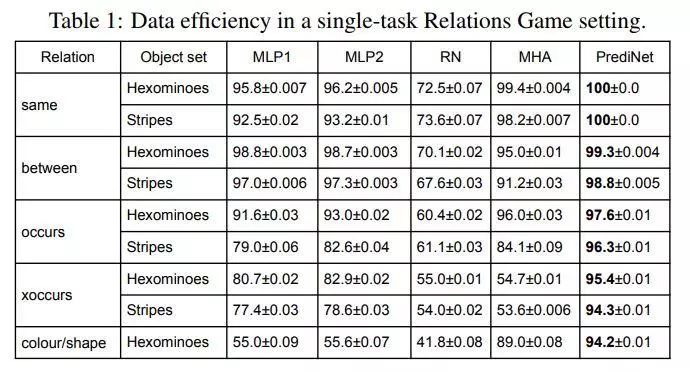
用十万组样本训练以后,5 种模型的对比如下。PrediNet 是唯一一个在所有任务上都取得超过 90% 准确率的模型;在某些任务中相比基准模型甚至有 20% 的提升。
表征学习能力
作者们设计了四个阶段的模型学习,通过在不同阶段测试模型,可以探究模型的表征学习能力。从空白模型开始,首先学习一个任务(即无预训练的单任务学习);其次学习多种不同任务(在第一个任务的基础上,即有预训练的多任务学习);接着冻结 CNN 层和中央模块,仅更新多层感知机;最后冻结 CNN 层,更新中央模型和多层感知机。这四个阶段中不同模型的表现如下图。
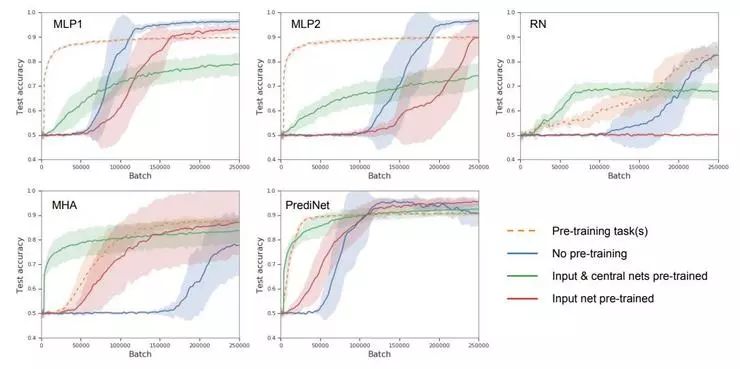
首先,横坐标是训练样本数量,纵坐标是准确率,即模型表现随训练样本增加的变化,那么所有曲线都是越贴近左上角越好,这里已经能看出 PrediNet 的优势。其次,作者们认为尤其值得注意的是第三个阶段的表现,冻结 CNN 层和中央模块,仅更新多层感知机,图中绿线。冻结现有的表征不变,向新的任务适应(迁移),PrediNet 的学习速度是最快的,也是唯一一个在训练结束后得到了 90% 准确率的模型。这就说明了 PrediNet 学习到的表征确实更加多任务通用。
模型可视化
为了更好地理解 PrediNet 的计算行为,作者们制作了一些可视化,如图。
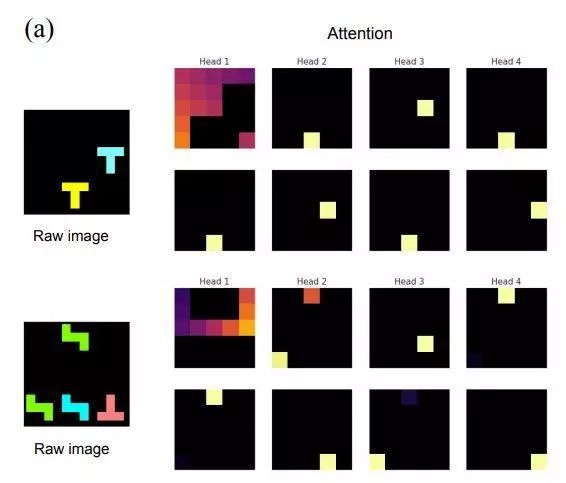
训练后的 PrediNet 的注意力头的热力图。上方:在判断是否形同的任务中训练;下方:在判断是否出现的任务中训练
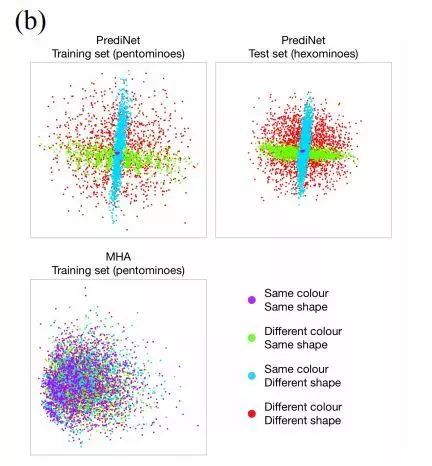
主成份分析(PCA)
结合多种实验和分析,作者们认为 PrediNet 确实有一定的关系解耦能力,这也正是研究开始时希望得到的能学习到良好的表征的模型所需的。
· 结论 ·
作者们展示了一个理论上可以学习到抽象逻辑的模型,而且它还和端到端学习兼容;网络可以自行从原始数据中学习到对象和它们的关系,从而绕过了传统 AI 中手工特征带来的种种问题。作者们的实验表明网络可以学习到显式命题的、关系性的表征,从而在数据效率、泛化性、可迁移性方面都有大幅改进。不过这仅仅是非常初步的研究,完全开发这个思路的潜力,并把它应用在更复杂的数据、更复杂的实际任务中还需要很多后续研究。
另一方面,这篇论文的重点在于获得这样的表征而非应用它。不过由于这种模型架构带有的良好先验,PrediNet 模块生成的表征和谓词计算是自然地相容的,这就为后续的各种符号逻辑运算做了良好的铺垫。这个基础上的改进可以考虑增加循环连接,这可能会让模型具有迭代和序列计算能力;也可以考虑把它用于强化学习,可以对目前的深度强化学习的各方面问题都带来改进。
论文原文:https://arxiv.org/abs/1905.10307
AI 科技评论报道
由中国计算机学会主办、雷锋网和香港中文大学(深圳)联合承办的 2019 全球人工智能与机器人峰会( CCF-GAIR 2019),将于 2019 年 7 月 12 日至 14 日在深圳举行。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。

另外,AI研习社为大家争取了5个国内机酒赞助参加CCF-GAIR 2019的名额,点击链接即可查看。