盘点深度学习一年来在文本、语音和视觉等方向的进展,看强化学习如何无往而不利

【AI科技大本营导读】AlphaZero自学成才,机器人Atlas苦练后空翻……2017年,人工智能所取得的新进展真是让人应接不暇。而所有的这些进展,都离不开深度学习一年来在底层研究和技术开发上的新突破。圣诞节前后,Statsbot的数据科学家Ed Tyantov专门评估了深度学习这一年在文本、语音和视觉等方向的各项研究成果,并进一步试图总结出一些可能影响未来的全新趋势。
具体都是些什么呢?我们来看文章。
作者 | Eduard Tyantov
翻译 | 林椿眄
文本
Google神经网络翻译机器
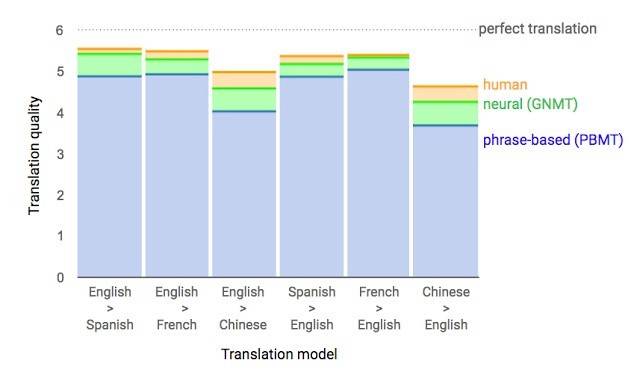
这项技术最大的突破是,使机器翻译与人类的差距缩小了55-85%。必须指出,如果没有Google的庞大数据库作为支撑,这个递归神经网络的翻译模型很难使机器达到如此好的翻译效果。
谈判,会成功交易吗?
你可能听说过一则愚蠢的新闻,Facebook公司关闭了聊天机器人,然后这个机器人失去控制,自己编写语言。
这个聊天机器人是Facebook公司创造的并用于谈判交易工作的。它的目的是与另一个代理进行谈判并达成交易:如何将物品(如书,帽子等)一分为二。每个代理在谈判中都有自己的目标,而互相之间事先并不知晓对方的想法。
为了训练机器人的需要,他们收集了一个有关人类谈判的数据库并且采用有监督的方式来训练递归神经网络模型。随后,这些聊天机器人用一种强化学习的方式进行自我训练,并在保证语言与人类尽可能相似的前提下,学着与自己进行对话。
慢慢地,这些机器人已经学会了一个真正的谈判策略,那就是通过在谈判过程中表现出对目标虚假的兴趣来误导对方,并在实际目标的选择中受益。
创造这样一个互动机器人是一种全新的且非常成功的尝试。未来关于它的更多细节以及代码都将开源。
当然,新闻中称该机器人发明了一种新语言的消息是有点故弄玄虚。训练时(与同一代理商进行谈判时),放弃与人类保持相似性的限制,并通过算法来修改交互时所使用的语言,这并不是什么特别的事情。
在过去的一年里,循环神经网络模型已经得到非常广泛的运用,同时,循环神经网络的架构也变得更加复杂。但是在一些领域,简单的前馈网络DSSM就可以得到类似的结果。例如,Google邮件的“智能回复”功能较之前应用LSTM架构,有着相同的性能表现。此外,Yandex还基于这样的网络推出了一个新的搜索引擎。
语音
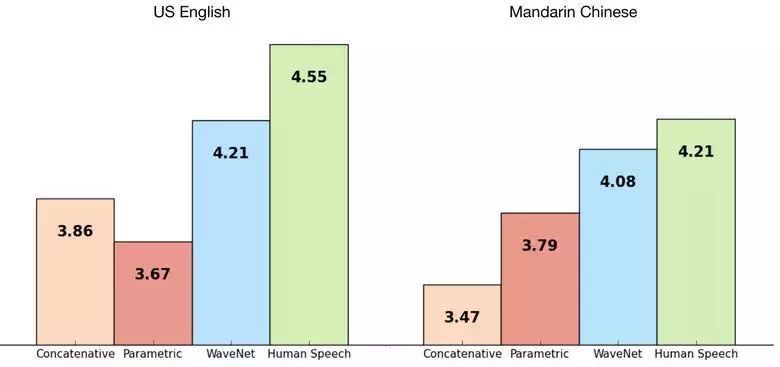
WaveNet:原始音频的生成模型
DeepMind的员工最近在文章中报道了生成音频的研究成果。简而言之,研究人员基于先前的图像生成方法(像素级RNN模型和像素级CNN模型),提出了自回归的全卷积WaveNet模型。

该网络实现了端到端的训练:从输入文本到输出音频。相比于人类水平,该研究降低了50%的差异性,取得了很好的结果。但是,该网络的主要缺点就是生产效率低。由于自回归过程的原因,声音是按照顺序生成的,大约需要1-2分钟来创建1秒的音频。
听到这个结果让人感觉有点失望。如果能够消除网络结构对输入文本的依赖性而仅仅留下对先前生成的音符的依赖性,那么网络将产生类似于人类语言的音符,但是这样做并没有意义。
这是一个应用该模型生成声音的例子。这种相同的模式不仅适用于演讲,也适用于音乐创作。
想象一下由生成模型生成的音频,使用关于同样不依赖于输入数据的钢琴数据库进行音乐教学工作。
如果你对这方面感兴趣的话,请阅读DeepMind关于此研究的完整介绍。
唇语解读
唇语解读是深度学习超越人类的另一大表现。Google DeepMind与牛津大学合作,他们发表论文讲述如何用电视数据集训练的模型的性能表现是如何超过BBC频道里的专业唇语读者。

该数据集中有10万个带有音频和视频的句子。采用音频数据训练LSTM模型,视频数据训练CNN+LSTM模型。这两种状态下训练得到的模型向量都被馈送到最终的LSTM模型中去,从而产生最终的结果。
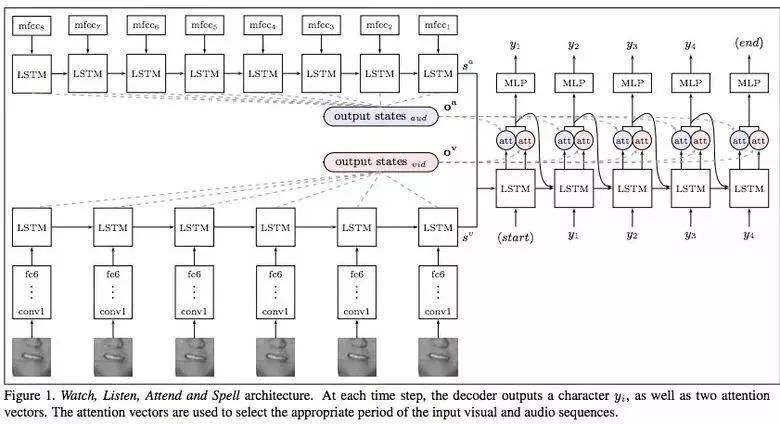
在训练期间使用不同类型的输入数据:包括音频、视频和音频+视频组合数据等。换句话说,这是一种“全渠道全方位”的训练模型。

合成奥巴马:在音频中同步他的嘴唇运动
华盛顿大学做了一项严谨的研究,来生成前美国总统奥巴马的唇语动作。之所以会选择他作为研究对象,是因为这段在线录音的持续时间很长,数据数量巨大(17个小时的高清视频)。
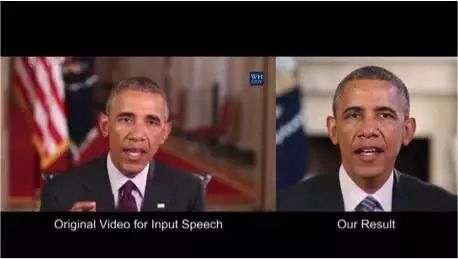
由于他们没办法得到更多的数据资料,因此研究者进一步提出了几个技巧性的东西来改善最后的结果。如果你感兴趣的话,可以来试试看。
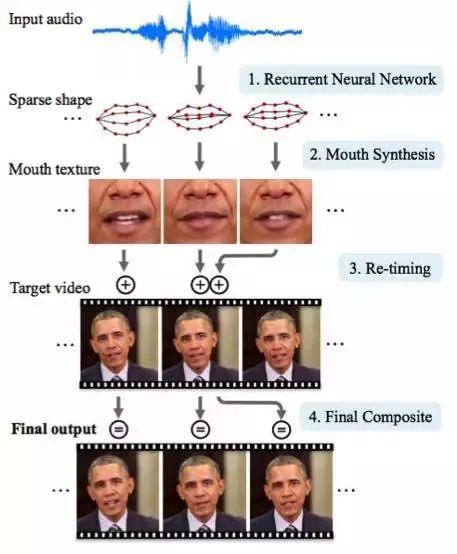
你可以看到研究的结果是很惊人的。在不久的将来,你甚至将不能相信那些总统的演讲录像了。
计算机视觉
OCR: Google街景地图
Google Brain Team在他们的博客和文章中报道了他们是如何在地图中引入新的OCR(光学字符识别)引擎,通过它来识别路牌和商店标志。


在这项技术的开发过程中,他们编制了一个新的FSNS(法国街道名称标志),其中包含许多复杂的样例。为了识别每一个标志,网络最多使用四张图片,用CNN来提取图片特征,再辅以空间注意力机制,最终将结果馈送到LSTM模型中。
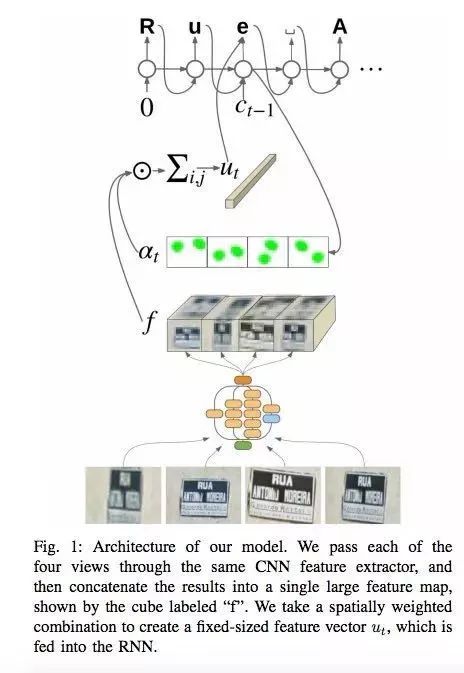
相同的方法适用于在标志牌上识别商店名称的任务(这可能会受到很多“噪声”数据的干扰,而模型本身需要聚焦到正确的位置上)。这种算法已适用于800亿张照片的识别。
视觉推理
视觉推理任务,要求神经网络使用照片来回答其中的问题。例如,“在图片中是否有与黄色金属圆柱体相同尺寸的橡胶材质?”这确实是个非常重要的问题,而直到最近这个问题才得以解决,其准确率只有68.5%。

Deepmind团队在这个领域再次取得了突破:在CLEVR视觉推理数据集上,他们的模型实现了95.5%的超人类精确度。模型的网络架构十分有趣:
在文本问题上使用预先训练好的LSTM模型,我们将问题嵌入到模型中。
使用CNN模型(只有四层结构)对图片提取特征,我们得到图片的特征映射用来表征图片的特征。
接下来,我们在特征映射图上(如下所示图片的黄、蓝、红色区域)形成坐标切片的成对坐标组合,并将坐标值和文本信息嵌入到每个区域中。
通过另一个网络,我们将上述整个过程驱动三次,并将得到的最后结果汇总。
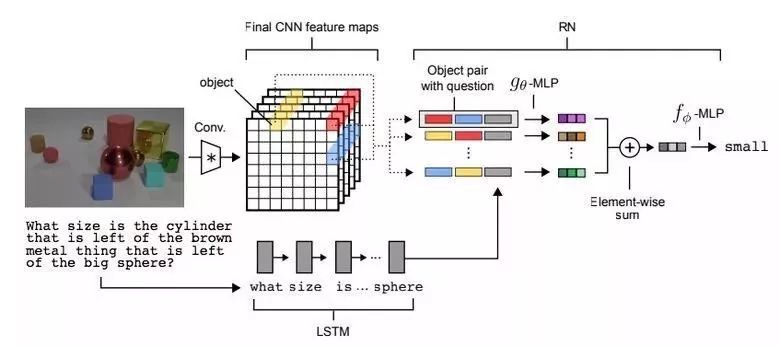
最终呈现的是通过另一个前馈网络运行的结果,并给出了Softmax的结果。
Pix2Code
Uizard公司创建了一个神经网络的有趣应用:即根据界面设计者的屏幕截图来生成一个界面布局。

这是一个非常有用的神经网络应用程序,他可以使开发者在开发软件时更加轻松。该项应用的研究者声称他们已经能够达到77%的应用准确率。
SketchRNN:教一台机器学会画画
也许你看过Quick, Draw!这是出自Google公司之手,其目标是在20秒内绘制出各种对象的草图。该公司设计这个数据集的目的是,教会神经网络如何画画。

最终公布的数据集包含7万张草图。草图并不是图片,而是一张张绘图的详细向量表示(在这一点上用户按下“铅笔”,在线段绘制的地方再释放,等等)。研究人员已经使用RNN模型作为一个编码/解码机制来训练序列到序列的变分自编码器。
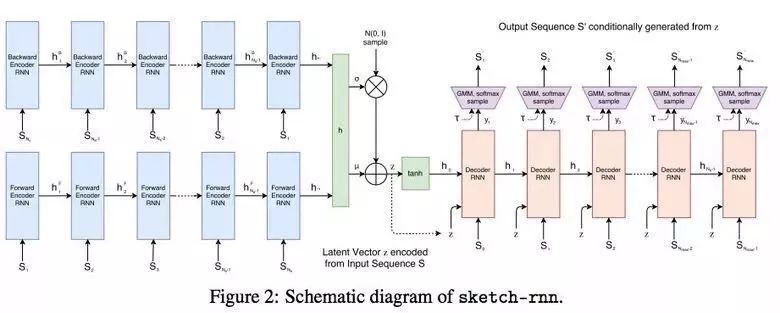
最终,为了适应自编码器的需要,该模型接收到表征原始图像的潜在向量。
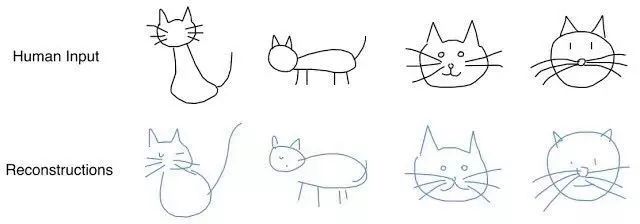
由于解码器能够从这个潜在向量提取一副草图,你可以通过改变它来得到一副新的草图。

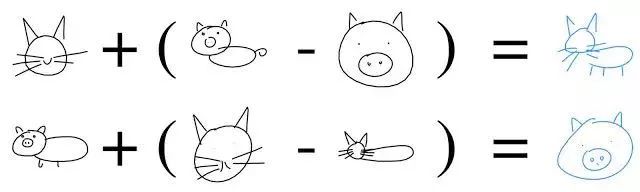
甚至可以执行一个矢量算法来创建一个catpig,如下图所示:
生成对抗网络
生成对抗网络是当下深度学习中最热门的话题之一。大多数情况下,这个模型是用来处理图像数据,因此我们会用图像来解释这个模型。
提出这个模型的思想是在两个竞争的网络中,一个生成网络和一个判别网络。生成网络是用于创建一张新的图像,而判别网络试图去判定图像是真实的还是生成的。模型原理示意图如下所示:
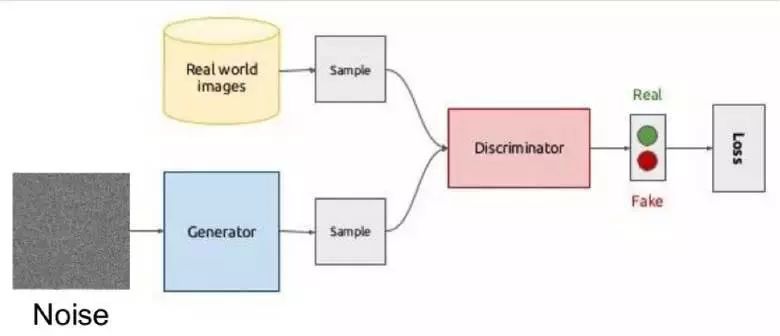
在训练期间,生成网络接收随机向量(噪声)作为输入并生成图像,接着将其馈送到判别网络中作为其输入,由判别网络判定输入的真假性。判别网络也可以从数据集中给出真实的图像。由于很难找到两个网络的平衡点,因此训练生成对抗网络一大难点。大多数情况下,判别网络获胜时训练过程也就停止了。但是,这种模型的好处就在于我们可以解决一些难以设定损失函数的问题。例如,要提高图片的质量,我们可以将其提供给判别网络。
生成对抗网络训练的典型例子就是带卧室或人的图片,如下所示:


之前,我们考虑过自编码器(Sketch-RNN模型),它能够将原始的数据编码变成潜在的向量表示。而生成网络能够做同样的事情。在这个项目中,如果是人脸的例子,那么通过使用该向量,生成网络能够生成清晰的人脸图像。你也可以通过改变向量,来观察脸部的变化情况。

同样的算法也可以在潜在的空间起作用:例如,“一个戴眼镜的男人”减去“男人”再加上“女人”等于“戴眼镜的女人”。

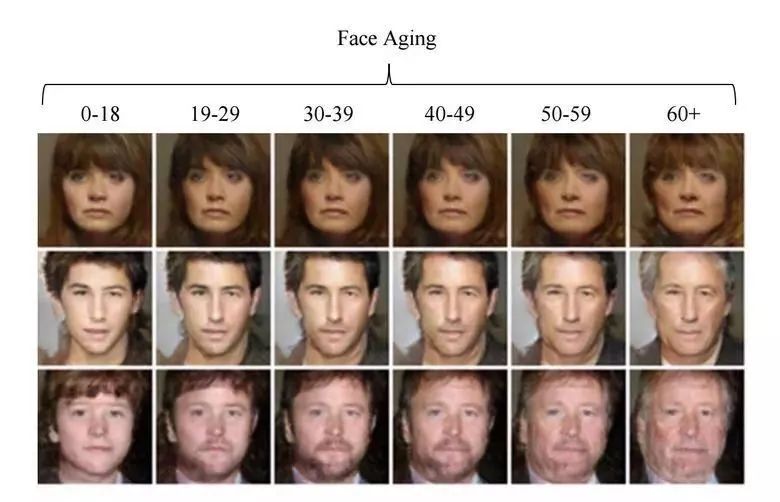
用生成对抗网络改变人脸的年龄
如果在训练过程控制潜在向量的传入参数,那么在生成潜在向量时,就可以更改这些参数值,以便管理图片中这些必要的图像信息,这种方式称为条件生成对抗网络模型。正如文章的作者提到的:“面对有条件的生成对抗网络模型,人脸的年龄是可以被改变的。”在已知人脸年龄的情况下,在IMDB数据集上训练我们的模型,我们可以用这种方式改变人脸的年龄。
专业照片
Google为生成对抗网络创建了一个有趣的应用程序,就是照片的选择和美化。生成对抗网络模型在一个专业的照片数据集上训练:生成网络试图改善质量较差的照片(包括专业镜头和特殊滤镜的功能退化等),而判别网络用于区分“改善后”的照片和真正的专业照片。

一个训练有数的算法,能够通过Google街景的全景搜索功能来搜索得到一些专业和半专业质量的照片(根据摄影师的评级标准而定)。

从文本描述中合成图像
生成对抗网络最令人印象深刻的一个例子是使用文本的描述信息来生成图像。

这项研究的作者说到,不仅将文本信息嵌入到生成网络(条件生成对抗网络)的输入中去,而且还要将其嵌入到判别网络中去,以便验证文本信息与图像的对应性。为了确保判别网络自身功能的发挥,除了训练过程,研究者还为实际图片添加了一些不正确的文本信息。
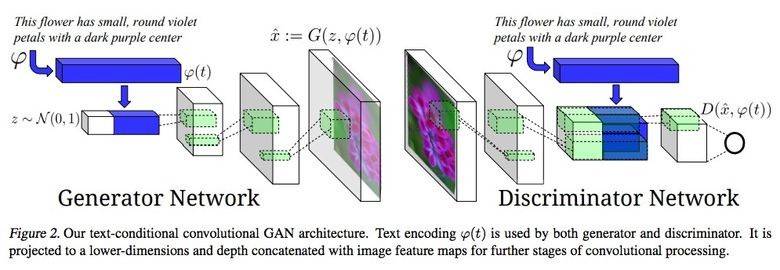
Pix2Pix
在2016年最受人瞩目的文章当属Berkeley AI Research(BAIR)提出的“用带有条件的生成对抗网络来实现图像到图像的转换”。研究人员解决了从图像到图像生成的问题,例如,需要使用卫星图像来创建地图,或使用草图来创建逼真的对象纹理,都可以使用该研究的成果。

条件生成对抗网络的另一个成功应用例子,是根据情景生成整个画面。这在图像分割领域得到广泛的应用,Unet被用作生成网络的体系结构,并且使用一个新的PatchGAN分类器作为判别网络,用以对抗模糊图像的干扰(图像被分割成N个补丁,并且伪造/真实的预测将分别适用于他们当中的每一个部分)。
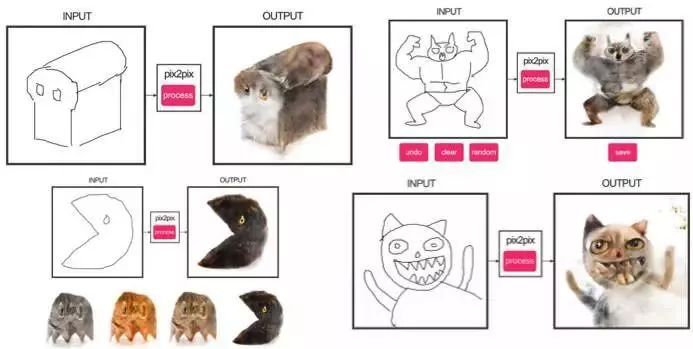
作者发布了他们模型的在线演示,你也可以在这里找到模型的源代码。https://github.com/phillipi/pix2pix
CycleGAN
为了应用Pix2Pix技术,你需要一个包含了不同领域目标对象的数据集。例如,用卡片来组成这样的数据集不成问题,但是如果你想做一些更复杂的事情,如“变形”对象或重塑对象的话,原则上是找不到这样的目标对象的。因此,Pix2Pix的作者决定进一步研究他们的想法,并提出CycleGAN,在图像的不同区域之间进行不成对目标的转换,而不再需要依赖于特定的目标对。

这个想法是教会两对生成网络和判别网络,从图像的一个域转移到另一个域。而我们需要的是一个循环一致性,即依次应用生成网络后,我们应该得到一个类似原始L1损失的图像。而一个循环损失函数所需要的并不仅仅是确保生成网络在开始时将一个域的图像传送到与另一个域完全无关的图像。
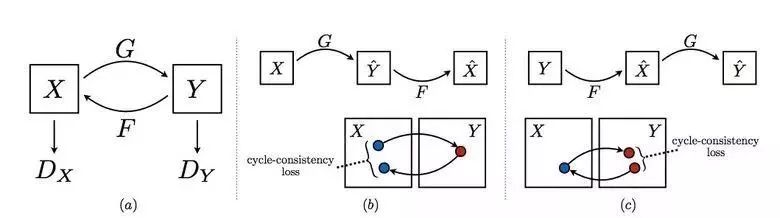
这种方式能让你学习到马—斑马之间的映射。

但是这转变是不稳定的,这通常也是产生失败的原因。

你可以在这里获得它的源代码。https://github.com/junyanz/CycleGAN
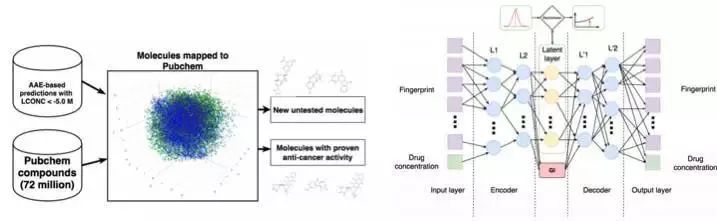
肿瘤学中分子的发展
机器学习正在进入医学领域。除了识别超声波,MRI和诊断,还可以用于寻找新的药物来对抗癌症。简单地说,在对抗自编码器的帮助下,我们可以学习分子的潜在形式,然后以此来搜索新的分子形式。结果发现了69个分子,其中一半是被用来对抗癌症,而剩下的都具有很大的潜在性。
对抗性攻击
关于对抗性攻击的话题,正在被积极地探索研究。那么什么是对抗性攻击呢?例如,在ImageNet数据库上训练标准网络,当为分类图片添加一些特定的噪声时,标准网络将变得不稳定。在下面的例子我们将看到,对于一张人眼看过去几乎没有变化的图片,而模型却还产生异常的结果,预测出一个完全不同的类别。

例如,使用快速梯度符号法(FGSM),可以得到稳定的模型:可以访问模型的参数,可以对所需的类进行一个或多个渐变的步骤并以此更改原始的图片。
Kaggle中有一个与此有关的任务:就是鼓励参与者创造普遍的攻击/防御,这些攻击/防御最终都是相互对立的,以此来确定最好的模型。
我们为什么要研究这些攻击呢?首先,如果我们想要保护我们的产品,我们可以向验证码添加噪声,以防止垃圾邮件的自动识别。其次,算法越来越多地涉及到我们的生活中,如人脸识别系统和自动驾驶系统,在这种情况下,攻击者就可以利用算法的缺点展开攻击,威胁到我们的生活。

例如,特殊的眼镜可以让你欺骗人脸识别系统,系统将把自己当成另一个人。
所以,在训练模型的时候我们要考虑到可能的攻击情况。类似以下的这种的操作符也不能被它们正确的识别:

这是比赛组织者写的一篇文章。https://www.kaggle.com/c/nips-2017-non-targeted-adversarial-attack/discussion/35840
编写好了的用于攻击的代码库:cleverhanshttps://github.com/tensorflow/cleverhans和foolboxhttps://github.com/bethgelab/foolbox。
强化学习
强化学习是机器学习中最有趣也是最值得发展的方法之一。这种方法的本质是通过给定的经验,在特定的环境中,学习训练代理并给予奖励的一种学习方式,就像人类的终生学习一样。
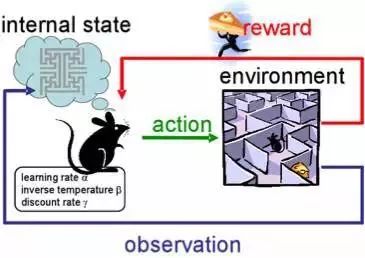
强化学习在游戏,机器人和系统管理等领域已被广泛地使用。当然,大家都听说过AlphaGo在围棋比赛中完胜围棋专业选手。目前,研究人员正使用强化学习方式来训练机器人,因为机器人本身的设计就是为了改进策略而不断发挥自身作用的。
以强化学习方式训练不受控制的辅助任务
在过去的几年中,DeepMind的研究者使用深度强化网络(DQN)来学习街机游戏,并已达到超人类的游戏表现。目前,他们正在训练算法去学习玩一些更复杂的游戏,如毁灭战士(Doom)。
强化学习的研究,大部分的注意力都集中在加速学习方面,因为代理与环境之间的交互经验需要在目前的GPU上进行很长时间的训练。
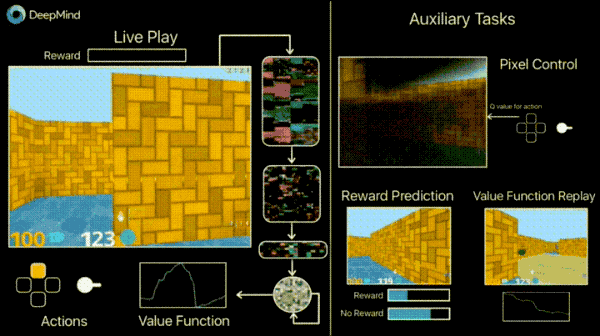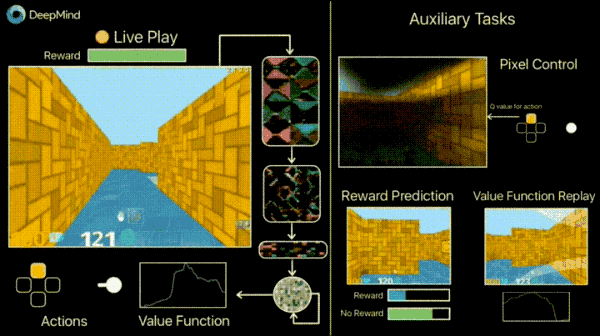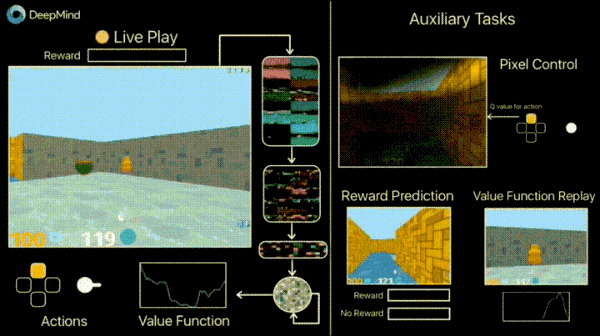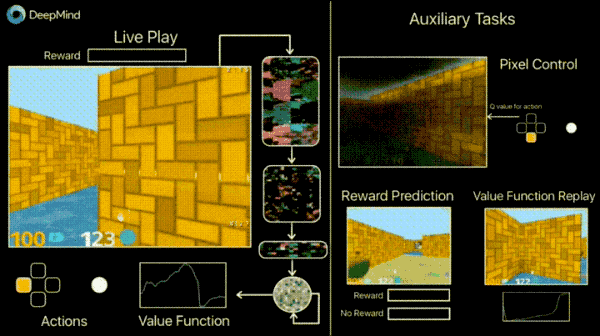
在DeepMind的官方博客中,介绍了一种引入额外损失(辅助任务)的方式来加速训练过程,如预测帧变化(像素控制),以便代理能够更好地理解行为的后果,这将大大加快学习的速度。
https://youtu.be/Uz-zGYrYEjA
学习机器人
OpenAI的研究人员一直致力于研究代理在虚拟环境中的训练过程,相比于现实生活,这样的实验显得更加安全。其中一项研究表明,一次学习是可能是实现的。一个人在虚拟现实中能够展示如何执行某项任务的能力,而一个演示就足以让算法进行学习,并在真实条件下实现。如果可以的话,这对于人类来说简直是太容易了。

学习人的喜好
这是OpenAI和DeepMind共同的一个工作主题。底线是一个代理和一个任务,算法提供两种可能的解决方案,并指出哪一种更好。通过迭代地训练该过程,得到来自代理的反馈信息,并以此来学习如何解决该问题。
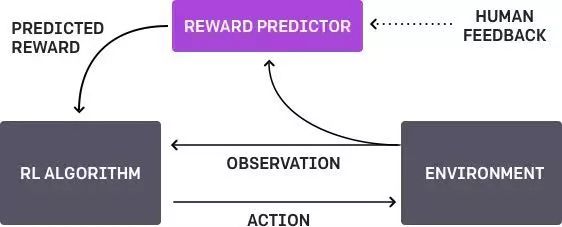

即使这样,人类必须要认真思考要让机器去学习的东西。例如,评估者确定要让算法去接受某个对象,但是实际上他只是模拟了这个动作而已。

在复杂环境中运动
这是DeepMind的另一项研究。为了教会机器人一些复杂的行为(走路,跳跃等),甚至做一些类似人类做的事情,你必须要大量地考虑损失函数的选择,这将是鼓励所期望行为发生的关键所在。然而,这个算法最好靠简单的奖励来学习复杂的行为。研究人员已经成功实现了这一目标:他们通过构建一个复杂的带障碍的环境,在移动的过程给予简单的奖励回报,教会一个代理(身体模拟器)去执行一些复杂的行为。

你可以看看这些令人印象深刻的视频,不过,用超声道观看它将更加有趣。https://youtu.be/itACOKJHYmw
最后,我将给出OpenAI最近发布的学习强化学习算法的链接,相比于标准的深度强化网络,现在你可以使用一些更先进的方法来解决问题。https://github.com/openai/baselines
其他
冷却数据中心
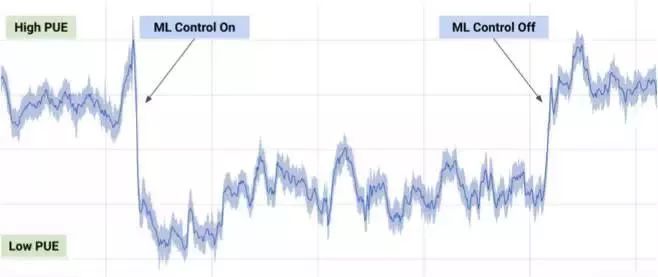
2017年7月,Google公司报告中提到,利用DeepMind在机器学习领域的研究成果来降低数据中心的能源成本。根据数据中心上千个传感器的数据信息,Google开发人员训练了一个集成的神经网络来预测PUE(电源使用效率)和更高效的数据中心管理。这是机器学习实际应用中一项令人深刻的成果。
一个模型完成所有任务
正如你所知道的那样,训练好的模型很难从一个任务转移到另一个任务,因为每个任务都必须经过特定的模型训练过程。Google Brain提出的“用一个模型来学习所有的东西”,向模型的普遍适用性研究迈出了一小步。
研究人员已经训练了一个模型,来执行不同领域(包括文本,语音和图像等)的八个任务。例如,来自不同语言的翻译,文本的解析以及图像和声音的识别等任务。
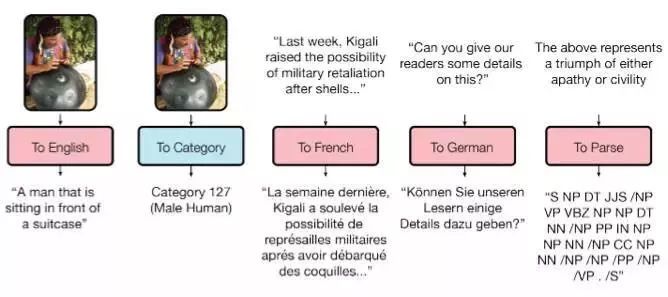
为了实现这个目标,他们构建了一个复杂的网络结构,用不同的模块来处理不同的输入数据并输出结果。编码器/解码器的模型分为三种类型:卷积、注意力和门控混合专家模块。
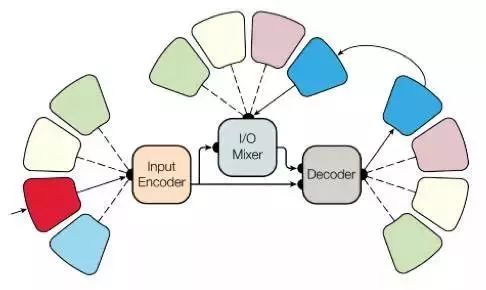
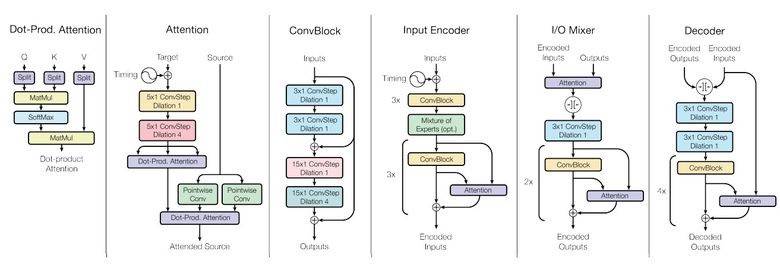
主要的研究成果如下:
得到几乎完美的模型 (作者没有微调超参数设置)。
不同领域间的知识迁移,即在数据量大的任务上,性能几乎相同,对于小问题的性能表现更好 (如解析任务)。
不同人物所需的模块间不会产生相互的干扰,有时甚至可以互相帮助,如门控混合专家的模块在ImageNet上,对任务的模型性能有改善作用。
另外,这个强大的模型已经呈现在tensor2tensor中。
一小时内学习ImageNet数据库
在他们的帖子中,Facebook的工作人员告诉我们,他们的工程师只需要一个小时就能够在ImageNet数据库上训练完ResNet-50模型,这需要使用256个GPU集群(Tesla P100)。他们使用Gloo和Caffe2深度学习框架进行分布式训练。为了是整个过程更有效率,对于学习策略的调整是很有必要的(8192个元素):采用梯度平均,模型预训练以及特殊学习率等策略。
结果表明,从8个GPU扩展到256个GPU训练时,可以达到90%的效率。也就是说,现在Facebook的研究人员可以比没有这个集群的研究者更快地进行实验。
新闻
自动驾驶汽车
自动驾驶汽车领域的研究正在深入发展,而自驾车也正在测试中。从最近的事件中,我们可以看到来自英特尔的MobiEye被收购,Uber和Google的技术被前员工偷窃的丑闻以及使用自动驾驶仪所导致的第一起交通死亡事件等。
我注意到:Google Waymo正推出一个测试版的自驾程序。Google是自动驾驶领域的先驱,并且他们的技术已经非常成熟,因为Google的无人驾驶车已经行驶了300多万英里。
最近发生的大事是自动驾驶汽车已经被允许在美国各州上路。
卫生保健
现代机器学习技术已经开始引入医学领域。例如,Google与医疗中心合作并帮助医生进行诊断。
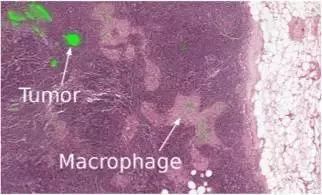
为此,DeepMind还成立了一个独立的单元,用于从事医学领域的深度学习技术研究。

今年,DeepMind在数据科学碗项目的基础上举办了一场竞赛,根据详细的图像数据来预测肺癌,该赛事的奖金高达一百万美元。
投资
目前,与之前BigData一样,机器学习领域也得到了大量的投资。中国在人工智能领域的投资已有1500亿美元,处于全球领先水平。百度研究公司雇佣了1300人从事人工智能的研究工作,而Facebook的FAIR研究院才有80位研究人员。此外,在KDD会议结束的尾端,阿里巴巴的员工谈论到他们的参数服务器KungPeng,运行了1000亿个样本,具有万亿级的参数量,这已经成为日常工作里的一个基本运作。

你可以得到自己的结论,学习机器学习永远都不会太晚。无论如何,随着时间的推移,所有的开发人员都将使用机器学习技术和数据库。不久的将来,这会成为一项常备技能。
https://blog.statsbot.co/deep-learning-achievements-4c563e034257
热文精选
干货 | AI 工程师必读,从实践的角度解析一名合格的AI工程师是怎样炼成的
AI校招程序员最高薪酬曝光!腾讯80万年薪领跑,还送北京户口
谷歌AI正式来中国了,机器学习三大职位正在招聘...如果你想跟李飞飞一起工作的话
算法还是算力?周志华微博引爆深度学习的“鸡生蛋,蛋生鸡”问题




