AlphaZero 实战:从零学下五子棋(附代码)

本文作者一缕阳光,本文首发于知乎专栏强化学习知识大讲堂,AI 研习社获其授权转载。
2 个多月前,AlphaGo Zero 横空出世,完全从零开始,仅通过自我对弈就能天下无敌,瞬间刷爆朋友圈,各路大神分分出来解读,惊叹于其思想的简单、效果的神奇。很快就有大神放出了开源版的 AlphaGo Zero,但是只有代码,没有训练出来的模型,因为据大神推算,在普通消费级的电脑上想训练出 AlphaGo Zero 的模型需要 1700 年!然而 DeepMind 在 AlphaGo Zero 的论文里只强调运行的时候需要 4 个 TPU,而完全没有提及训练过程的最大计算需求在于生成 self-play 数据,还引起了一点小争议。
还好,过了不到两个月,在 12 月初,DeepMind 就在 Arxiv 上低调放出了更加通用的 AlphaZero 的论文。AlphaZero 几个小时就征服围棋、国际象棋和日本将棋的壮举再次惊叹世人,但同时 DeepMind 大方公开的 self-play 阶段使用的 5000 个 TPU 也让大家纷纷感叹,原来是 “贫穷限制了我们的想象力”!
扯得有点远了,让我们回到这篇文章的正题:AlphaZero 实战,通过自己动手从零训练一个 AI,去体会 AlphaZero 自我对弈学习成功背后的关键思想和一些重要技术细节。这边选择了五子棋作为实践对象,因为五子棋相对比较简单,大家也都比较熟悉,这样我们能更专注于 AlphaZero 的训练过程,同时也能通过亲自对阵,来感受自己训练出来的 AI 慢慢变强的过程。
经过实践发现,对于在 6*6 的棋盘上下 4 子棋这种情况,大约通过 500~1000 局的 self-play 训练(2 小时),就能训练出比较靠谱的 AI;对于在 8*8 的棋盘上下 5 子棋这种情况,通过大约 2000~3000 局自我对弈训练(2 天),也能得到比较靠谱的 AI。所以虽然贫穷,但我们还是可以去亲身感受最前沿成果的魅力!完整代码以及 4 个训练好的模型已经上传到了 github:https://github.com/junxiaosong/AlphaZero_Gomoku
我们先来看两局训练好的 AI 模型(3000 局 self-play 训练得到)对弈的情况,简单感受一下:

每一步棋执行 400 次 MCTS 模拟

每一步棋执行 800 次 MCTS 模拟
从上面的对局样例可以看到,AI 已经学会了怎么下五子棋,知道什么时候要去堵,怎么样才能赢,按我自己对阵 AI 的感受来说,要赢 AI 已经不容易了,经常会打平,有时候稍不留神就会输掉。
这里有一点需要说明,上面展示的两局 AI 对弈中,AI 执行每一步棋的时候分别只执行了 400 次和 800 次 MCTS 模拟,进一步增大模拟次数能够显著增强 AI 的实力,参见 AlphaZero 论文中的 Figure 2(注:AlphaZero 在训练的时候每一步只执行 800 次 MCTS simulations,但在评估性能的时候每一步棋都会执行几十万甚至上百万次 MCTS 模拟)。
下面,我结合 AlphaZero 算法本身,以及 github 上的具体实现,从自我对局和策略价值网络训练两个方面来展开介绍一下整个训练过程,以及自己实验过程中的一些观察和体会。
自我对局(self-play)
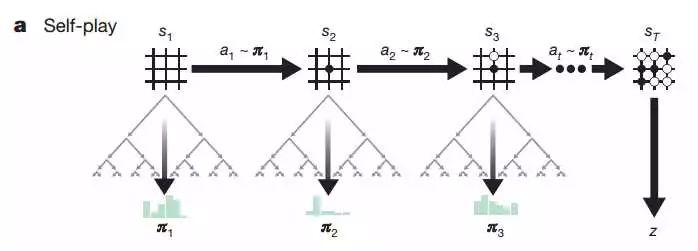
self-play 过程示意图
完全基于 self-play 来学习进化是 AlphaZero 的最大卖点,也是整个训练过程中最关键也是最耗时的环节。这里有几个关键点需要说明:
1. 使用哪个模型来生成 self-play 数据?
在 AlphaGo Zero 版本中,我们需要同时保存当前最新的模型和通过评估得到的历史最优的模型,self-play 数据始终由最优模型生成,用于不断训练更新当前最新的模型,然后每隔一段时间评估当前最新模型和最优模型的优劣,决定是否更新历史最优模型。
而到了 AlphaZero 版本中,这一过程得到简化,我们只保存当前最新模型,self-play 数据直接由当前最新模型生成,并用于训练更新自身。直观上我们可能会感觉使用当前最优模型生成的 self-play 数据可能质量更高,收敛更好,但是在尝试过两种方案之后,我们发现,在 6*6 棋盘上下 4 子棋这种情况下,直接使用最新模型生成 self-play 数据训练的话大约 500 局之后就能得到比较好的模型了,而不断维护最优模型并由最优模型生成 self-play 数据的话大约需要 1500 局之后才能达到类似的效果,这和 AlphaZero 论文中训练 34 小时的 AlphaZero 胜过训练 72 小时的 AlphaGo Zero 的结果也是吻合的。
个人猜测,不断使用最新模型来生成 self-play 数据可能也是一个比较有效的 exploration 手段,首先当前最新模型相比于历史最优模型一般不会差很多,所以对局数据的质量其实也是比较有保证的,同时模型的不断变化使得我们能覆盖到更多典型的数据,从而加快收敛。
2. 如何保证 self-play 生成的数据具有多样性?
一个有效的策略价值模型,需要在各种局面下都能比较准确的评估当前局面的优劣以及当前局面下各个 action 的相对优劣,要训练出这样的策略价值模型,就需要在 self-play 的过程中尽可能的覆盖到各种各样的局面。
前面提到,不断使用最新的模型来生成 self-play 数据可能在一定程度上有助于覆盖到更多的局面,但仅靠这么一点模型的差异是不够的,所以在强化学习算法中,一般都会有特意设计的 exploration 的手段,这是至关重要的。
在 AlphaGo Zero 论文中,每一个 self-play 对局的前 30 步,action 是根据正比于 MCTS 根节点处每个分支的访问次数的概率采样得到的(也就是上面 Self-play 示意图中的 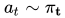
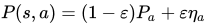

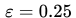
3. 始终从当前 player 的视角去保存 self-play 数据
在 self-play 过程中,我们会收集一系列的 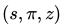
4. self-play 数据的扩充
围棋具有旋转和镜像翻转等价的性质,其实五子棋也具有同样的性质。在 AlphaGo Zero 中,这一性质被充分的利用来扩充 self-play 数据,以及在 MCTS 评估叶子节点的时候提高局面评估的可靠性。但是在 AlphaZero 中,因为要同时考虑国际象棋和将棋这两种不满足旋转等价性质的棋类,所以对于围棋也没有利用这个性质。
而在我们的实现中,因为生成 self-play 数据本身就是计算的瓶颈,为了能够在算力非常弱的情况下尽快的收集数据训练模型,每一局 self-play 结束后,我们会把这一局的数据进行旋转和镜像翻转,将 8 种等价情况的数据全部存入 self-play 的 data buffer 中。这种旋转和翻转的数据扩充在一定程度上也能提高 self-play 数据的多样性和均衡性。
策略价值网络训练

策略价值网络训练示意图
所谓的策略价值网络,就是在给定当前局面 s 的情况下,返回当前局面下每一个可行 action 的概率以及当前局面评分的模型。前面 self-play 收集到的数据就是用来训练策略价值网络的,而训练更新的策略价值网络也会马上被应用到 MCTS 中进行后面的 self-play,以生成更优质的 self-play 数据。两者相互嵌套,相互促进,就构成了整个训练的循环。下面还是从几个点分别进行说明:
1. 局面描述方式
在 AlphaGo Zero 中,一共使用了 17 个 19✖️19 的二值特征平面来描述当前局面,其中前 16 个平面描述了最近 8 步对应的双方 player 的棋子位置,最后一个平面描述当前 player 对应的棋子颜色,其实也就是先后手。
在我们的实现中,对局面的描述进行了极大的简化,以 8✖️8 的棋盘为例,我们只使用了 4 个 8✖️8 的二值特征平面,其中前两个平面分别表示当前 player 的棋子位置和对手 player 的棋子位置,有棋子的位置是 1,没棋子的位置是 0。然后第三个平面表示对手 player 最近一步的落子位置,也就是整个平面只有一个位置是 1,其余全部是 0。 第四个平面,也就是最后一个平面表示的是当前 player 是不是先手 player,如果是先手 player 则整个平面全部为 1,否则全部为 0。
其实在最开始尝试的时候,我只用了前两个平面,也就是双方的棋子的位置,因为直观感觉这两个平面已经足够表达整个完整的局面了。但是后来在增加了后两个特征平面之后,训练的效果有了比较明显的改善。个人猜想,因为在五子棋中,我方下一步的落子位置往往会在对手前一步落子位置的附近,所以加入的第三个平面对于策略网络确定哪些位置应该具有更高的落子概率具有比较大的指示意义,可能有助有训练。同时,因为先手在对弈中其实是很占优势的,所以在局面上棋子位置相似的情况下,当前局面的优劣和当前 player 到底是先手还是后手十分相关,所以第四个指示先后手的平面可能对于价值网络具有比较大的意义。
2. 网络结构
在 AlphaGo Zero 中,输入局面首先通过了 20 或 40 个基于卷积的残差网络模块,然后再分别接上 2 层或 3 层网络得到策略和价值输出,整个网络的层数有 40 多或 80 多层,训练和预测的时候都十分缓慢。
所以在我们的实现中,对这个网络结构进行了极大的简化,最开始是公共的 3 层全卷积网络,分别使用 32、64 和 128 个 3✖️3 的 filter,使用 ReLu 激活函数。然后再分成 policy 和 value 两个输出,在 policy 这一端,先使用 4 个 1✖️1 的 filter 进行降维,再接一个全连接层,使用 softmax 非线性函数直接输出棋盘上每个位置的落子概率;在 value 这一端,先使用 2 个 1✖️1 的 filter 进行降维,再接一个 64 个神经元的全连接层,最后再接一个全连接层,使用 tanh 非线性函数直接输出 [-1,1] 之间的局面评分。整个策略价值网络的深度只有 5~6 层,训练和预测都相对比较快。
3. 训练目标
前面提到,策略价值网络的输入是当前的局面描述 s,输出是当前局面下每一个可行 action 的概率 P 以及当前局面的评分 v ,而用来训练策略价值网络的是我们在 self-play 过程中收集的一系列的
根据上面的策略价值网络训练示意图,我们训练的目标是让策略价值网络输出的 action 概率 P 更加接近 MCTS 输出的概率 π , 让策略价值网络输出的局面评分 v 能更准确的预测真实的对局结果 z 。
从优化的角度来说,我们是在 self-play 数据集上不断的最小化损失函数: 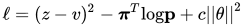
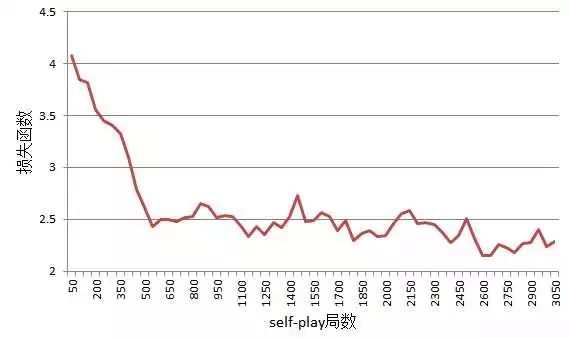
下图展示的是一次在 8✖️8 棋盘上进行五子棋训练的过程中损失函数随着 self-play 局数变化的情况,这次实验一共进行了 3050 局对局,损失函数从最开始的 4 点几慢慢减小到了 2.2 左右。
在训练过程中,除了观察到损失函数在慢慢减小,我们一般还会关注策略价值网络输出的策略(输出的落子概率分布)的 entropy 的变化情况。
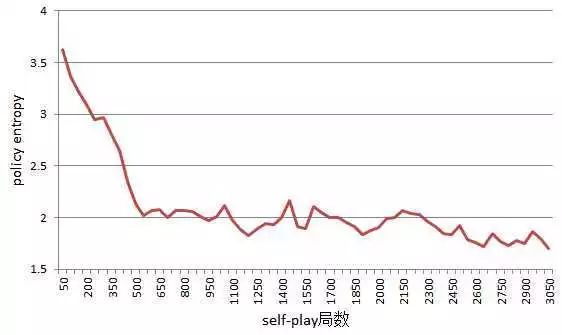
正常来讲,最开始的时候,我们的策略网络基本上是均匀的随机输出落子的概率,所以 entropy 会比较大。随着训练过程的慢慢推进,策略网络会慢慢学会在不同的局面下哪些位置应该有更大的落子概率,也就是说落子概率的分布不再均匀,会有比较强的偏向,这样 entropy 就会变小。
也正是由于策略网络输出概率的偏向,才能帮助 MCTS 在搜索过程中能够在更有潜力的位置进行更多的模拟,从而在比较少的模拟次数下达到比较好的性能。
下图展示的是同一次训练过程中观察到的策略网络输出策略的 entropy 的变化情况。
另外,在漫长的训练过程中,我们最希望看到的当然是我们训练的 AI 正在慢慢变强。所以虽然在 AlphaZero 的算法流程中已经不再需要通过定期评估来更新最优策略,在我们的实现中还是每隔 50 次 self-play 对局就对当前的 AI 模型进行一次评估,评估的方式是使用当前最新的 AI 模型和纯的 MCTS AI(基于随机 rollout)对战 10 局。
pure MCTS AI 最开始每一步使用 1000 次模拟,当被我们训练的 AI 模型 10:0 打败时,pure MCTS AI 就升级到每一步使用 2000 次模拟,以此类推,不断增强,而我们训练的 AlphaZero AI 模型每一步始终只使用 400 次模拟。在上面那次 3050 局自我对局的训练实验中,我们观察到:
经过 550 局,AlphaZero VS pure_MCTS 1000 首次达到 10:0
经过 1300 局,AlphaZero VS pure_MCTS 2000 首次达到 10:0
经过 1750 局,AlphaZero VS pure_MCTS 3000 首次达到 10:0
经过 2450 局,AlphaZero VS pure_MCTS 4000 取得 8 胜 1 平 1 负
经过 2850 局,AlphaZero VS pure_MCTS 4000 取得 9 胜 1 负。
OK,到这里整个 AlphaZero 实战过程就基本介绍完了,感兴趣的小伙伴可以下载我 github 上的代码进行尝试。为了方便大家直接和已经训练好的模型进行对战体验,我专门实现了一个纯 numpy 版本的策略价值前向网络,所以只要装了 python 和 numpy 就可以直接进行人机对战啦,祝大家玩的愉快!^_^
参考文献
AlphaZero: Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
AlphaGo Zero: Mastering the game of Go without human knowledge

CCF ADL 系列又一诚意课程
两位全球计算机领域 Top 10 大神加盟
——韩家炜 & Philip S Yu
共 13 位专家,覆盖计算机学科研究热点
▼▼▼

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
AlphaGo 战胜世界第一棋手,一页核心算法总结必胜秘诀
▼▼▼

