Bert 之后:预训练语言模型与自然语言生成
作者:老宋的茶书会
知乎专栏:NLP与深度学习
研究方向:自然语言处理
前言
Bert 在自然语言理解领域获得了巨大的成功,但是在自然语言生成领域却表现不佳,这是由于 Bert 训练时所采用的语言模型所决定的。
Bert 这种 DAE 语言模型只学习到了词的上下文表征的能力,即理解语言的能力,但没有学习到如何组织语言的能力,可以参见以下 XLNet 中前言部分所提到的 AR 与 AE 的介绍。如果想要将 Bert 应用到生成领域,那么 Decoder 的设计是一个相当大的难题。
最近,微软的两篇文章做出了这方面的尝试,并获得了不错的结果,十分值得借鉴。同时考虑到之前 GPT 与 GPT 2.0 有关于生成的部分,因此放到一起讨论。
从神经科学的角度看
神经科学中,语言中枢控制着人类的语言活动, 其中,最重要的是布洛卡氏区与韦尼克区。而有趣的是, 二者的功能与我们目前语言模型的发展有着相似之处:
布洛卡氏区主要负责的是我们组织语言的能力, 即自然语言生成。
韦尼克区则是负责我们理解语言的能力, 即自然语言理解。
从这个角度看,对于分类问题,我们也只是需要理解能力(韦尼克区),但对于对话问题,我们两个都需要(布洛卡氏区)。以文本对话而言, 语言先通过视觉皮质转化为某种神经信号传入到韦尼克区使我们理解语言,然后理解后的信息经过弓状束传递到布洛卡氏区来组织语言,生成对话。
从 Bert 以及 XLNet 在阅读理解问题上的进展,可以看出, 预训练语言模型对于理解问题是相当有效的,相信这方面还会有更大的突破。
而对于生成问题,通过大规模数据来训练语言模型的思路也是相当可靠的,这需要设计合理的语言模型。
而从文本对话的过程来看,理解到生成之间的连接依旧需要探讨, 或许以 Bert 为 Encoder,再以对应的 AR 语言模型为 Decoder, 然后进行预训练能够解决这种问题。
但一个关键的问题是: 分类问题与生成问题所激活的神经元是否有相同部分。如果有相同部分,似乎多任务学习更加符合;如果没有,那么分别进行生成式与分类式的预训练语言模型的实现似乎更加合适。由于对多任务学习不是很了解,不知道多任务学习能否提高多个任务的表现能力,这方面有大神的可以解释一下。
当然,咱也没有卡,咱也不敢训,只能提提思路了。话不多说,我们来看看下面这几篇文章是怎么做的吧。
GPT 1.0
GPT 1.0 其实并没有涉及到关于生成的部分,但考虑到GPT 2.0 由其延伸,因此这里小抠一下 GPT 1.0 的细节,具体的讨论放在 GPT 2.0 中。
总体来说,GPT 1.0 与 Bert 很相似,同样是作为二阶段的模型,只是在细节处可能相差较大。
1, 语言模型
对于给定的 tokens 

从上式可以看出, GPT 1.0 是具有句子的生成能力的, 可惜 GPT 1.0 没有关于生成方面的实验。
2, 单向Transformer
GPT 1.0 采用单向的 Transformer 来作为特征抓取器,这是由于语言模型本身决定的,因为是从前往后生成单词的。
3, 微调
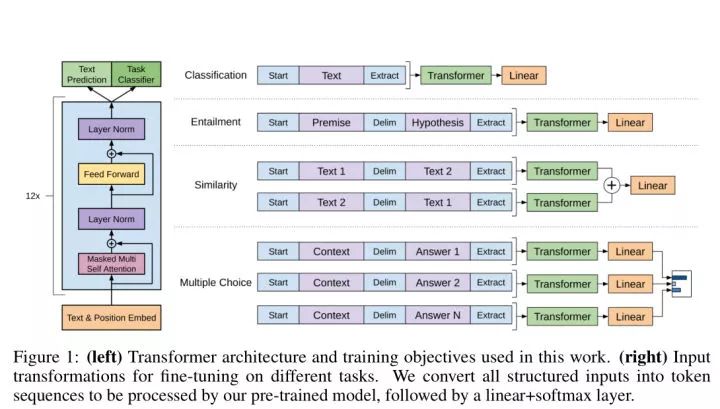
微调阶段也没啥好说的,也就那样,这里就不细细讨论了。
GPT 2.0
1, 语言模型与单向Transofmer
GPT 2.0 的语言模型与 GPT 1.0 很相似, 变化很少,如Layer Normalization 的转移和添加等,且这部分也不是文章的主要创新点,因此我略过了。
2, 大就完事了
GPT 2.0 相较 1.0 来说,在数据方面的改动很大,主要包括以下几个方面:
大规模,高质量,跨领域数据:WebText
更深的 Transoformer 模型
GPT 2.0 验证了数据的重要性,即使单纯的从数据角度入手,效果就可以获得巨大的提升。
3, 如何适配下游任务
对于下游任务来说, GPT 2.0 不再采用微调的方式来做,而是直接用训好的语言模型来做,那么它怎么就能够又能做分类,又能做翻译,还能做文本摘要的呢?
答案很风骚:GPT 2.0 在做下游任务时,添加了一些引导字符来预测目标,它的输出与语言模型一样,都是一个单词。
那么 GPT 2.0 是如何做生成类任务的呢?那就是连续不断的进行预测,预测 n 次(设定), 然后把这 n 个token 连在一起,取其中的几句话来做为生成的文本。
4, 思想的转变
GPT 2.0 相较GPT 1.0 而言,改变最大的思想,具体来说, GPT 2.0 依旧是二阶段的框架,但对于下游任务,不再采用有监督的进行微调,而是采用无监督的方式直接去做。
作者认为,通过大模型,大规模数据,GPT 2.0 能够学习到很多通用知识,直接拿这些通用知识去做下游任务就可以获得很好的结果。这其实就是证明预训练语言模型这条道路的正确性,预训练语言模型的确能够学习到语言的很多信息,并具有很强的泛化能力。
但, 真的不需要微调吗?我认为接下来一段时间的预训练语言模型的发展依旧会是二阶段或三阶段的框架: 预训练语言模型 + [多任务学习] + [在特定数据集上预训练] + 下游任务微调。
不可否认的是, GPT 2.0 同样打开了一个新思路, 如果有一天, 模型足够大,数据足够多,我们还需要微调吗?
MASS
我个人觉得 MASS 这篇文章在预训练语言模型 + 自然语言生成具有很强的开创意义,当然,跟 Bert 比不了,但也不至于默默无闻啊, 果然,还是 Google 会宣传。
MASS 采用 Encoder-Decoder 框架来对文本生成进行学习, Encoder 与 Decoder 部分都采用 Transoformer 来作为特征提取器, 我们来具体看看它是怎么做的吧。
1, 语言模型思想
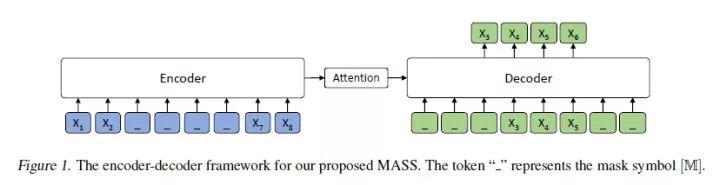
MASS 的思想很简单, 对于输入序列 x, mask 该句从 u 到 v 位置上的token,记为 

同时, MASS 将 Seq2Seq 的思想融入进去,这样就可以同时预测连续的词,从模型上看,我们也能推断它的生成效果是要好于Bert 的。MASS 的损失函数为:

2, MASS and Bert
前面提到, MASS 中有一个重要的参数 k, 该参数决定对于输入序列 x, 多少个 token 会被 mask 掉, 而 Bert 中会 mask 掉 15% 的token(MASS 3.2中是不是讲错了,并不是mask一个token呀), 且 Bert 属于随机 mask, 而 MASS 是 mask 连续的 token。
MASS 原论文中谈及 Bert ,认为 Bert 一句话中只 mask 掉一个token, 因此它有一个比较:
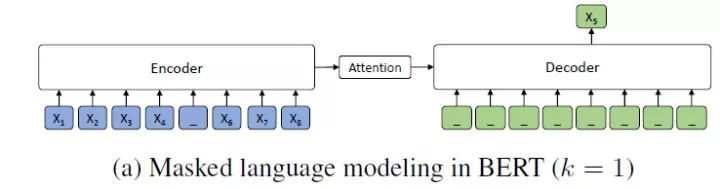
而 Bert 其实在一句话中会 mask 掉15% 的token, 难道是我理解有问题?
我还一直疑惑为什么 Bert 不像 Word2Vec 一样,每次只 mask 掉一个 token, 这样不就更能把握上下文信息吗?有大佬麻烦指教一下。
3, MASS 与 GPT
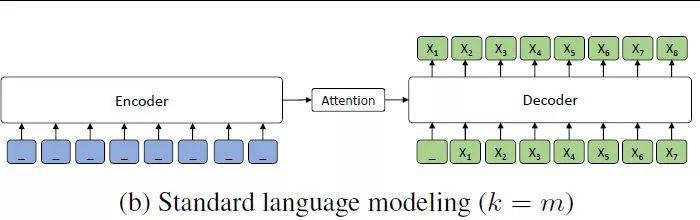
当 k = m 时, 与 GPT 的情形完全一样。
4, 为何 MASS 适合生成
首先, 通过 Seq2Seq 框架来预测被 mask 的tokens 使得 Encoder 去学习没有被 mask 的 token 的信息, 而Decoder 去学习如何从 Encoder 中提取有效的信息。
然后, 与预测离散的 tokens相比,Decoder 通过预测连续的 tokens, 其能够建立很好的语言生成能力。
最后, 通过输入与输出的 mask 匹配, 使得 Decoder 能够从Encoder 中提取到有意义的信息,而不是利用之前的信息。(其实是一句有用的废话)
MASS 小结
MASS 总结来说有以下几点重新:
引入了 Seq2Seq 来训练预训练模型。
mask 掉的是一段连续的tokens而不是离散的 mask, 有助于模型生成语言的能力。
Encoder 中是 mask 掉的序列,而 Decoder 中是对应被mask的 tokens。
UNILM
UNILM 就厉害了, 它想直接训一个预训练语言模型, 又能做自然语言理解,又能做自然语言生成。UNILM 的基本单元依旧是多层的 Transformer, 不同的是,这些 Transformer 网络要在多个语言模型上进行预训练: unidirectional LM, bidirectional LM 和 Seq2Seq LM , 下文会忽略一些细枝末节,主要专注如何预训练语言模型的。
UNILM 这篇文章,厉害在同时使用多个预训练语言模型训练这个思想, 至于怎么做,我觉得倒是其次,不是很重要。
大致的框架如下:
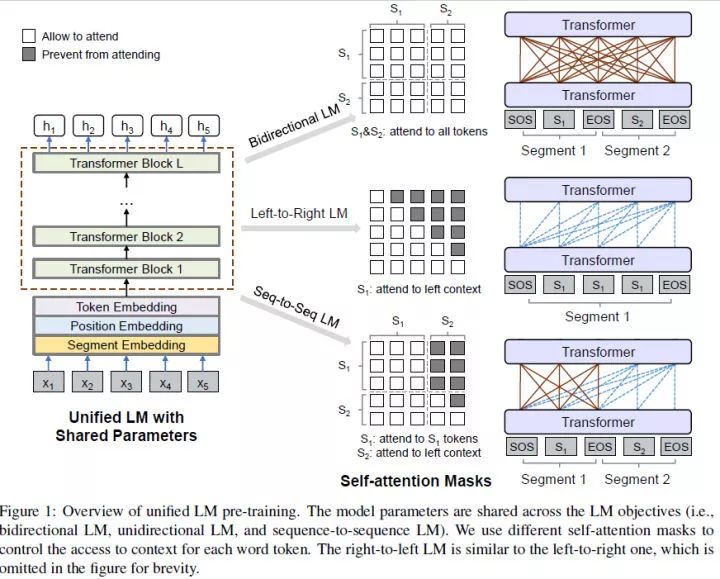
1, Input Representation
这部分与Bert 大同小异, 不过还是得细说一下。UNILM 的输入为单词序列,序列可能是一个针对unidirectional LMs的文本段, 也有可能是针对 bidirectional LM 和 Seq2Seq LM的一对文本段。输入的序列格式如下:
[SOS] + segment1 + [EOS]
[SOS] + segment1 + [EOS] + segment2 + [EOS]与 Bert 相同, 模型的输入都为:
token embedding + position embedding + segment embedding还有一点是, UNILM 将所有的 token 都处理成为 subword, 可以增强生成模型的表现能力,emmm, maybe?我觉得不是重点。
2,Unidirectional LM
输入单段落, UNILM 同时采用 left-to-right LM 与 right-to-left LM 来做(有点像 ELMO), 这与 Bert 的方式有很大的区别, 我想这是从生成方面考虑因此如此设计, 细节,懒得抠了, 感兴趣的可以看看。
3,Bidirectional LM
输入段落对, 其实就是 Bert 的语言模型, 没啥好说的, 略。
4, Seq2Seq LM
输入段落对, 第一段采用 Bidirectional LM 的方式编码, 而对于第二句采用 Unidirectional LM 的方式解码, 然后同时训练。
5, Next Sentence Prediction
没啥好说的,和 Bert 里面差不多,略。
6, 参数从 Bert-large 初始化
Questions
1, MASS 中的 mask 策略?
对于 MASS 而言, 其采用随机 Mask 一段连续的 tokens, 有没有更佳的方式来学习, 比如, 30% mask 前面的 tokens, 20% mask 后面的tokens, 50% 随机mask 中间tokens。这是考虑到对于句子生成来说, 开头和结尾可能需要更充分的训练与学习。
或者说以前面一句来预测后面一句,以对话的上文来预测下文等。
2, Bert 能不能直接做 Encoder 端
用已经学习好的预训练语言模型(如Bert)来做 Encoder 端(Freeze/unFreeze Encoder 端的参数)会不会更能把握输入序列的信息, 因为毕竟预训练语言模型在自然语言理解上已经获得了很大的成功,Decoder 只要学习如何从理解后的信息中提取信息来生成语言即可,这样能够大大减轻训练的时间和复杂度,或许效果也会更好。
3, MASS vs UNILM
二者相比,无疑 UNILM 更胜一筹,无论是从创新角度还是模型复杂度与精致程度而言。但对于未来的发展来说,我个人更看好 Encoder-Decoder 这种方式, 语言生成是基于语言理解的基础上的,那么语言理解所诞生的预训练语言模型为何不直接用到生成预训练模型里面呢?有必要从头训吗?有必要生成+ 理解一起训吗?
最后
其实,我想表达的核心在于, 理解与生成是否共存? 如果共存, 以哪种方式? 多任务学习会不会是一个解法? GPT 2.0 这种单纯堆数据和模型 + 无监督下游任务会不会是正解? 有没有可能用多阶段的预训练任务来做,先做理解,然后以理解的预训练语言模型为Encoder 来做生成预训练, 最后再在下游任务微调生成?还是像 UNILM 那样走多预训练语言模型共同训练的方式?
我现在倒是觉得, 目前预训练模型走的路子与认知神经科学有着很相似的地方。自然语言理解目前已经实现突破, 相信接下来自然语言生成将成为主要战场。
热闹是别人的,板凳是自己的。 我还是默默等大佬们做出东西来,看看怎么用到应用层面吧,看看就好。
我觉得可以去了解了解神经科学,万一挖到宝了呢,嘿嘿嘿。
觉得写得不错,点个赞再走,好不啦,码字很累的。
Reference
[1] GPT1 - Improving Language Understanding by Generative Pre-Training
[2] GPT2 - Language Models are Unsupervised Multitask Learners
[3] MASS - Masked Sequence to Sequence Pre-training for Language Generation
[4] UNILM - Unified Language Model Pre-training for Natural Language Understanding and Generation
本文由作者原创授权AINLP首发于公众号平台,点击'阅读原文'直达原文链接,欢迎投稿,AI、NLP均可。




