【泡泡图灵智库】四叉树加速的实时单目稠密建图(IROS)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Quadtree-accelerated Real-time Monocular Dense Mapping
来源:IROS 2018
编译:李雨昊
审核:万应才
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——四叉树加速的实时单目稠密建图,该文章发表于IROS 2018。
本文中,作者提出一种新兴建图方法,能够实时地从单个移动的相机中生成高质量的稠密地图。通过利用强度影像的四叉树结构,来减少在估计多分辨率的深度图时所需的计算负担。本文提出了基于四叉树的像素选择和动态信念传播方法来加速建图过程:这些选择的像素根据它们在四叉树中的层级并利用计算资源进行优化。这些计算得到的深度估计进一步用于插值,并根据时相融合进全分辨率深度图中,使用截断符号距离函数TSDF生成稠密三维地图。作者在公开数据集上将本文方法与现有主流方法进行了对比。搭载在UAV上的导航飞行测试进一步验证了本文方法在便携式设备上的实用性和效能。
主要贡献
1、本文提出一种新兴的像素选择方法,根据影像中的四叉树结构层级选择像素来估计深度,选择的像素覆盖了整幅影像并突出了高纹理区域;
2、本文提出一种由粗到细的方式使用动态信念传播方法估计出选择像素的深度。根据像素所处的四叉树层级利用计算资源对像素进行优化。优化过程通过跳过稀疏分辨率像素在保持效能的同时产生高精度的深度估计;
3、本文建立了一种使用单一的相机和IMU的单目稠密重建系统,可以生成高质量的稠密地图,该地图可以直接用于3D重建和UAV导航飞行。
算法流程
本文的方法灵感来自于对在单目深度估计中的观察:1、在强度影像中处于同一四叉树块中的像素具有相似的强度和深度值。四叉树是一种广泛使用的结构,像素根据其局部纹理以树结构组织起来,具有相同强度值的像素可以通过将它们归入到相同四叉树块中而将它们聚类到一起,并以相应的分辨率进行表示。如图1所示,在大多数情况下,在强度影像中的一个像素所处的四叉树层级与其在深度影像中的层级一致甚至更好。这也就意味着在深度影像中共享相同四叉树块的像素在处于深度影像中也处于相同的块,反之亦然。换句话说,像素的深度可以用其在对应分辨率下强度影像的四叉树层级来表示。2、在低纹理区域进行深度估计和最小化考虑到块匹配损失和深度图平滑的最小化能量函数对深度图进行平滑的时候常使用全局优化。但是这些过程中的高昂计算使得他们很难在实时应用中得到广泛使用。
受到上述观察的激发,作者提出一种新兴的单目稠密建图方法,在多分辨率下根据其相应强度影像的四叉树结构进行深度图估计时,可以减少由于采用全局优化方法带来的计算负担。具体而言,根据像素待估计深度图分辨率相对应的强度影像的四叉树结构,选择一定的像素。使用动态信念传播方法以一种由粗到细的方式,估计出这些选择出来的像素的深度,动态信念传播从相应分辨率提取深度以保持效率。所有深度估计值以插值的方式形成全稠密深度图,并将过往的深度图进行时相融合。最后将全稠密深度图融合成一个高质量的全局三维地图。

图1 强度影像以及对应深度影像的四叉树划分
主要步骤有:基于四叉树的像素选择、匹配损失向量的计算、动态信念传播、深度插值与时相融合、TSDF融合。

图2 算法流程
具体算法介绍
作者使用的相机姿态是通过VINS系统得到的。
1、基于四叉树的像素选择
作者使用四叉树来寻找每个像素最合适的分辨率表达方式。对于每张输入的影像Ik,计算三层四叉树结构,从4x4的精细级到16x16的粗略级像素块。如图1所示,处于相同四叉树块的像素拥有相似的强度,因此也可以用来估计出深度。对四叉树块中的第一个像素计算匹配损失向量,并利用动态信念传播估计出深度。图3显示了基于影像四叉树结构的像素选择过程。

图3 像素选择示例 红点即为选择像素点
没被选中的像素通过插值的方式得到全稠密深度图。利用根据四叉树结构选择的像素,在估计深度图的过程中可以做到在不牺牲精度的情况下保持高效率。
2、匹配损失向量计算
计算被选中像素的匹配损失向量用于动态信念传播。本文中选择附近相邻5个帧作为测量帧,作者在逆深度空间均匀采样了Nd个深度值。采样的深度值d与其对应深度指数l之间的关系为:
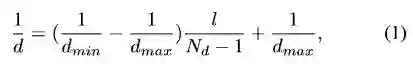
dmax和dmin是采样深度的最大和最小值。对于每个选中的像素uk,深度d的损失定义为:
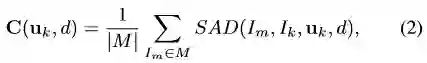
M为选择的测量帧列表,SAD为两幅影像对应像素3x3 patchs差的绝对值之和。
3、动态信念传播
动态信念传播用来估计分布在整幅影像上选中像素的深度值。信念传播的工作方法为:通过传递影像格网连接的信息来估计深度图。信息是Nd维向量,代表像素从其到邻域像素深度分布信念。影像格网中的每个像素向其邻域4像素传递或接受信息。最终的信念向量为式3:
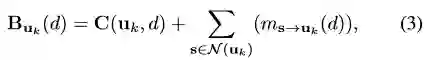
使得该信念向量取得最小值的深度作为估计出来的深度值。
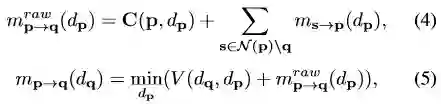
信念传播的核心部分是迭代更新信息,全部的信息初始化为零向量,并按照式4-5进行更新。动态信念传播通过两种方式进行加速。第一,通过简化正则化函数V(dq,dp)以及使用并行加速使得信息更新时间减少到O(log(Nd))。第二,通过估计选中像素在不同分辨率下的四叉树层级的对应深度减少更新的次数。
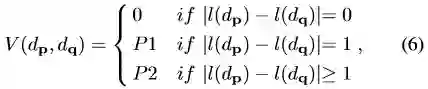
作者使用从SGM一文得到的正则化函数式6以及使用并行加速对信息更新时间进行了进一步削减。
l(dp)是在函数1(公式1)中定义的深度dp的深度指数。P1、P2控制深度图的平滑程度。作者提到虽然使用的正则化函数和SGM一文中是一样的,但是信息的传递和更新是不同的。SGM中整合了几条不同预定义路径的损失,而本文中的方法是在二维影像格网上进行传递的。二维全局优化使得本文的方法可以得到更加平滑的深度图。并且依赖并行化操作的方式减少了信息从p像素传递到q像素的时间。更新时间为O(log(Nd)) 的算法流程图如下:

信息以一种由粗到细的方式进行更新,不仅可以加速收敛还可以提取不同分辨率下的深度。与标准信念传播不同的是,本文的损失量基于选择的四叉树像素。损失量对于四叉树选中的像素是有效的,并且等同于前述章节中介绍的匹配损失向量。该损失量按照传统方法进行了下采样,并且根据选中的像素数量进行了平均。尽管由粗到细的方式可以加速信息的收敛,在精细级像素处的计算量对于实时应用仍然是很重的。优化时,动态信念传播提取基于四叉树选中像素的深度估计全过程如图4:
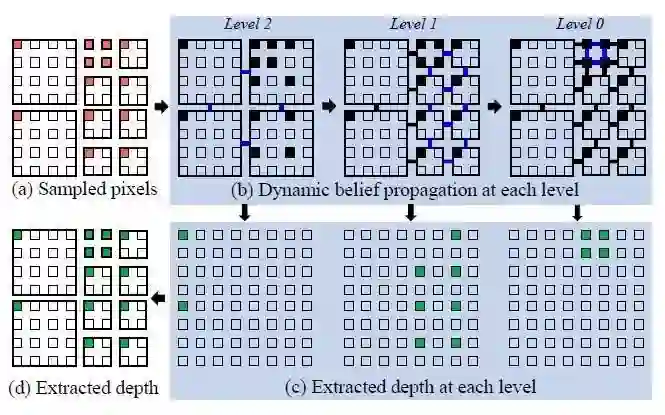
图4 估计像素深度的动态信念传播过程示意图
4、深度插值与时相融合
1)深度插值
为了充分利用那些不在四叉树结构中但是却处于有较大梯度纹理处的像素,作者使用和Engel(具体文章详见paper)相似的方法在GPU上并行估计深度。这些从动态置信传播以及高梯度估计出来的深度组合到一起插值成全分辨率深度图。这些深度值遍布整幅影像并且着重突出了纹理丰富的区域。作者使用最小化最小二乘损失的方法提取全深度图,如式7:
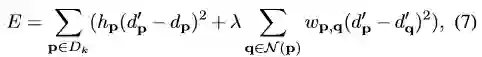
dp’是像素p的融合后的深度值,dp是其对应像素采用本文方法估计出来的像素(不包括插值出来的像素)。Hp是指数函数,0代表dp不存在,反之亦然。wp,q是基于像素p,q强度差的深度差加权,lambda和sigma平方控制了插值深度图的平滑程度。但是解算代价函数E是很耗计算力的,因此作者采用Min(具体文章详见paper)中的方法将其近似看成两个一维插值的问题,先行方向后列方向采用高斯消元法进行解算。
2)时相融合
作者通过概率方式排除错误估计并将过往估计深度图估计融合成为全深度图。使用如式8所示的外点鲁棒模型对每个像素进行估计。
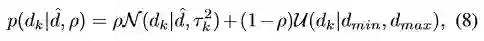
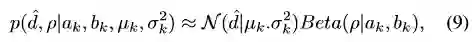
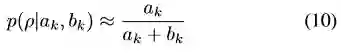
Dhat是深度真值,tong 和rou分别代表内点估计的标准差和置信概率。Vogiatzis(具体文章详见paper)表明匹配两个时刻的分布时,深度模型可以近似采用正态分布和beta分布的乘积来表示式9。作者在整个运行时间内维持一个概率地图完成时相性地估计融合。
5、截断符号距离函数融合
作者主要采用paper-28提出的方法完成全局地图的融合。
主要结果

图5 基于VINS生成的稠密三维地图
首先作者在Middlebury立体数据集上测试了本文方法的深度估计能力,并与标准多级信念传播方法进行了对比。将直接通过动态信念传播的结果与进行全深度插值与时相融合的结果进行了比较,在两个数据上侧结果如图6 ,上侧为估计的深度,下方为对应误差,蓝色表示误差较小。
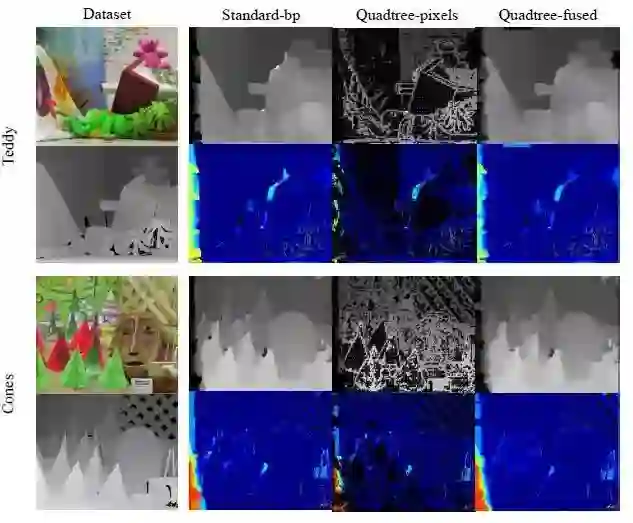
图6 与标准信念传播方法的结果比较
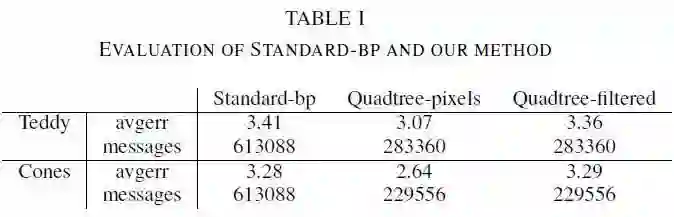
表1 显示了在两个数据上的评估结果 aver代表估计偏差的误差绝对值的平均值,messages代表优化过程中更新的信息的数量,数量越大计算量越大
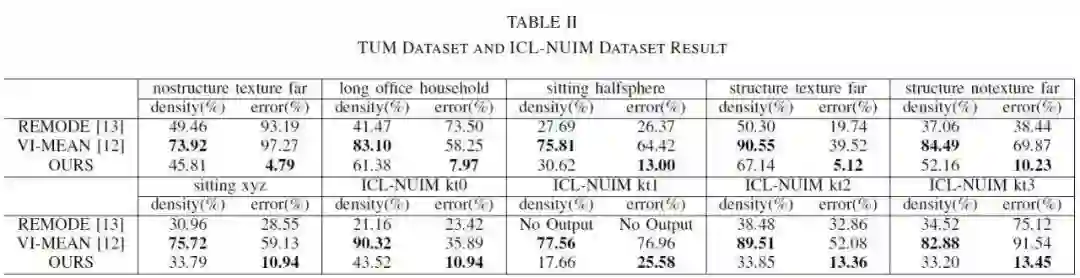
其次作者还在TUM和ICL-NUIM数据集上进行了测试。两个评估标准为深度图的密度和相对误差。密度定义为整幅图像上有效深度估计像素占全部像素的比值;相对误差的定义式如下公式11:
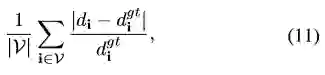
V为有效估计集合,di、digt为估计深度与其深度真值。具体结果如表2所示。
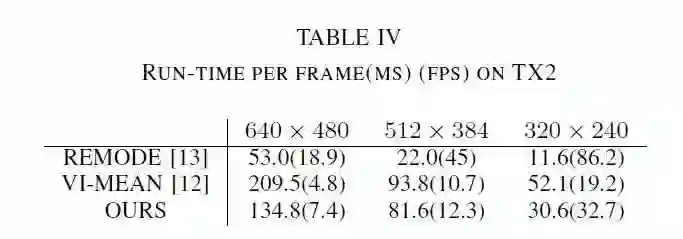
作者在便携设备Nvidia Jetson TX2上进行了效率测试,实验结果如表3所示。

作者将本文方法与另一篇文章中类似使用四叉树查询分辨率估计深度的算法进行了比较。比较结果如表4,可以看出本文方法优于其他方法。
最后作者在无人机上进行了机载测试。无人接搭载了i7计算机以及Nvidia Jetson TX1显卡,可以在输入影像为376x240时达到10Hz的输出结果。结果如图7所示(对于无效深度估计采用黑色像素赋值)

图7 室内外环境UAV机载算法测试

Abstract
In this paper, we propose a novel mapping method that generates high-quality dense maps from a single moving camera in real-time. The quadtree structure of the intensity image is used to reduce the computation burden by estimating the depth map in multiple resolutions. Both the quadtree based pixel selection and the dynamic belief propagation are proposed to speed up the mapping process: pixels are selected and optimized with the computation resource according to their levels in the quadtree. Solved depth estimations are further interpolated and fused temporally into full resolution depth maps and fused into dense 3D maps using truncated signed distance function (TSDF). We compare our method with other state-of-the-art methods using the public datasets. Onboard UAV autonomous flight is also used to further prove the usability and efficiency of our method on portable devices.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com

