摘要
Transformers 在自然语言处理、计算机视觉和音频处理等许多人工智能领域都取得了巨大的成功。因此,自然会引起学术界和工业界研究人员的极大兴趣。到目前为止,各种各样的Transformer变种(即X-formers)已经被提出,但是,关于这些Transformer器变种的系统和全面的文献综述仍然缺乏。在这项综述中,我们提供了一个全面的Transformer综述。我们首先简单介绍了普通的Transformer,然后提出了一个x-former的新分类。接下来,我们将从三个方面介绍不同的x -former架构修改,预训练和应用。最后,展望了未来的研究方向。
https://www.zhuanzhi.ai/paper/f03a47eb6ddb5d23c07f51662f3220a0
引言
Transformer[136]是一种出色的深度学习模型,被广泛应用于自然语言处理(NLP)、计算机视觉(CV)和语音处理等各个领域。Transformer最初是作为一种用于机器翻译的序列到序列模型提出的[129]。后来的工作表明,基于Transformer的预训练模型(PTMs)[100]可以在各种任务上实现最先进的性能。因此,Transformer已经成为NLP的首选架构,特别是对于PTMs。除了语言相关的应用,Transformer也被应用于CV[13, 33, 94],音频处理[15,31,41],甚至其他学科,如化学[113]和生命科学[109]。
由于成功,各种各样的Transformer 变种(即x -former)在过去几年里被提出。这些X-formers从不同的角度改进了vanilla Transformer。
(1) 模型的效率。应用Transformer的一个关键挑战是它在处理长序列时效率低下,这主要是由于自注意力模块的计算和存储复杂性。改进方法包括轻量级注意力(例如稀疏注意变体)和分治法(例如循环和分层机制)。
(2) 模型泛化。由于Transformer是一种灵活的体系结构,并且很少对输入数据的结构偏差进行假设,因此很难对小规模数据进行训练。改进方法包括引入结构偏差或正则化、对大规模无标记数据进行预处理等。
(3) 模型的适应。该工作旨在使Transformer适应特定的下游任务和应用程序。
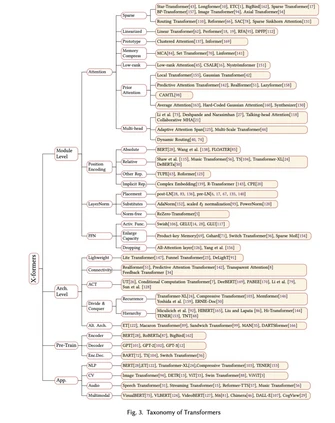
在这个综述中,我们的目的是提供一个Transformer及其变体的全面综述。虽然我们可以根据上面提到的观点来组织x-former,但许多现有的x前辈可能会解决一个或几个问题。例如,稀疏注意变量不仅降低了计算复杂度,而且在输入数据上引入了结构先验,缓解了小数据集上的过拟合问题。因此,将现有的各种X-formers进行分类,并根据它们改进Transformer的方式提出新的分类方法会更有条理: 架构修改、预训练和应用。考虑到本次综述的受众可能来自不同的领域,我们主要关注于一般的架构变体,而只是简单地讨论了预训练和应用的具体变体。
到目前为止,基于普通Transformer的各种模型已经从三个角度被提出:架构修改的类型、预训练的方法和应用。图2给出了Transformer变种的分类说明。

尽管“x-formers”已经证明了他们在各种任务上的能力,但挑战仍然存在。除了目前关注的问题(如效率和泛化),Transformer的进一步改进可能在以下几个方向:
(1) 理论分析。Transformer的体系结构已被证明能够支持具有足够参数的大规模训练数据集。许多工作表明,Transformer比CNN和RNN有更大的容量,因此有能力处理大量的训练数据。当Transformer在足够的数据上进行训练时,它通常比CNN或RNN有更好的性能。一个直观的解释是,Transformer对数据结构没有什么预先假设,因此比CNN和RNN更灵活。然而,理论原因尚不明确,我们需要对Transformer能力进行一些理论分析。
(2) 注意力机制之外的全局交互机制更加完善。Transformer的一个主要优点是使用注意力机制来建模输入数据中节点之间的全局依赖关系。然而,许多研究表明,对大多数节点来说,完全注意力是不必要的。在某种程度上,不可区分地计算所有节点的注意力是低效的。因此,在有效地建模全局交互方面仍有很大的改进空间。一方面,自注意力模块可以看作是一个具有动态连接权的全连接神经网络,通过动态路由聚合非局部信息; 因此,其他动态路由机制是值得探索的替代方法。另一方面,全局交互也可以通过其他类型的神经网络来建模,比如记忆增强模型。
(3) 多模态数据统一框架。在许多应用场景中,集成多模态数据对于提高任务性能是非常有用和必要的。此外,一般的人工智能还需要能够捕获跨不同模式的语义关系。由于Transformer在文本、图像、视频和音频方面取得了巨大的成功,我们有机会建立一个统一的框架,更好地捕捉多模态数据之间的内在联系。但是,在设计中对模式内和模式间的注意还有待改进。