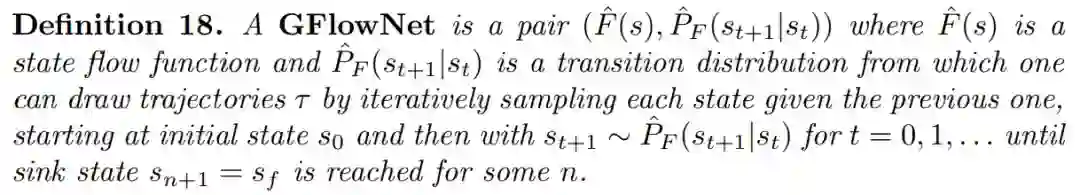机器之心 & ArXiv Weekly Radiostation
本周论文主要包括微软打造的 Florence 模型打破分类、检索等多项 SOTA;历史首次华人博士获 IEEE THMS 汇刊最佳期刊论文奖等。
A Smartphone-Based Adaptive Recognition and Real-Time Monitoring System for Human Activities
Florence: A New Foundation Model for Computer Vision
GFlowNet Foundations
NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion
Rethinking Keypoint Representations: Modeling Keypoints and Poses as Objects for Multi-Person Human Pose Estimation
AI in Games: Techniques, Challenges and Opportunities
Wireless information transfer with fast neutrons
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:A Smartphone-Based Adaptive Recognition and Real-Time Monitoring System for Human Activities
摘要:
该工作提出了一种基于智能手机的自适应 HAR 实时监控系统 (Ada-HAR) ,该系统可以识别 12 个人的活动。其中包括:
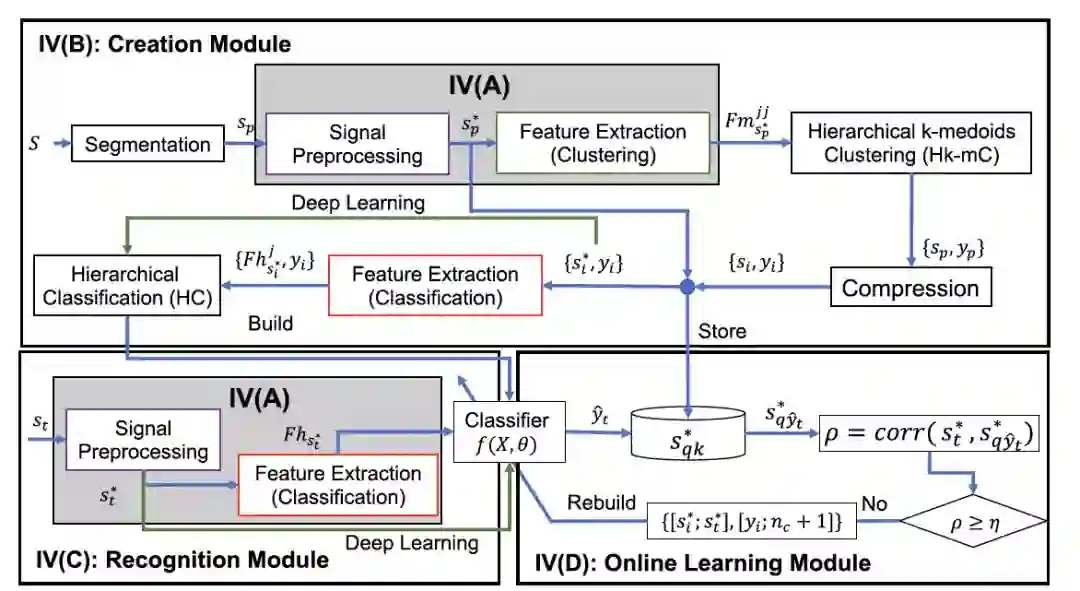
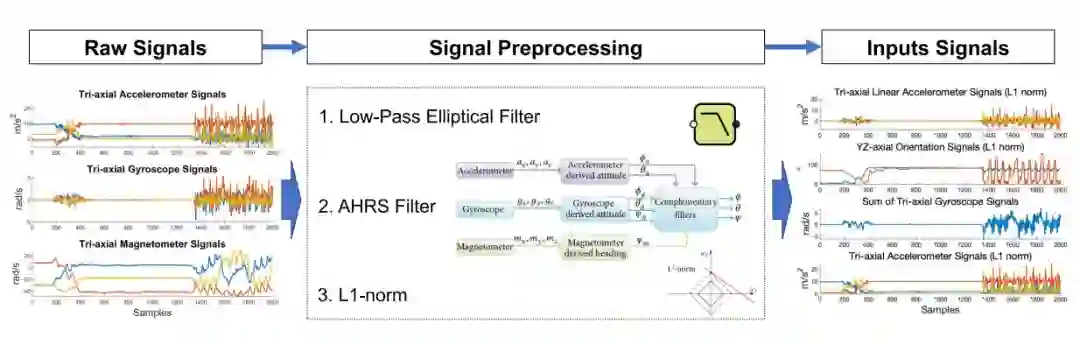
该系统旨在标记原始信号,通过使用分层 k-medoids 聚类自动(Hk-mC) 算法并构建层次分类 (HC) 用于 HAR。最后,开发的 Ada-HAR 系统经过一组受试者的验证,用于监测人类远程和本地 LAN 中的活动。
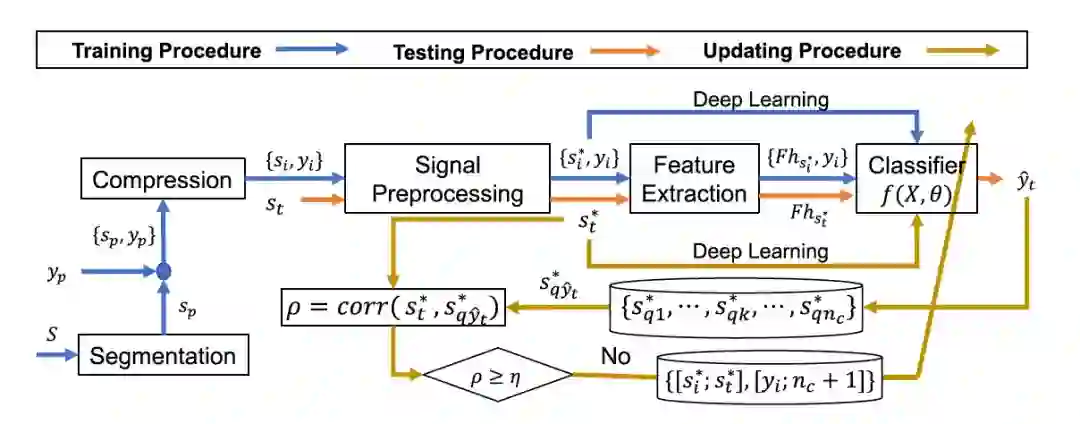
图 2 为建议的 Ada-HAR 系统,包括创建、识别和在线学习模块。
创建模块:采用 Hk-mC 自动标记活动。HC 算法用于建立识别 12 个原始活动的分类器;
识别模块:通过在腰部携带智能手机或将智能手机放在左侧裤兜中,实时对 HAR 的 HC 分类器;
在线学习模块:将以无监督学习方式确定 12 项原始活动中未包含的新活动。同时,对旧分类器进行更新。信号预处理和特征提取模型在创建和识别模块中共享。
![]()
图 2:Ada-HAR 系统的数据流:包括训练(蓝线)、测试(橙线)和更新(浅棕线)程序
![]()
![]()
推荐:
历史首次华人博士获 IEEE THMS 汇刊最佳期刊论文奖。
论文 2:Florence: A New Foundation Model for Computer Vision
摘要:
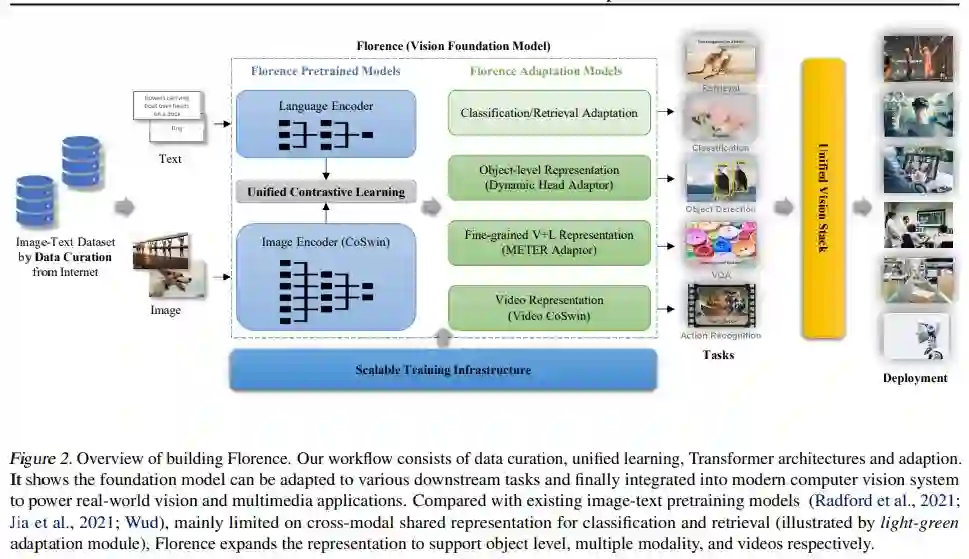
来自微软的研究者另辟蹊径,提出了一种新的计算机视觉基础模型 Florence。在广泛的视觉和视觉 - 语言基准测试中,Florence 显著优于之前的大规模预训练方法,实现了新的 SOTA 结果。
通过结合来自 Web 规模图像 - 文本数据的通用视觉语言表征, Florence 模型可以轻松地适应各种计算机视觉任务,包括分类、检索、目标检测、视觉问答(VQA)、图像描述、视频检索和动作识别。此外,Florence 在许多迁移学习中也表现出卓越的性能,例如全采样(fully sampled)微调、线性探测(linear probing)、小样本迁移和零样本迁移,这些对于视觉基础模型用于通用视觉任务至关重要。Florence 在 44 个表征基准测试中多数都取得了新的 SOTA 结果,例如 ImageNet-1K 零样本分类任务,top-1 准确率为 83.74,top-5 准确率为 97.18;COCO 微调任务获得 62.4 mAP,VQA 任务获得 80.36 mAP。
Florence 模型在有噪声的 Web 规模数据上以同一个目标进行端到端训练,使模型能够在广泛的基准测试中实现同类最佳性能。在广泛的视觉和视觉 - 语言基准测试中,Florence 显著优于之前的大规模预训练方法,实现了新的 SOTA 结果。
构建 Florence 生态系统包括数据管护、模型预训练、任务适配和训练基础设施,如图 2 所示。
![]()
推荐:
微软打造的 Florence 模型打破分类、检索等多项 SOTA。
论文 3:GFlowNet Foundations
摘要:
近日,一篇名为《GFlowNet Foundations》的论文引发了人们的关注,这是一篇图灵奖得主 Yoshua Bengio 一作的新研究,论文长达 70 页。在该研究中,作者提出了名为「生成流网络」(Generative Flow Networks,GFlowNets)的重要概念。
![]()
至于 GFlowNets 作用,论文作者之一 Emmanuel Bengio 也给出了一些回答:「我们可以用 GFlowNets 做很多事情:对集合和图进行一般概率运算,例如可以处理较难的边缘化问题,估计配分函数和自由能,计算给定子集的超集条件概率,估计熵、互信息等。」
本文为主动学习场景提供了形式化理论基础和理论结果集的扩展,同时也为主动学习场景提供了更广泛的方式。GFlowNets 的特性使其非常适合从集合和图的分布中建模和采样,估计自由能和边缘分布,并用于从数据中学习能量函数作为马尔可夫链蒙特卡洛(Monte-Carlo Markov chains,MCMC)一个可学习的、可分摊(amortized)的替代方案。
本文的一个重要贡献是条件 GFlowNet 的概念,可用于计算不同类型(例如集合和图)联合分布上的自由能。这种边缘化还可以估计熵、条件熵和互信息。GFlowNets 还可以泛化,用来估计与丰富结果 (而不是一个纯量奖励函数) 相对应的多个流,这类似于分布式强化学习。
尽管基本的 GFlowNets 更类似于 bandits 算法(因为奖励仅在一系列动作的末尾提供),但 GFlowNets 可以通过扩展来考虑中间奖励,并根据回报进行采样。GFlowNet 的原始公式也仅限于离散和确定性环境,而本文建议如何解除这两种限制。最后,虽然 GFlowNets 的基本公式假设了给定的奖励或能量函数,但本文考虑了 GFlowNet 如何与能量函数进行联合学习,为新颖的基于能量的建模方法、能量函数和 GFlowNet 的模块化结构打开了大门。
推荐:
70 页论文,图灵奖得主 Yoshua Bengio 一作:「生成流网络」拓展深度学习领域
论文 4:NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion
摘要:
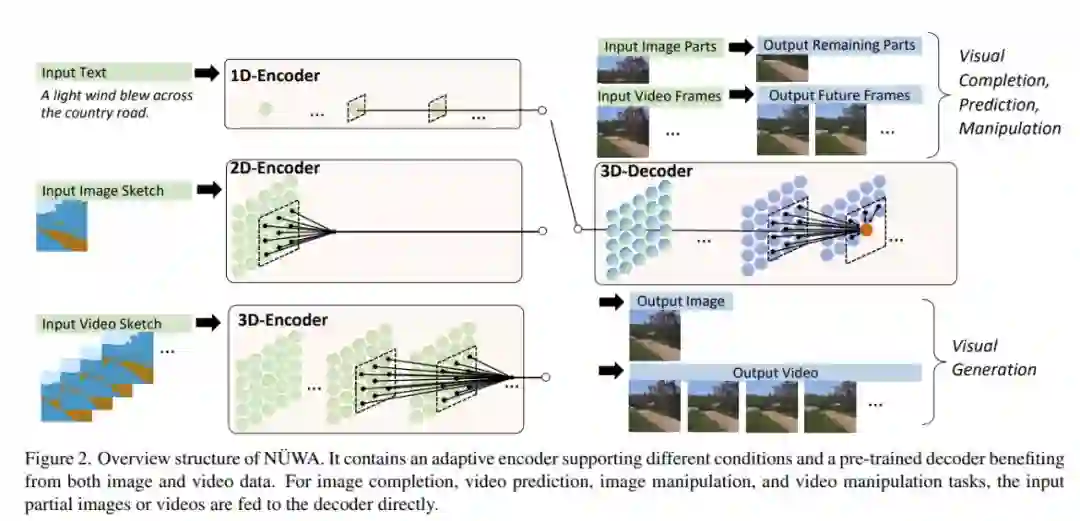
该研究提出了一个通用的 3D transformer——编码器 - 解码器框架(如下图所示),同时涵盖了语言、图像和视频,可用于多种视觉合成任务。该框架由以文本或视觉草图作为输入的自适应编码器和由 8 个视觉合成任务共享的解码器组成。
![]()
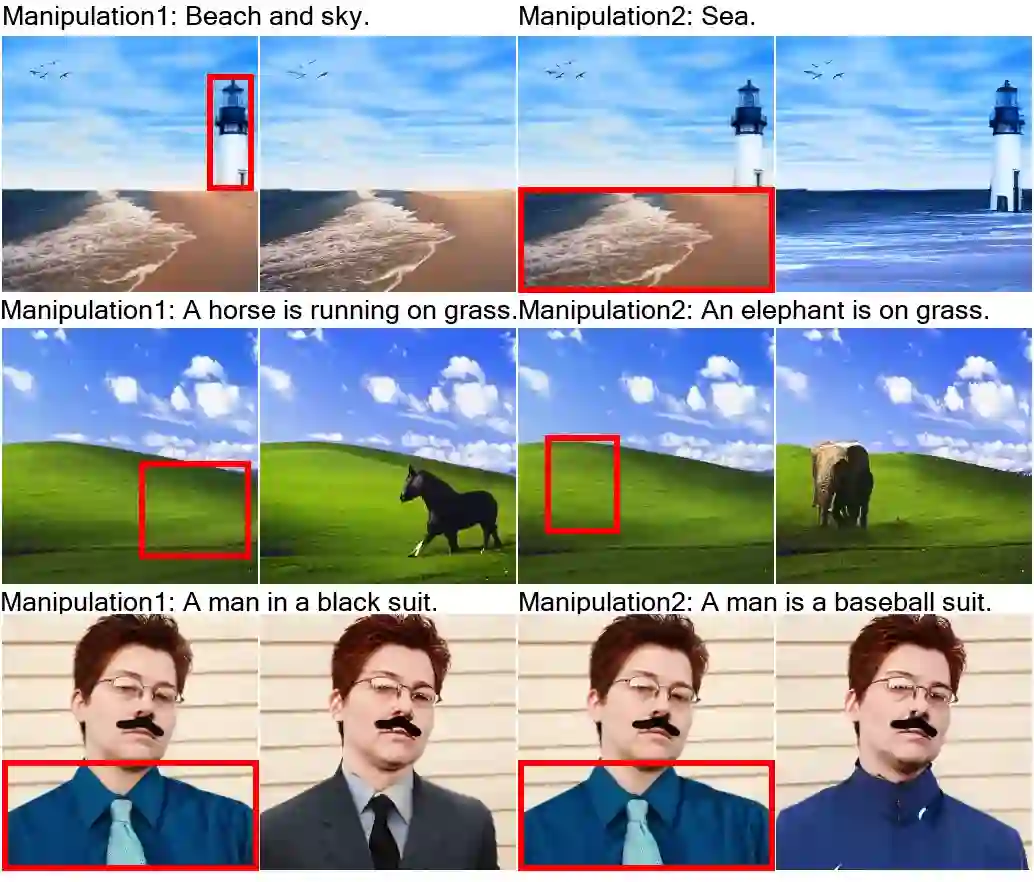
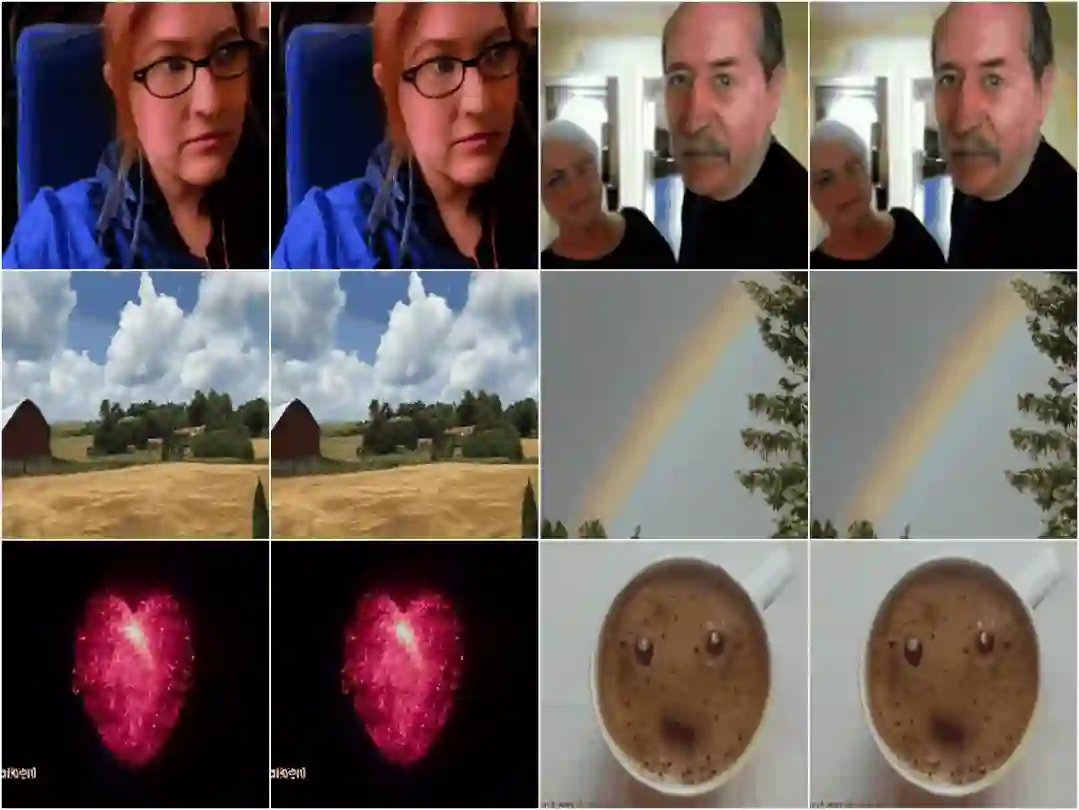
该框架还包含一种 3D Nearby Attention (3DNA) 机制,以考虑空间和时间上的局部特征。3DNA 不仅降低了计算复杂度,还提高了生成结果的视觉质量。与几个强大的基线相比,「女娲」在文本到图像生成、文本到视频生成、视频预测等方面都得到了 SOTA 结果。此外,「女娲」还显示出惊人的零样本学习能力。
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
推荐:
文字生成图像、视频,8 类任务一个模型搞定。
论文 5:Rethinking Keypoint Representations: Modeling Keypoints and Poses as Objects for Multi-Person Human Pose Estimation
摘要:
近日,来自加拿大滑铁卢大学的研究者提出了一种全新的单阶段多人关键点和姿态检测方法 KAPAO。使用一块 TITAN Xp GPU 实时运算,720p 视频的推理速度可以达到每秒 35 帧,1080p 的视频可达到每秒 20 帧。在不使用测试时增强 (TTA) 时,KAPAO 比此前的单阶段方法(如 DEKR 和 HigherHRNet)更快、更准确。
![]()
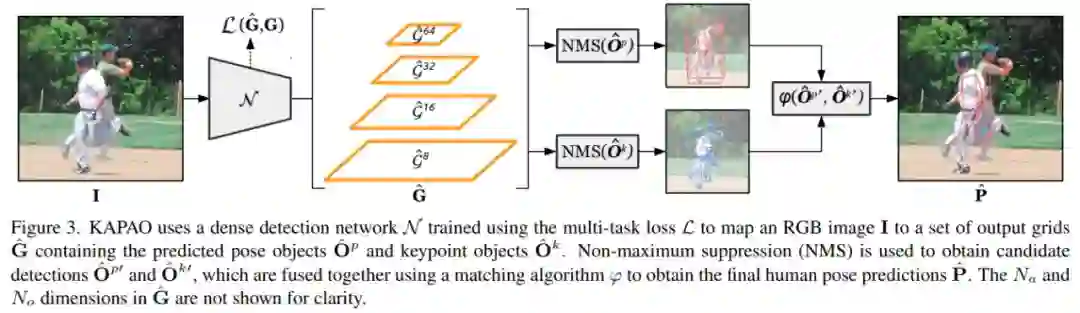
在滑铁卢大学的这项研究中,研究者提出了一种新的无热图关键点检测方法 KAPAO(Keypoints And Poses As Objects),并将其应用于单阶段多人人体姿态估计。其中单个关键点和空间相关的关键点(即姿态)集被建模为基于 anchor 的密集检测框架中的目标。这种把关键点和姿态视为目标的 KAPAO 方法可以同时检测关键点目标和姿态目标,并使用简单的匹配算法融合结果。通过检测姿态目标,该研究统一了人体检测和关键点估计,从而形成了一种高效的单阶段多人人体姿态估计方法。
KAPAO 方法以 YOLO(You Only Look Once)密集检测框架近期的一种实现为基础,并包含一个高效的网络设计。此外,由于 KAPAO 不会产生大型且昂贵的热图,因此在准确性和推理速度方面,优于此前的单阶段方法,特别是在不使用 TTA 的情况下。
![]()
推荐:
抛弃热图回归,滑铁卢大学提出多人姿态估计新方法。
论文 6:AI in Games: Techniques, Challenges and Opportunities
摘要:
近年来,我们见证了游戏 AI 的快速发展,从 Atari、AlphaGo、Libratus、OpenAI Five 到 AlphaStar 。这些 AI 通过结合现代技术在某些游戏中击败了职业人类玩家,标志着决策智能领域前进了一大步。
AlphaStar 和 OpenAI Five 分别在星际争霸和 Dota2 中达到了专业玩家水平。现在看来,目前的技术可以处理非常复杂的不完美信息游戏,特别是最近大火的王者荣耀等游戏中的突破,都遵循了类似 AlphaStar 和 OpenAI Five 的框架。我们不禁会问:人机游戏 AI 的未来趋势或挑战是什么?来自中国科学院自动化研究所以及中国科学院大学的研究者撰文回顾了最近典型的人机游戏 AI,并试图通过对当前技术的深入分析来回答这些问题。
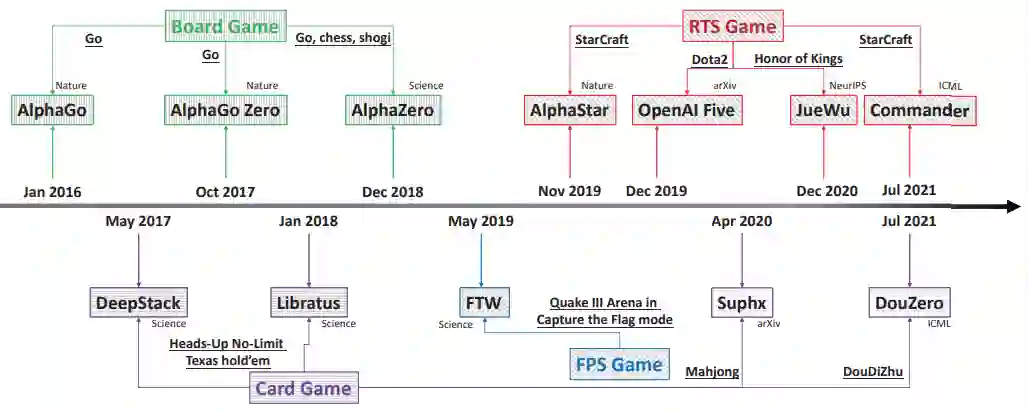
具体而言,该研究调查了四种典型的游戏类型,即围棋棋盘游戏;纸牌游戏(HUNL 德州扑克、斗地主和麻将);第一人称射击 (FPS) 游戏(雷神之锤 III);实时战略游戏 (RTS)(星际争霸、Dota2 和王者荣耀) 。上述游戏对应的 AI 包括 AlphaGo、AlphaGo Zero 、AlphaZero、Libratus、DeepStack、DouZero、Suphx、FTW、AlphaStar、OpenAI Five、JueWu 和 Commander。图 1 为一个简短的概要。
![]()
论文 7:Wireless information transfer with fast neutrons
摘要:
近日,来自英国兰开斯特大学的工程师与斯洛文尼亚的 Jožef Stefan 研究所合作,使用核辐射代替传统技术进行了无线传输,用「快中子」传输数字编码信息。
该研究测量了来自锎 - 252 的快中子的自发发射,锎 - 252 是一种在核反应堆中产生的放射性同位素。
经过调制的辐射使用探测器测量并在笔记本电脑上进行记录。传输的数据包括单词、字母表和随机数,这些数据被串行编码到中子场的调制中,输出在笔记本电脑上解码,在屏幕上恢复编码信息。研究者进行了一项双盲测试,对来自随机数生成器的数字进行编码,然后进行传输和解码。所有的传输测试都被证明是 100% 成功的。
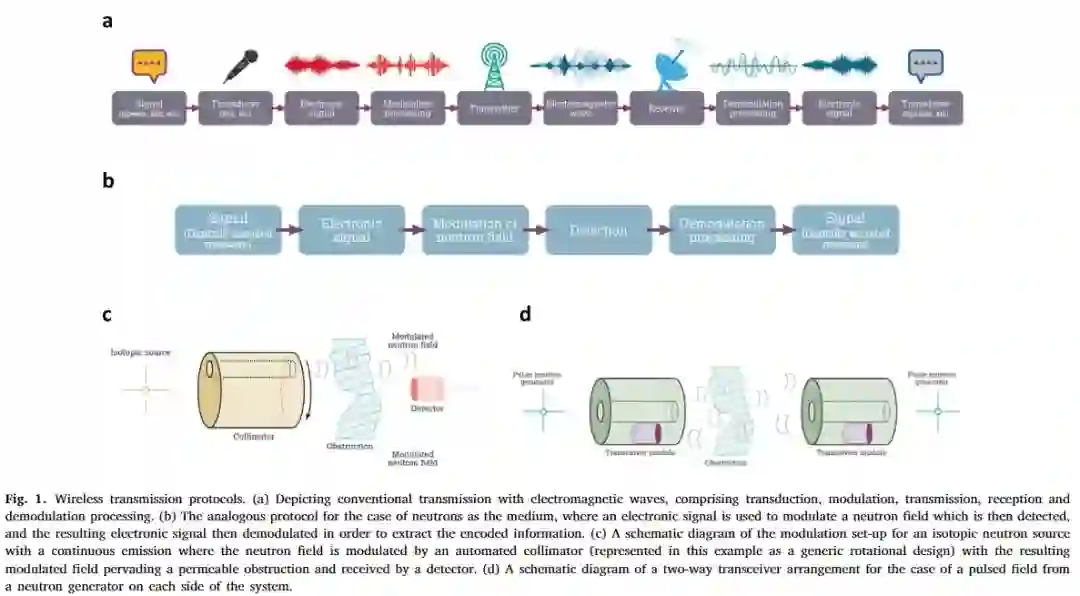
下图 1(a) 中描绘的传统信息传输流的电磁域转换过程类似,其中用到了调制快中子场,并通过解码的时间序列变化检测到信号,进而恢复信号(如图 1(b)所示)。由于中子不带电,在电磁基础上不能直接实现调制,因此要么使用动态准直器(dynamic collimator)阻挡中子场(如图 1(c) 所示),要么借助脉冲加速器源(如图 1(d) 所示)。
![]()
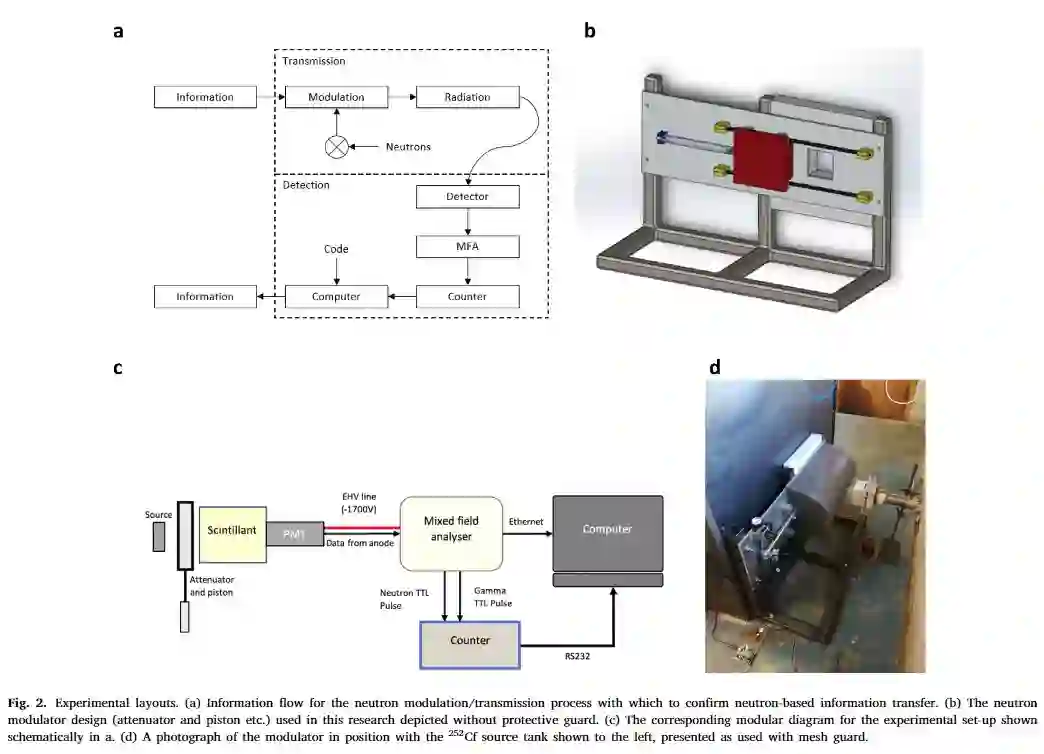
下图 2(a) 描述了该研究信息传输和检测域的基本框架。编码阶段由专门设计和制造的中子斩波器(图 2b)执行,该中子斩波器包括聚乙烯块,该块被移动到与编码信号的要求相对应的位置;图 2(c) 展示了更多系统细节,包含源、调制器、闪烁探测器和光电倍增管 (PMT)、嵌入 PSD 的混合场分析器,其中调制器如图 2(d)所示。
![]()
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
本周 10 篇 NLP 精选论文是:
1. Combining Data-driven Supervision with Human-in-the-loop Feedback for Entity Resolution. (from Jia Li, Michael Jones)
2. Small Changes Make Big Differences: Improving Multi-turn Response Selection \\in Dialogue Systems via Fine-Grained Contrastive Learning. (from Yan Zhang)
3. Triple Classification for Scholarly Knowledge Graph Completion. (from Sören Auer)
4. The ComMA Dataset V0.2: Annotating Aggression and Bias in Multilingual Social Media Discourse. (from Siddharth Singh)
5. Toxicity Detection can be Sensitive to the Conversational Context. (from Ion Androutsopoulos)
6. Knowledge Based Multilingual Language Model. (from Xin Li)
7. ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning. (from Donald Metzler)
8. TraVLR: Now You See It, Now You Don't! Evaluating Cross-Modal Transfer of Visio-Linguistic Reasoning. (from Min-Yen Kan)
9. Evaluating the application of NLP tools in mainstream participatory budgeting processes in Scotland. (from Yulan He)
10. SLUE: New Benchmark Tasks for Spoken Language Understanding Evaluation on Natural Speech. (from Karen Livescu)
本周 10 篇 CV 精选论文是:
1. XnODR and XnIDR: Two Accurate and Fast Fully Connected Layers For Convolutional Neural Networks. (from Jian Sun)
2. Factorisation-based Image Labelling. (from John Ashburner)
3. Arbitrary Virtual Try-On Network: Characteristics Preservation and Trade-off between Body and Clothing. (from Shuicheng Yan)
4. Dense Uncertainty Estimation via an Ensemble-based Conditional Latent Variable Model. (from Richard Hartley)
5. Correcting Face Distortion in Wide-Angle Videos. (from Ming-Hsuan Yang)
6. Hierarchical Modular Network for Video Captioning. (from Qingming Huang, Ming-Hsuan Yang)
7. Multi-label Iterated Learning for Image Classification with Label Ambiguity. (from Aaron Courville)
8. Toward Compact Parameter Representations for Architecture-Agnostic Neural Network Compression. (from Matei Zaharia)
9. RegionCL: Can Simple Region Swapping Contribute to Contrastive Learning?. (from Dacheng Tao)
10. MidNet: An Anchor-and-Angle-Free Detector for Oriented Ship Detection in Aerial Images. (from Licheng Jiao)
本周 10 篇 ML 精选论文是:
1. Adaptively Calibrated Critic Estimates for Deep Reinforcement Learning. (from Wolfram Burgard)
2. Defeating Catastrophic Forgetting via Enhanced Orthogonal Weights Modification. (from Bing Liu)
3. Multiset-Equivariant Set Prediction with Approximate Implicit Differentiation. (from Yan Zhang, Cees G. M. Snoek)
4. Combined Scaling for Zero-shot Transfer Learning. (from Quoc V. Le)
5. Learning Symbolic Rules for Reasoning in Quasi-Natural Language. (from Jia Deng)
6. Episodic Multi-agent Reinforcement Learning with Curiosity-Driven Exploration. (from Yang Gao)
7. Towards Graph Self-Supervised Learning with Contrastive Adjusted Zooming. (from Ming Li)
8. An Expectation-Maximization Perspective on Federated Learning. (from Max Welling)
9. Calibrated Diffusion Tensor Estimation. (from Simon K. Warfield)
10. End-to-end Learning for Fair Ranking Systems. (from Pascal Van Hentenryck)
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com