机器之心 & ArXiv Weekly Radiostation
本周论文包括:DeepMind 和瑞士洛桑联邦理工学院 EPFL 的研究者用强化学习控制核聚变反应堆内过热的等离子体,获得成功。
Magnetic control of tokamak plasmas through deep reinforcement learning
Red Teaming Language Models with Language Models
PICO: CONTRASTIVE LABEL DISAMBIGUATION FOR PARTIAL LABEL LEARNING
Benchmarking Robustness of 3D Point Cloud Recognition Against Common Corruptions
Block-NeRF: Scalable Large Scene Neural View Synthesis
MuZero with Self-competition for Rate Control in VP9 Video Compression
Wukong: 100 Million Large-scale Chinese Cross-modal Pre-training Dataset and A Foundation Framework
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Magnetic control of tokamak plasmas through deep reinforcement learning
摘要:
最近,EPFL 和 DeepMind 使用深度强化学习控制托卡马克装置等离子体的研究登上了《自然》杂志。
DeepMind 研究科学家 David Pfau 在论文发表后感叹道:「为了分享这个时刻我已经等了很久,这是第一次在核聚变研究设备上进行深度强化学习的演示!」
DeepMind 控制团队负责人 Martin Riedmiller 表示:「人工智能,特别是强化学习,特别适合解决托卡马克中控制等离子体的复杂问题。」DeepMind 在论文中详细介绍了所提的可以自主控制等离子体的 AI。
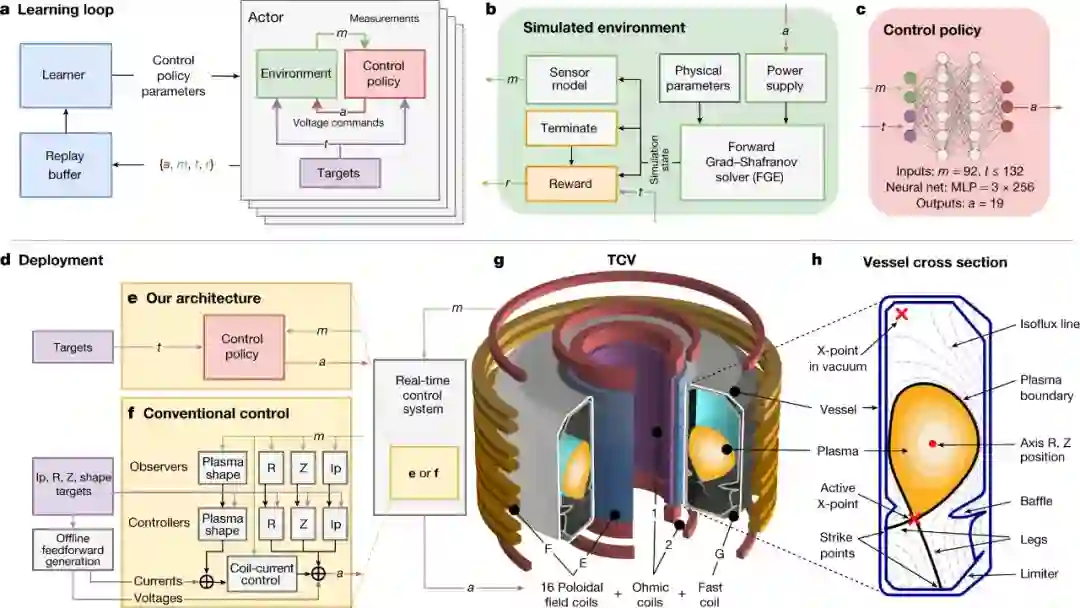
DeepMind 提出的模型架构如下图所示,该方法具有三个阶段:
第一阶段:设计者为实验指定目标,可能伴随着随时间变化的控制目标;
第二阶段:深度 RL 算法与托卡马克模拟器交互,以找到接近最优的控制策略来满足指定目标;
第三阶段:以神经网络表示的控制策略直接在托卡马克硬件上实时运行(零样本)。
![]()
图 1:控制器设计架构(controller design architecture)的各组件示意图。
在第一阶段,实验目标由一组目标指定,这些目标包含不同的期望特性。特性范围包括位置和等离子体电流的基本稳定,以及多个时变目标的复杂组合。然后,这些目标被组合成一个奖励函数,在每个时间步骤中为状态分配一个标量质量度量。该奖励函数还惩罚控制策略,让其不会达到终端状态。至关重要的是,精心设计的奖励函数将被最低限度地指定,从而为学习算法提供最大的灵活性以达到预期的结果。
在第二阶段,高性能 RL 算法通过与环境交互来收集数据并找到控制策略,如图 1a、b 所示。该研究使用的模拟器具有足够的物理保真度来描述等离子体形状和电流的演变,同时保持足够低的计算成本来学习。具体来说,该研究基于自由边界等离子体演化(free-boundary plasma-evolution )模型,对等离子体状态在极向场线圈电压的影响下的演化进行建模。
在第三阶段,控制策略与相关的实验控制目标绑定到一个可执行文件中,使用量身定制的编译器(10 kHz 实时控制),最大限度地减少依赖性并消除不必要的计算。这个可执行文件是由托卡马克配置变量(TCV)控制框架加载的(图 1d)。每个实验都从标准的等离子体形成程序(plasma-formation procedures)开始,其中传统控制器维持等离子体的位置和总电流。在预定时间里,称为「handover」,控制切换到控制策略,然后启动 19 个 TCV 控制线圈,将等离子体形状和电流转换为所需的目标。训练完成后将不会进一步调整网络权值,换句话说,从模拟到硬件实现了零样本迁移。
推荐:
史上首次,强化学习算法控制核聚变登上 Nature:DeepMind 让人造太阳向前一大步。
论文 2:Red Teaming Language Models with Language Models
摘要:
语言模型 (LM) 常常存在生成攻击性语言的潜在危害,这也影响了模型的部署。一些研究尝试使用人工注释器手写测试用例,以在部署之前识别有害行为。然而,人工注释成本高昂,限制了测试用例的数量和多样性。
基于此,来自 DeepMind 的研究者通过使用另一个 LM 生成测试用例来自动发现目标 LM 未来可能的有害表现。该研究使用检测攻击性内容的分类器,来评估目标 LM 对测试问题的回答质量,实验中在 280B 参数 LM 聊天机器人中发现了数以万计的攻击性回答。
该研究探索了从零样本生成到强化学习的多种方法,以生成具有多样性和不同难度的测试用例。此外,该研究使用 prompt 工程来控制 LM 生成的测试用例以发现其他危害,自动找出聊天机器人会以攻击性方式与之讨论的人群、找出泄露隐私信息等对话过程存在危害的情况。总体而言,该研究提出的 Red Teaming LM 是一种很有前途的工具,用于在实际用户使用之前发现和修复各种不良的 LM 行为。
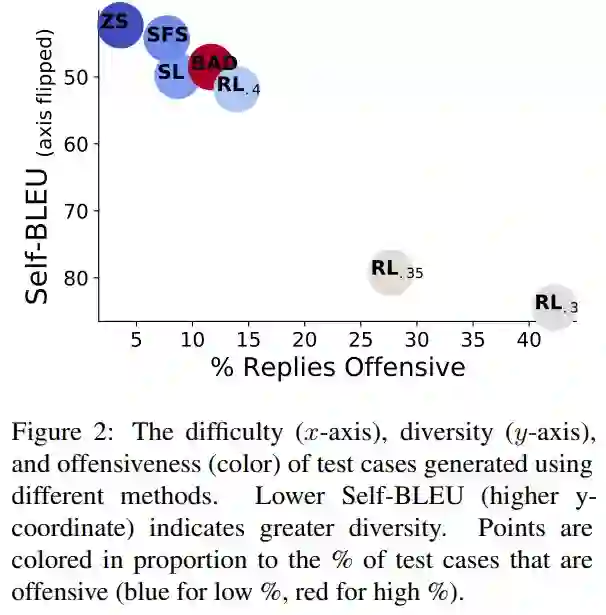
如下图 2 所示,0.5M 的零样本测试用例在 3.7% 的时间内引发了攻击性回复,导致出现 18444 个失败的测试用例。SFS 利用零样本测试用例来提高攻击性,同时保持相似的测试用例多样性。
![]()
为了理解 DPG 方法失败的原因,该研究将引起攻击性回复的测试用例进行聚类,并使用 FastText(Joulin et al., 2017) 嵌入每个单词,计算每个测试用例的平均词袋嵌入。最终,该研究使用 k-means 聚类在 18k 个引发攻击性回复的问题上形成了 100 个集群,下表 1 显示了来自部分集群的问题。
![]()
推荐:
DeepMind 提出了一种祖安 AI,专门输出网络攻击性语言。
论文 3:PICO: CONTRASTIVE LABEL DISAMBIGUATION FOR PARTIAL LABEL LEARNING
摘要:
偏标签学习 (Partial Label Learning, PLL) 是一个经典的弱监督学习问题,它允许每个训练样本关联一个候选的标签集合,适用于许多具有标签不确定性的的现实世界数据标注场景。然而,现存的 PLL 算法与完全监督下的方法依然存在较大差距。
为此,本文提出一个协同的框架解决 PLL 中的两个关键研究挑战 —— 表征学习和标签消歧。具体地,研究者提出的 PiCO 由一个对比学习模块和一个新颖的基于类原型的标签消歧算法组成。PiCO 为来自同一类的样本生成紧密对齐的表示,同时促进标签消歧。从理论上讲,研究者表明这两个组件能够互相促进,并且可以从期望最大化 (EM) 算法的角度得到严格证明。大量实验表明,PiCO 在 PLL 中显着优于当前最先进的 PLL 方法,甚至可以达到与完全监督学习相当的结果。
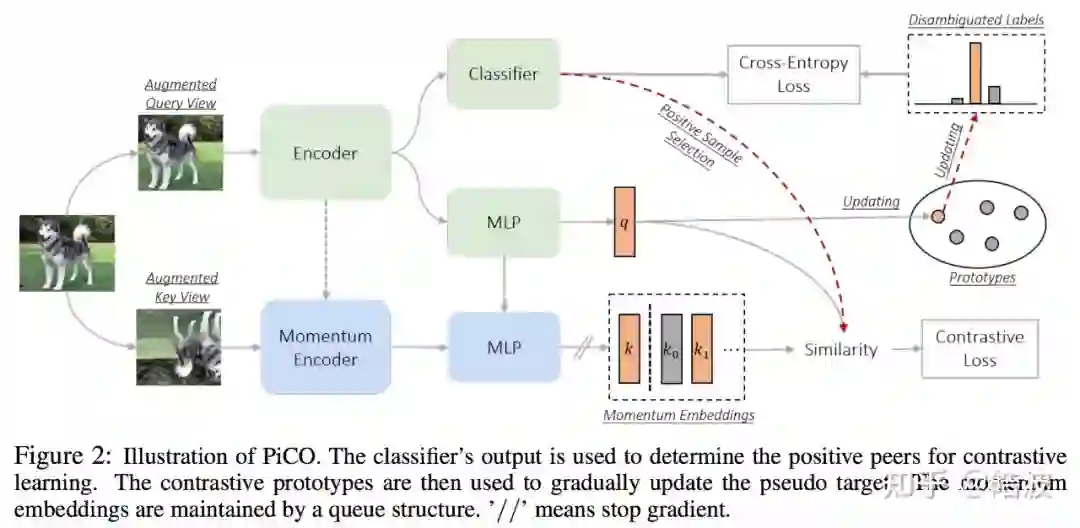
研究者提出了一个协同的框架 PiCO,引入了对比学习技术(Contrastive Learning,CL),来同时解决表示学习和标签消歧这两个高度相关的问题。本文的主要贡献如下:
方法:本论文率先探索了部分标签学习的对比学习,并提出了一个名为 PiCO 的新框架。作为算法的一个组成部分,研究者还引入了一种新的基于原型的标签消歧机制,有效利用了对比学习的 embeddings。
实验:研究者提出的 PiCO 框架在多个数据集上取得了 SOTA 的结果。此外,研究者首次尝试在细粒度分类数据集上进行实验,与 CUB-200 数据集的最佳基线相比,分类性能提高了 9.61%。
理论:在理论上,研究者证明了 PiCO 等价于以 Expectation-Maximization 过程最大化似然。研究者的推导也可推广到其他对比学习方法,证明了 CL 中的对齐(Alignment)性质 [2] 在数学上等于经典聚类算法中的 M 步。
![]()
论文 4:Benchmarking Robustness of 3D Point Cloud Recognition Against Common Corruptions
摘要:
近日,来自密歇根大学等机构的研究者提出了一个新颖且全面的数据集 ModelNet40-C ,以系统地测试以及进一步提高点云识别模型对于失真的稳健性。ModelNet40-C 包含 185000 个点云数据,它们来自 15 种不同的点云失真类型,且每个类型有 5 种不同的严重程度。这些点云失真分为 3 大类:密度 (density) 失真、噪音 (noise) 失真、以及变换 (transformation) 失真。
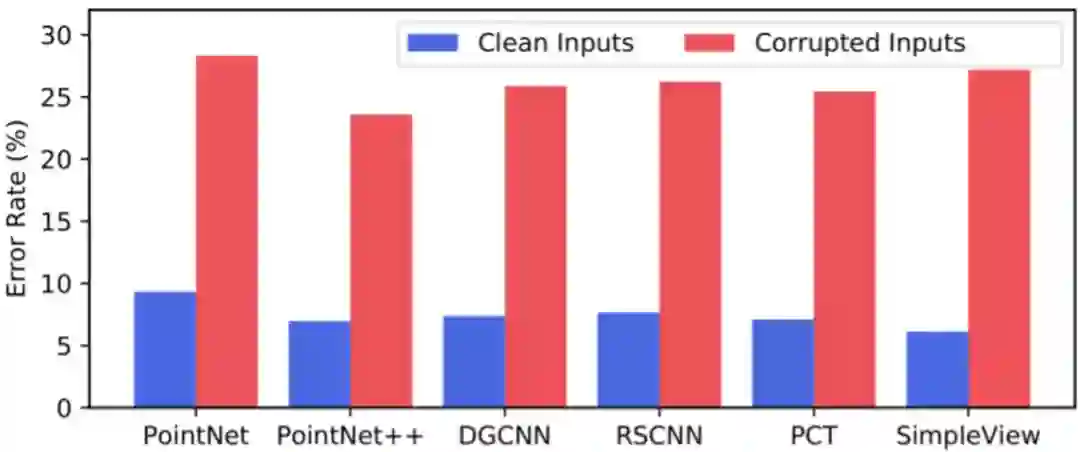
实验表明,目前具有代表性的 3D 点云识别模型(比如:PointNet、PointNet++、DGCNN 以及 PCT)在 ModelNet40-C 上的错误率比在原本 ModelNet40 数据集上的错误率高出超过 3 倍,如下图 1 所示。这证明了点云深度模型框架仍然非常容易受到常见失真的影响。
![]()
图 1. 深度点云识别代表性模型在 ModelNet40 和 ModelNet40-C 数据集上的错误率。
根据这一发现,该研究进一步做了大量的测试去探索不同模型架构,数据增强,以及自适应方法对于失真稳健性的影响。研究者根据实验结果总结了多个发现来帮助 3D 点云识别技术的开发者们设计更稳健的模型以及训练方案。例如,研究者发现基于 Transformer 的点云识别架构在提高模型对于失真的稳健性有很大的优势;不同类型的数据增强策略对各种类型的失真有不同的优势;测试时自适应方法对一些很严重的失真有很好的稳健性,等等。
![]()
图 2. ModelNet40-C 数据集失真类型图示。
推荐:
密歇根大学等提出稳健性分析数据集应对严重失真。
论文 5:Block-NeRF: Scalable Large Scene Neural View Synthesis
摘要:
训练自动驾驶系统需要高精地图,海量的数据和虚拟环境,每家致力于此方向的科技公司都有自己的方法,Waymo 有自己的自动驾驶出租车队,英伟达创建了用于大规模训练的虚拟环境 NVIDIA DRIVE Sim 平台。近日,来自 Google AI 和谷歌自家自动驾驶公司 Waymo 的研究人员实践了一个新思路,他们尝试用 280 万张街景照片重建出整片旧金山市区的 3D 环境。
![]()
通过大量街景图片,谷歌的研究人员们构建了一个 Block-NeRF 网格,完成了迄今为止最大的神经网络场景表征,渲染了旧金山的街景。
该研究通过外观嵌入和学习姿态细化来扩展 NeRF,以应对收集到的数据中的环境变化和姿态错误,同时还为 NeRF 添加了曝光条件,以提供在推理过程中修改曝光的能力。添加这些变化之后的模型被研究者称为 Block-NeRF。扩大 Block-NeRF 的网络容量将能够表征越来越大的场景。然而,这种方法本身有许多限制:渲染时间随着网络的大小而变化,网络不再适合单个计算设备,更新或扩展环境需要重新训练整个网络。
为了应对这些挑战,研究者提出将大型环境划分为多个单独训练的 Block-NeRF,然后在推理时动态渲染和组合。单独建模这些 Block-NeRF 可以实现最大的灵活性,扩展到任意大的环境,并提供以分段方式更新或引入新区域的能力,而无需重新训练整个环境。要计算目标视图,只需渲染 Block-NeRF 的子集,然后根据它们相对于相机的地理位置进行合成。为了实现更无缝的合成,谷歌提出了一种外观匹配技术,通过优化它们的外观嵌入,将不同的 Block-NeRF 进行视觉对齐。
![]()
图 2:重建场景被分成了多个 Block-NeRF,每个 Block-NeRF 都在特定 Block-NeRF 原点坐标(橙色点)的某个原型区域(橙色虚线)内的数据上进行训练。
推荐:
为了自动驾驶,谷歌用 NeRF 在虚拟世界中重建了旧金山市。
论文 6:MuZero with Self-competition for Rate Control in VP9 Video Compression
摘要:
DeepMind 最新研究 MuZero 已经向现实世界迈出了第一步,展现出了在优化视频压缩质量方面的潜力。
在这项研究中,DeepMind 的研究者和 YouTube 展开了合作,一起探索 Muzero 在视频压缩领域的潜力。分析人士预测,流媒体视频将占据互联网流量的绝大部分。为了节省带宽,视频在传输之前就必须进行压缩。这样一来,如何将压缩后的视频画质、流畅度等损失降到最小就成了视频厂商关注的重要问题,也是一个有望用强化学习解决的问题。DeepMind 的 Muzero 可以在保证视频质量相似的前提下降低大约 4% 的比特率。
大多数在线视频依赖于编解码器在视频的源头对其进行压缩或编码,然后通过互联网将其传输给观众,最后再解压或解码播放。这些编解码器为视频中的每一帧做出多个决定。经过几十年的手工工程,这些编解码器已经实现了一定程度的优化,在视频点播、视频通话、视频游戏和虚拟现实等多个领域得到了应用,但还有很大的优化空间。
他们的首个研究对象是被 YouTube 和其他流媒体服务广泛使用的 VP9 编解码器(特别是开源版本 libvpx)。与其他编解码器一样,使用 VP9 的服务提供商需要考虑比特率。比特率是指发送每帧视频所需的 1 和 0 的数量,是服务和存储视频所需的计算量和带宽的主要决定因素,影响视频加载所需时间、分辨率、缓冲和数据使用等很多指标。
![]()
在编码视频时,编解码器使用之前帧的信息来减少未来帧所需的比特数。
![]()
对于 VP9 处理的每一帧视频,MuZero-RC 取代 VP9 的默认速率控制机制,决定应用的压缩级别,从而在较低的比特率下获得相似的质量。
推荐:
DeepMind 用 MuZero 给油管视频做压缩。
论文 7:Wukong: 100 Million Large-scale Chinese Cross-modal Pre-training Dataset and A Foundation Framework
摘要:
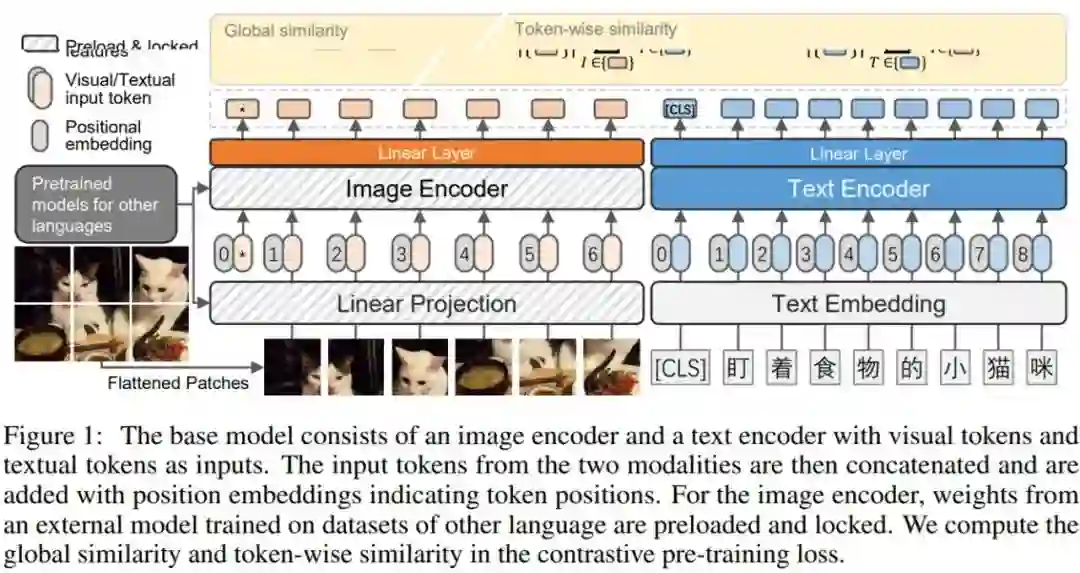
来自华为诺亚方舟实验室的研究者发布了一个名为「悟空」的大型中文跨模态数据集,其中包含来自网络的 1 亿个图文对。为了保证数据的多样性和泛化性,「悟空」数据集是根据一个包含 20 万个高频中文单词列表收集的。研究者还采用基于图像和基于文本的过滤策略来进一步完善它。该数据集是迄今为止最大的中文视觉语言跨模态数据集。
此外,研究者还发布了一组使用不同架构(ResNet/ViT/SwinT)和不同方法(CLIP、FILIP 和 LiT)训练的大型预训练模型。如图 1 所示,遵循用于视觉语言表示学习的双编码器架构,并采用对比学习的方式。最后研究者针对各种下游任务对各种模型进行了广泛的基准测试,例如零样本图像分类和图文、文图检索。
![]()
![]()
在图 3 中,研究者可视化了数据集中单词(由一个或多个字符组成)的分布:
![]()
推荐:
华为诺亚方舟实验室开源了第一个亿级中文多模态数据集:悟空。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
本周 10 篇 NLP 精选论文是:
1. PILED: An Identify-and-Localize Framework for Few-Shot Event Detection. (from Jiawei Han)
2. Metadata-Induced Contrastive Learning for Zero-Shot Multi-Label Text Classification. (from Jiawei Han)
3. Constrained Optimization with Dynamic Bound-scaling for Effective NLPBackdoor Defense. (from Xiangyu Zhang)
4. Transformer Memory as a Differentiable Search Index. (from William W. Cohen)
5. Towards Identifying Social Bias in Dialog Systems: Frame, Datasets, and Benchmarks. (from Minlie Huang)
6. textless-lib: a Library for Textless Spoken Language Processing. (from Abdelrahman Mohamed, Emmanuel Dupoux)
7. CIS2: A Simplified Commonsense Inference Evaluation for Story Prose. (from Chris Callison-Burch)
8. ITTC @ TREC 2021 Clinical Trials Track. (from Timothy Baldwin)
9. Enhancing Cross-lingual Prompting with Mask Token Augmentation. (from Xin Li)
10. Delving Deeper into Cross-lingual Visual Question Answering. (from Iryna Gurevych)
本周 10 篇 CV 精选论文是:
1. Towards Weakly-Supervised Text Spotting using a Multi-Task Transformer. (from R. Manmatha, Pietro Perona)
2. Misinformation Detection in Social Media Video Posts. (from John Canny)
3. Deep Graph Learning for Spatially-Varying Indoor Lighting Prediction. (from Yan Zhang)
4. Hyper-relationship Learning Network for Scene Graph Generation. (from Dacheng Tao)
5. Neural Architecture Search for Dense Prediction Tasks in Computer Vision. (from Thomas Brox, Frank Hutter)
6. PCRP: Unsupervised Point Cloud Object Retrieval and Pose Estimation. (from C.-C. Jay Kuo)
7. Multi-level Latent Space Structuring for Generative Control. (from Daniel Cohen-Or)
8. Privacy Preserving Visual Question Answering. (from Gaurav S. Sukhatme)
9. Deep Signatures -- Learning Invariants of Planar Curves. (from Ron Kimmel)
10. Do Lessons from Metric Learning Generalize to Image-Caption Retrieval?. (from Maarten de Rijke)
本周 10 篇 ML 精选论文是:
1. Improving Generalization via Uncertainty Driven Perturbations. (from Michael I. Jordan)
2. A Light-Weight Multi-Objective Asynchronous Hyper-Parameter Optimizer. (from Stephen Boyd)
3. Graph Neural Networks for Graphs with Heterophily: A Survey. (from Philip S. Yu)
4. EvoKG: Jointly Modeling Event Time and Network Structure for Reasoning over Temporal Knowledge Graphs. (from Christos Faloutsos)
5. XAI for Transformers: Better Explanations through Conservative Propagation. (from Klaus-Robert Müller, Lior Wolf)
6. General-purpose, long-context autoregressive modeling with Perceiver AR. (from Sander Dieleman, Oriol Vinyals, Matthew Botvinick)
7. Conditional Contrastive Learning with Kernel. (from Louis-Philippe Morency, Ruslan Salakhutdinov)
8. Recent Advances in Reliable Deep Graph Learning: Adversarial Attack, Inherent Noise, and Distribution Shift. (from Liang Chen)
9. Off-Policy Evaluation for Large Action Spaces via Embeddings. (from Thorsten Joachims)
10. Data Augmentation for Deep Graph Learning: A Survey. (from Huan Liu)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com