从年初 OpenAI 刷屏社区的 DALL-E 到英伟达生成逼真摄影的 GauGAN2,文本生成图像可谓是今年大火的一个研究方向。现在 OpenAI 又有了新的进展——35 亿参数的新模型 GLIDE。
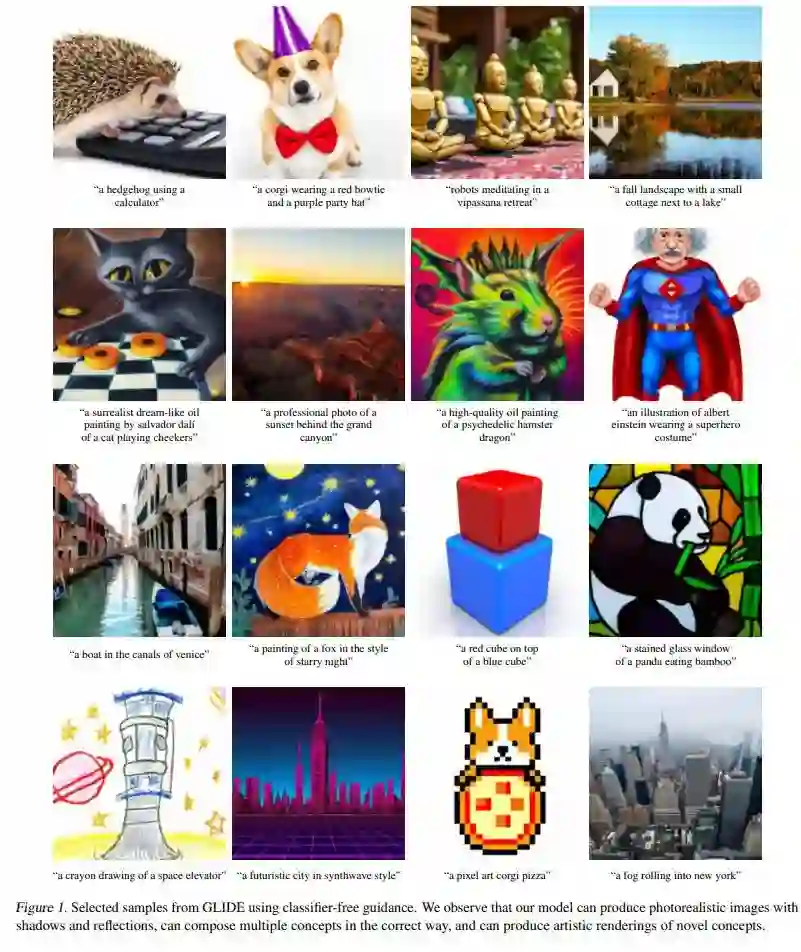
如下图 1 所示,GLIDE 通常会生成逼真的阴影和反射,以及高质量的纹理。此外,该模型还能够组合多个概念(例如柯基犬、领结和生日帽),同时将属性(例如颜色)绑定到这些对象。
![]()
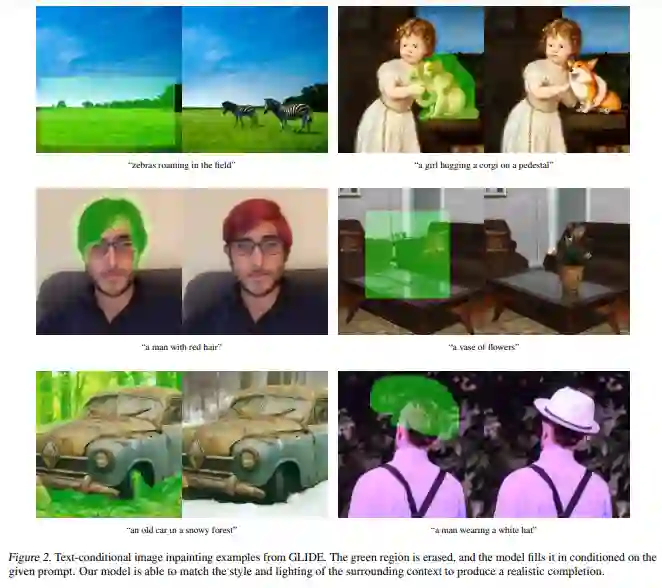
除了从文本生成图像,GLIDE 还有图像编辑功能——使用文本 prompt 修改现有图像,在必要时插入新对象、阴影和反射,如下图 2 所示。例如,在草坪上添加斑马:
![]()
如下图 3 所示,GLIDE 的零样本生成和修复复杂场景的能力也很强。
![]()
GLIDE 还能够将草图转换为逼真的图像编辑。例如下图中「一只戴着领结和生日帽的柯基犬」从涂鸦草图转换成了逼真的图像。
![]()
上述功能是怎样实现的呢?在新模型 GLIDE 中,OpenAI 将指导扩散(guided diffusion)应用于文本生成图像的问题。首先该研究训练了一个 35 亿参数的扩散模型,使用文本编码器以自然语言描述为条件,然后比较了两种指导扩散模型至文本 prompt 的方法:CLIP 指导和无分类器指导。通过人工和自动评估,该研究发现无分类器指导能够产生更高质量的图像。
![]()
该研究发现使用无分类器指导模型生成的样本既逼真又反映了广泛的现实知识。人类评估的结果表明,GLIDE 的生成结果优于 DALL-E。
此外,值得注意的是,DALL-E 的参数量是 120 亿,而 GLIDE 仅有 35 亿参数,却实现了更优的性能。我们来具体看一下 GLIDE 的模型细节。
OpenAI 以 64 × 64 的图像分辨率训练了一个具有 35 亿参数的文本条件扩散模型(text-conditional diffusion model ),以及一个具有 15 亿参数的文本条件上采样扩散模型(text-conditional upsampling diffusion model),该模型将图像分辨率提高到 256 × 256。对于 CLIP 指导(CLIP guidance),OpenAI 还训练了一个噪声感知 64 × 64 ViT-L CLIP 模型。
OpenAI 采用 Dhariwal & Nichol (2021) 提出的 ADM 模型架构,但使用文本条件信息对其进行了扩充。对于每个噪声图像 x_t 和相应的文本说明(text caption),模型对 p(xt−1|xt, caption) 进行预测。为了以文本为条件,OpenAI 首先将文本编码为 K 个 token 序列,然后将这些 token 输入到 Transformer 模型中(Vaswani 等,2017)。这个 transformer 的输出有两种用途:
OpenAI 采用与 DALL-E 完全相同的数据集训练模型,并且使用与 Dhariwal & Nichol (2021) 提出的 ImageNet 64 × 64 模型相同的模型架构,模型通道为 512 ,从而为模型的视觉部分生成大约 23 亿个参数。对于文本编码 Transformer,OpenAI 使用 24 个残差块,产生大约 12 亿个参数。
此外,OpenAI 还训练了一个具有 15 亿参数的上采样扩散模型,图像分辨率从 64 × 64 增加到 256 × 256 。该模型同样以文本为条件,但使用宽度为 1024 较小的文本编码器(而不是 2048 )。
模型初始训练完成之后,可以微调基本模型以支持无条件图像生成。训练过程与预训练完全相同,只是 20% 的文本 token 序列被替换为空序列。通过这种方式,模型保留了生成文本条件输出的能力,同时也可以无条件地生成图像。
以前的图像修复工作存在一个缺点,即模型在采样过程中无法看到整个上下文信息。为了获得更好的生成效果,OpenAI 对模型进行了微调:微调时,随机擦除训练样本一些区域,其余部分与掩码通道一起作为附加条件信息输入模型。OpenAI 对模型架构进行了修改,增加了四个额外的输入通道:第二组 RGB 通道和一个掩码通道。在微调之前,OpenAI 将这些新通道的相应输入权重初始化为零。对于上采样模型,OpenAI 提供了完整的低分辨率图像,但对于未掩码的区域提供高分辨率图像。
鉴于分类器指导和 CLIP 指导的相似性,应用 CLIP 来提高文本条件扩散模型的生成质量似乎很自然。为了更好地匹配 Dhariwal & Nichol (2021) 的分类器指导技术,OpenAI 使用图像编码器训练噪声感知 CLIP 模型,该图像编码器接收噪声图像,以 64 × 64 的分辨率训练模型。
该研究将 GLIDE 与之前的 SOTA 模型进行了定性比较,结果如下图 5 所示。GLIDE 生成了更逼真的图像,并且无需 CLIP 重排序或挑选。
![]()
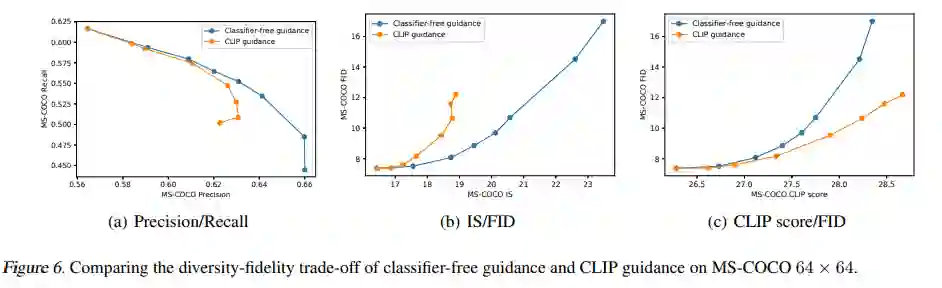
该研究首先通过查看图像质量保真度权衡的帕累托前沿来评估无分类器指导和 CLIP 指导之间的差异。下图 6 在 64 × 64 分辨率下评估了这两种方法的零样本 MS-COCO 生成。
![]()
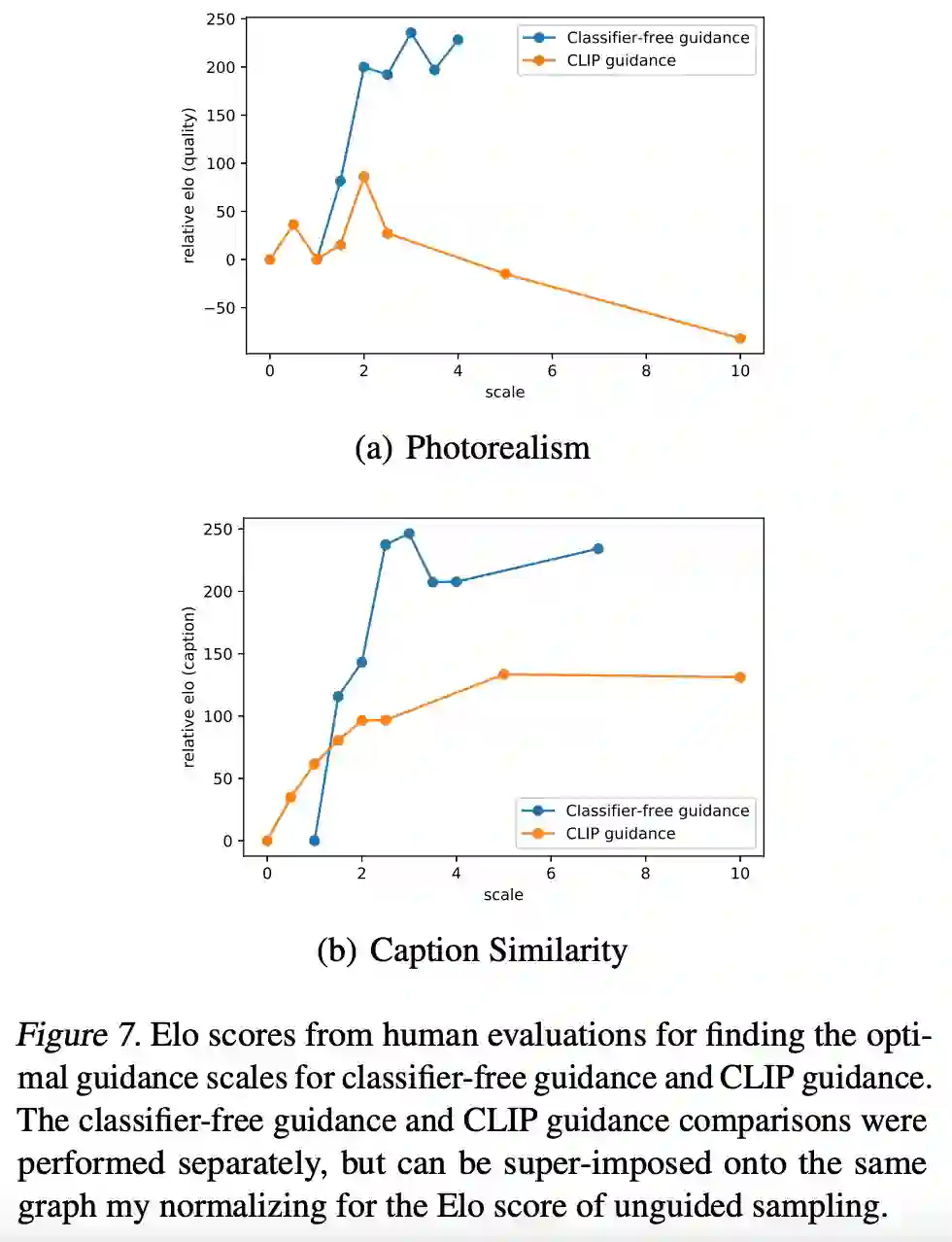
让人们观察两个 256 × 256 的图像,并按如下两条标准选出一个更优的图像:要么更好地匹配给定的标题,要么看起来更逼真。评估结果如下图 7 所示。
![]()
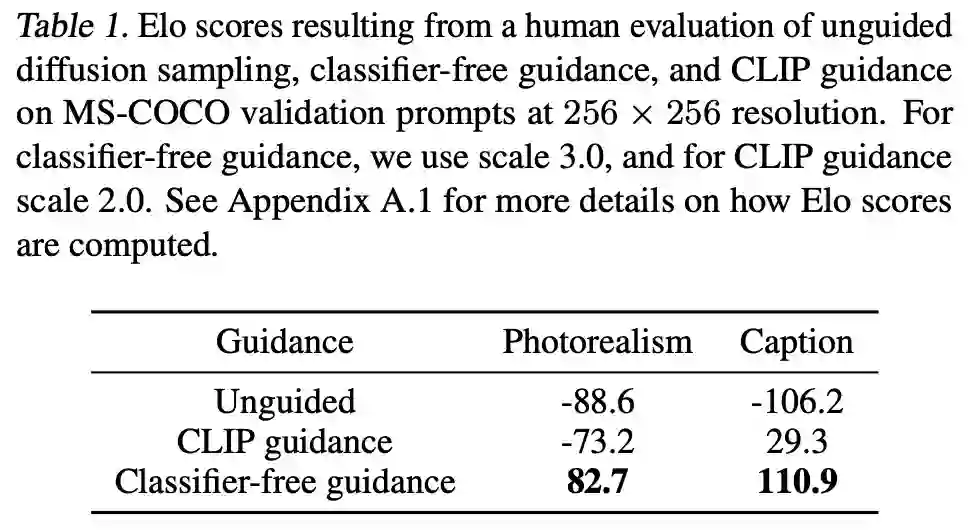
并将人类评估的结果和下表 1 的结果进行比较,然后该研究发现人类和 CLIP 指导给出的分数不一致,因此无分类器指导能够产生与人类认知一致的更高质量生成结果。
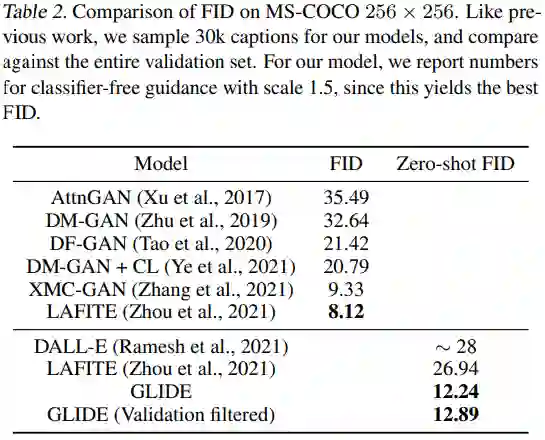
此外,研究者还将 GLIDE 与其他文本生成图像模型进行了比较,结果如下表 2 所示。GLIDE 在 MS-COCO 上获得有竞争力的 FID。
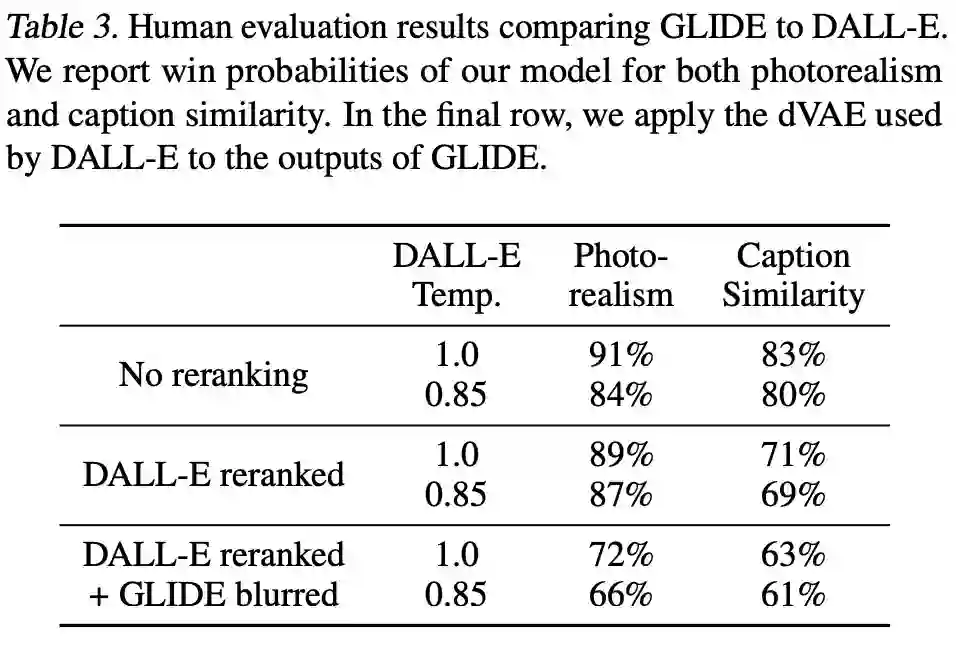
最后,该研究使用上述人类评估实验设置比较了 GLIDE 和 DALL-E ,结果如下表 3 所示。注意到 GLIDE 的训练使用与 DALL-E 大致相同的训练计算,但模型要小得多(35 亿参数 VS120 亿参数),所需采样延迟更少,并且不需要 CLIP 重排序。
![]()
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com