谷歌的下一代架构 Pathways 已经用来训练大模型了。

随着规模的增加,模型在处理多个任务时的性能逐渐提高,而且还在不断解锁新的能力。
在探讨现有 AI 模型的局限时,谷歌人工智能主管 Jeff Dean 曾经说过,今天的人工智能系统总是从头开始学习新问题。最终,我们为数千个单独的任务开发了数千个模型。以这种方式学习每项新任务不仅需要更长的时间,而且还需要更多的数据,效率非常低。
在 Jeff Dean 看来,理想的发展模式应该是训练一个模型来做成千上万件事情。为了实现这一愿景,他所在的团队去年提出了一种名叫「Pathways」的通用 AI 架构。Jeff Dean 介绍说,Pathways 旨在用一个架构同时处理多项任务,并且拥有快速学习新任务、更好地理解世界的能力。前段时间,该团队终于公布了 Pathways 的论文。
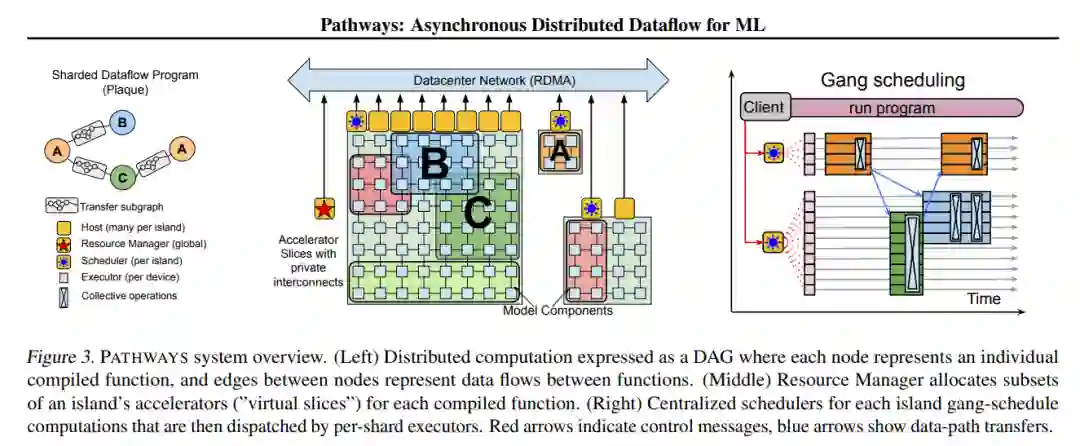
论文写道,PATHWAYS 使用了一种新的异步分布式数据流设计。这种设计允许 PATHWAYS 采用单控制器模型,从而更容易表达复杂的新并行模式。实验结果表明,当在 2048 个 TPU 上运行 SPMD(single program multiple data)计算时,PATHWAYS 的性能(加速器利用率接近 100%)可以媲美 SOTA 系统。
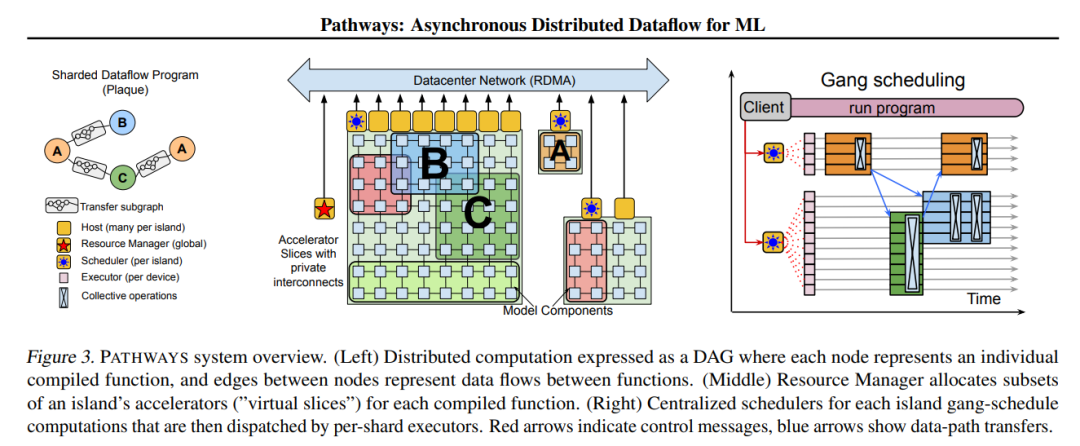
谷歌 Pathways 系统架构概览。
有了强大的系统,接下来就是训练模型了。
在刚刚公布的论文——「PaLM: Scaling Language Modeling with Pathways」中,谷歌宣布,他们用 Pathways 系统训练了一个 5400 亿参数的大型语言模型——PaLM(Pathways Language Model)。
图片
论文链接:https://storage.googleapis.com/pathways-language-model/PaLM-paper.pdf
这是一个只有解码器的密集 Transformer 模型。为了训练这个模型,谷歌动用了 6144 块 TPU,让 Pathways 在两个 Cloud TPU v4 Pods 上训练 PaLM。
强大的系统和算力投入带来了惊艳的结果。研究者在数百个语言理解和生成任务上评估了 PaLM,发现它在大多数任务上实现了 SOTA 少样本学习性能,可以出色地完成笑话解读、bug 修复、从表情符号中猜电影等语言、代码任务。