机器之心 & ArXiv Weekly Radiostation
本周论文包括 DeepMind 用 AI 复原古希腊铭文,登 Nature 封面;微软联合 OpenAI 提出超参数调优新范式,单个 GPU 上就可以调优 GPT-3 超参数。
Restoring and attributing ancient texts using deep neural networks
Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer
Rediscovering orbital mechanics with machine learning
End-to-End Referring Video Object Segmentation with Multimodal Transformers
Do We Really Need Deep Learning Models for Time Series Forecasting?
HCSC: Hierarchical Contrastive Selective Coding
Exploring Endogenous Shift for Cross-domain Detection: A Large-scale Benchmark and Perturbation Suppression Network
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Restoring and attributing ancient texts using deep neural networks
摘要:
在最新一期 Nature 封面文章中,DeepMind 联合威尼斯大学人类学系、牛津大学经典学院的研究者,探索利用机器学习来帮助历史学家更好地解释这些铭文,从而让人们更深入地了解古代历史,并释放 AI 和历史学家之间合作的潜力。
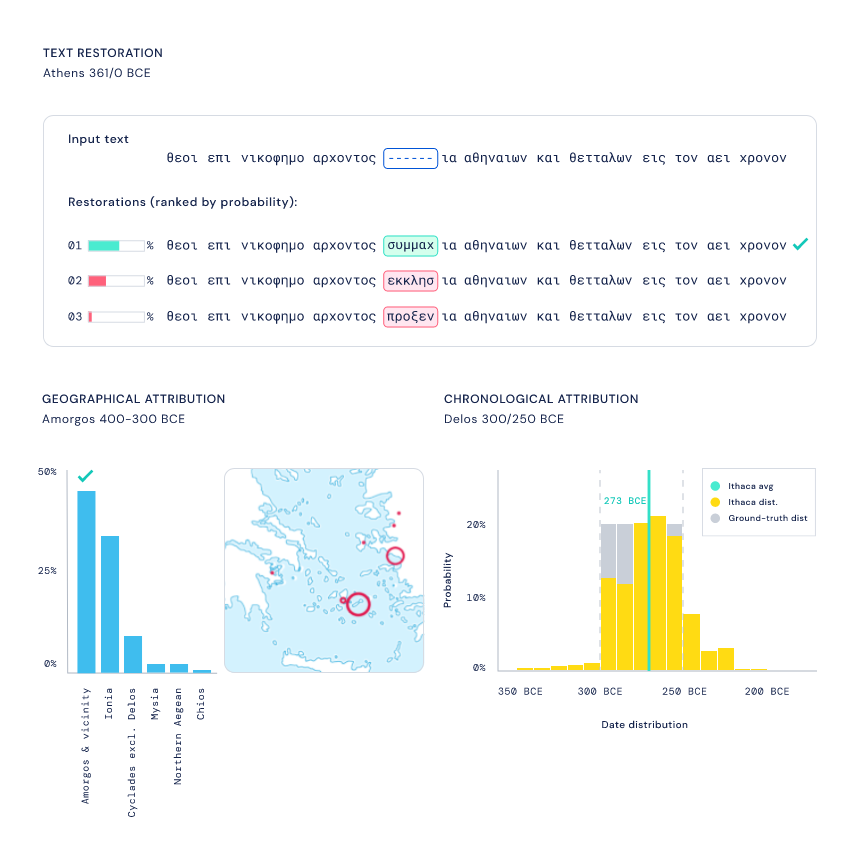
他们提出了首个可以恢复受损铭文缺失文本、识别原始位置并帮助确定创建日期的深度神经网络 —— Ithaca,它是以荷马史诗《奥德赛》中的希腊伊萨卡岛命名,在之前的 Pythia 工具上构建并进行了扩展。
研究结果表明,当单独使用时,Ithaca 在恢复受损铭文文本方面的准确率达到了 62%。相比之下,参与的历史学家的准确率为 25%,不过他们使用 Ithaca 可以将这一数字提升到 72%。
同时,Ithaca 在识别铭文原始位置方面的准确率达到了 71%,鉴定它们的年代只与真实日期范围相差不到 30 年。历史学家已经使用 Ithaca 重新评估了希腊历史上的重要时期。
此外,为了让广大研究人员、教育工作者、博物馆职员及其他人使用他们的研究成果,DeepMind 与谷歌云、谷歌艺术与文化合作推出了 Ithaca 的免费交互版本。并且,DeepMind 还开源了代码、预训练模型和交互 Colab 笔记本。
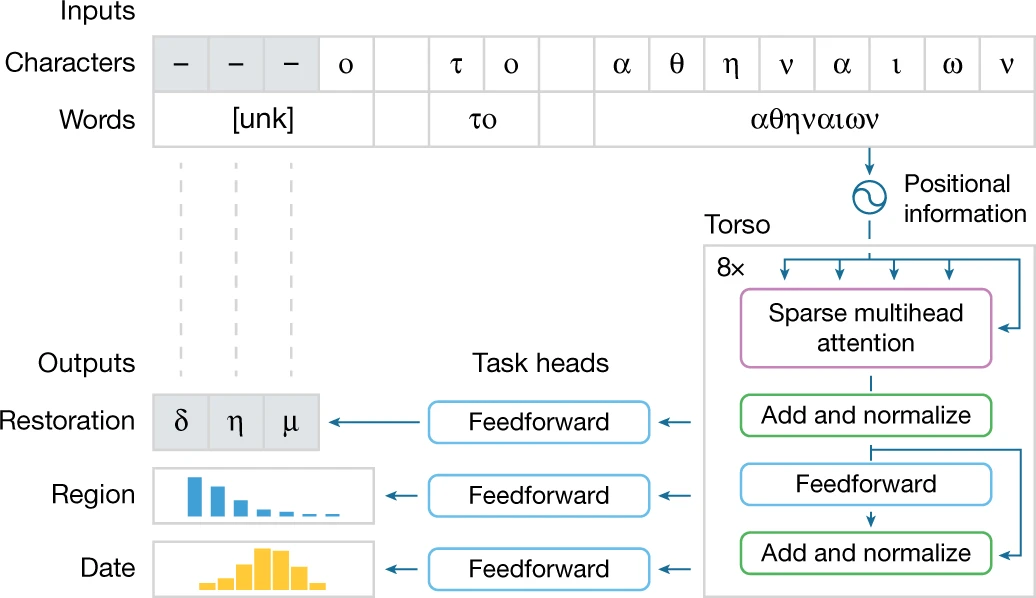
模型核心为稀疏自注意力机制,用来并行计算这两个输入(单词和单个字符)。
![]()
Ithaca 的主干由堆叠的 transformer 块组成:每个块输出一系列处理后的表示,其长度等于输入字符的数量,每个块的输出成为下一个块的输入。主干的最终输出被传递给三个不同的任务头,分别处理恢复、地理归属和时间归属。每个头都由一个浅层前馈神经网络组成,专门针对每个任务进行训练。在图 2 所示的例子中,恢复头预测了三个丢失的字符;地理归属头将铭文分为 84 个区域,并且按时间顺序的归属头将其追溯到公元前 800 年至公元 800 年之间。
![]()
推荐:
预测过去?DeepMind 用 AI 复原古希腊铭文,登 Nature 封面。
论文 2:Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer
摘要:
来自微软和 OpenAI 的研究者首次提出了基础研究如何调优大型神经网络(这些神经网络过于庞大而无法多次训练)。他们通过展示特定参数化保留不同模型大小的最佳超参数来实现这一点。利用 µP (Maximal Update Parametrization)将 HP (超参数)从小型模型迁移到大型模型。也就是说,该研究在大型模型上获得了接近最优的 HP。
具体而言,该研究证明,在 µP 中,即使模型大小发生变化,许多最优的 HP 仍保持稳定。这导致一种新的 HP 调优范式:µTransfer,即在 µP 中对目标模型进行参数化,并在较小的模型上间接调优 HP,将其零样本迁移到全尺寸模型上,无需调优后者。该研究在 Transformer 和 ResNet 上验证 µTransfer,例如,1)通过从 13M 参数的模型中迁移预训练 HP,该研究优于 BERT-large (350M 参数),总调优成本相当于一次预训练 BERT-large;2)通过从 40M 参数迁移,该研究的性能优于已公开的 6.7B GPT-3 模型,调优成本仅为总预训练成本的 7%。
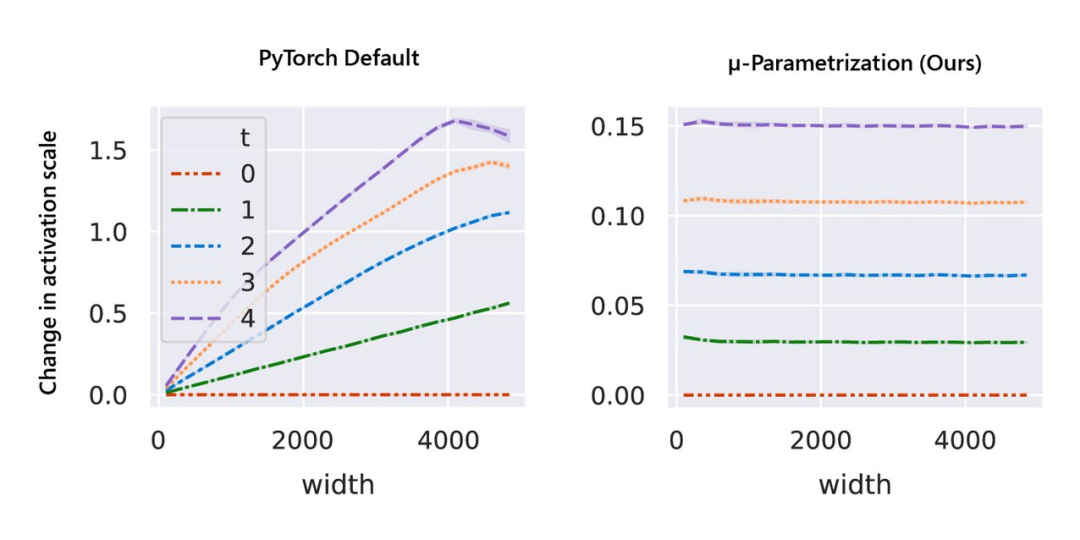
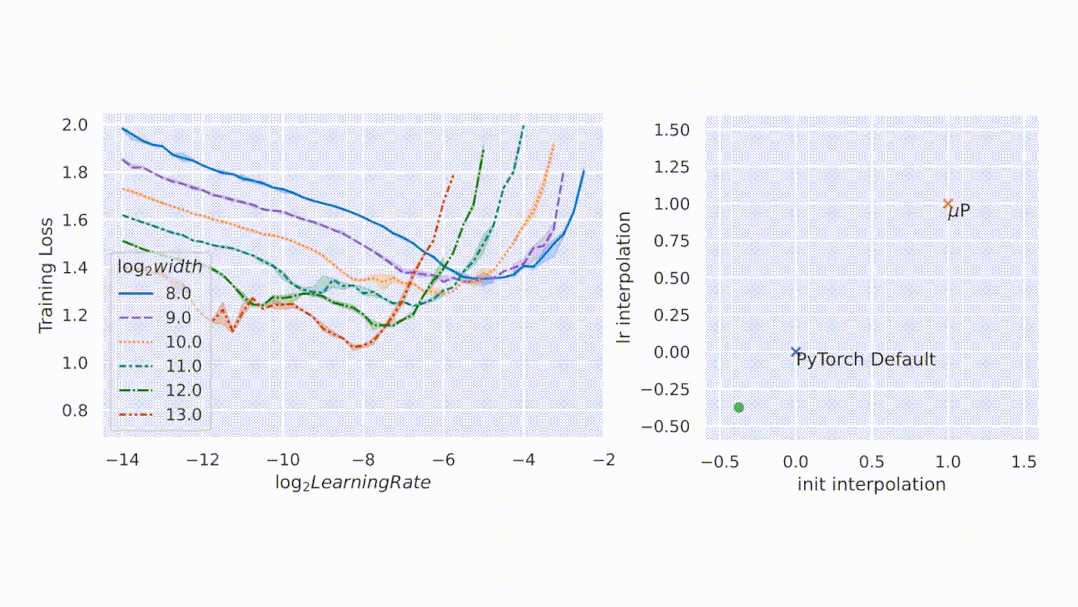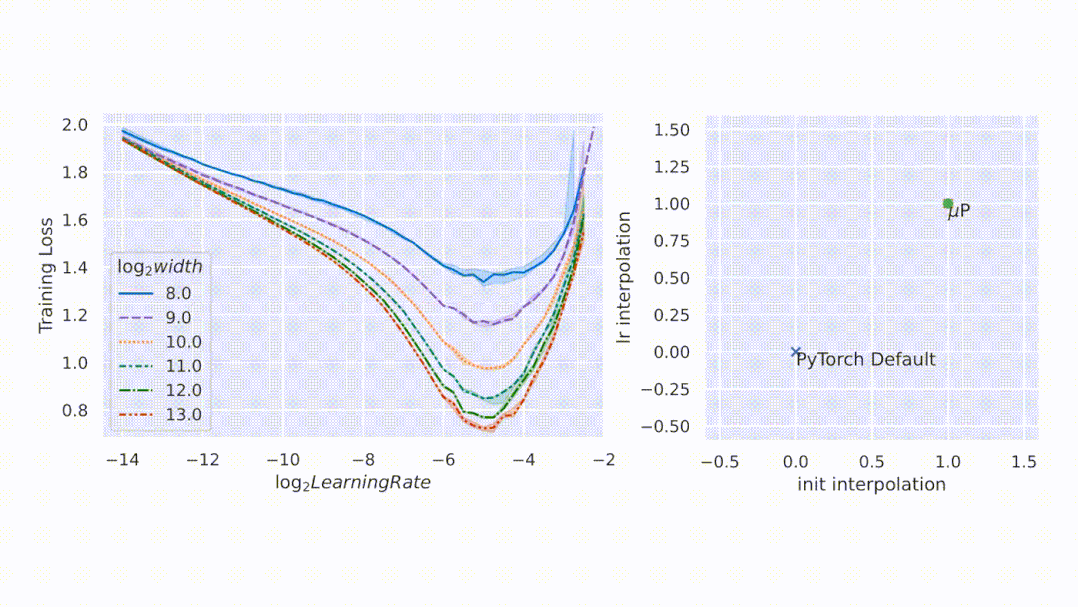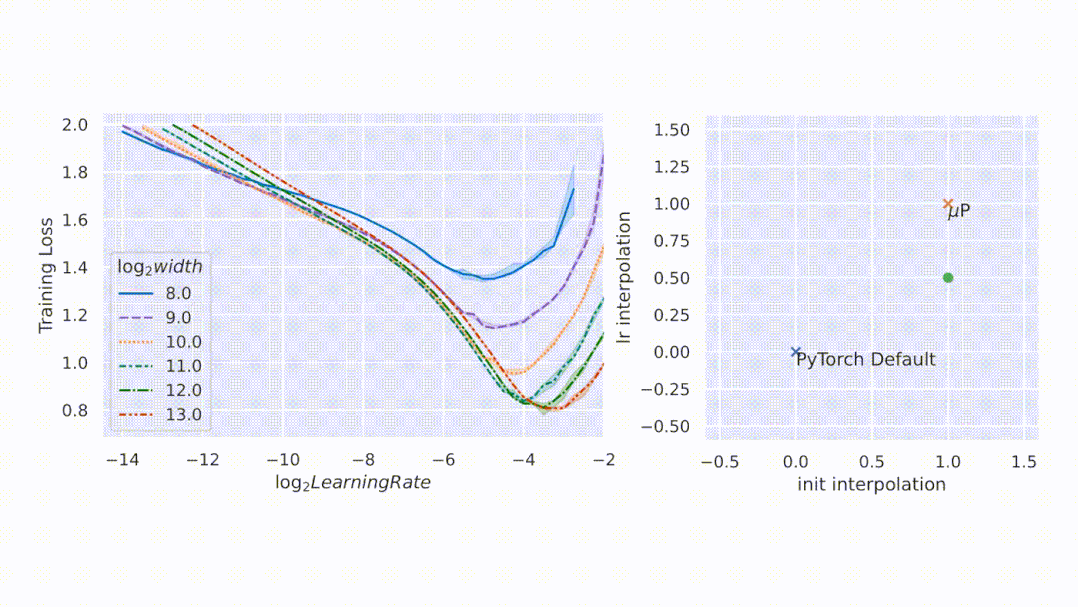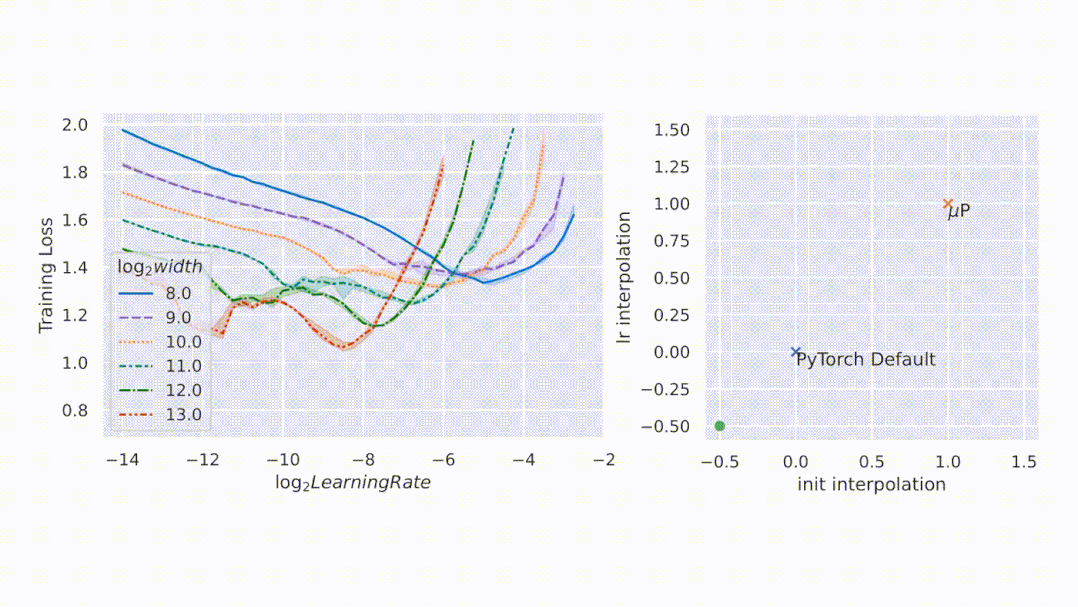
与随机初始化不同,模型训练期间的行为更难进行数学分析。该研究用 µP 解决,如图 1 右侧所示,该图显示了网络激活扩展(activation scales)在模型宽度增加的最初几个训练步骤中的稳定性。
![]()
图 1:在 PyTorch 的默认参数化中,左图,在经过一次 step 训练后,激活扩展的宽度会出现差异。但是在右图的 µP 中,无论训练 step 宽度如何,激活扩展都会发生一致的变化。
如图所示,µP 是唯一在宽度上保持最佳学习率的参数化,在宽度为 213 - 8192 的模型中实现了最佳性能,并且对于给定的学习率,更宽的模型性能更好——即曲线不相交。
![]()
基于张量程序(Tensor Programs)的理论基础,µTransfer 自动适用于高级架构,例如 Transformer 和 ResNet。此外,它还可以同时迁移各种超参数。
推荐:
微软联合 OpenAI 提出 HP 调优新范式,单个 GPU 上就可以调优 GPT-3 超参数。
论文 3:Rediscovering orbital mechanics with machine learning
摘要:
机器学习 (ML) 推动了科学的巨大进步,从粒子物理学到结构生物学再到宇宙学,机器学习能够在大型数据集中学习特征,对不同的对象进行分类,并执行参数推断,以及更具开创性的应用,例如自回归语言模型、预测蛋白质结构,以及蛋白质功能预测。机器学习强大的学习能力,我们不禁会问,机器学习能否仅仅通过观察我们的太阳系来重新发现万有引力定律?
近日来自萨塞克斯大学、伦敦大学学院等机构的研究者在论文《 Rediscovering orbital mechanics with machine learning 》中对上述问题进行的解答,他们的回答是:可以。
具体而言,该研究提出了一种采用机器学习方法,通过观察自动发现实际物理系统的控制方程和隐藏属性。研究者训练了一个图神经网络,通过 30 年的轨迹数据来模拟太阳系的太阳、行星和大型卫星的动力学。然后,他们使用符号回归来发现神经网络隐式学习的力学定律解析表达式,结果表明表达式等效于牛顿万有引力定律。
该研究分为两个阶段:第一阶段的学习模拟器基于图网络 (GN),图网络是一种深度神经网络,可以通过训练来逼近图上的复杂函数。在这里,太阳系的太阳、行星和卫星的(相对)位置和速度被表示为输入图的节点,而天体之间可能的物理交互(例如力)被表示为图的边。该研究将基于 GN 的模拟器与 30 年来观测到的太阳系轨迹进行了拟合。
在第二阶段,该研究分离边函数(edge function),并应用符号回归拟合边函数的解析公式,其最好的拟合是对牛顿万有引力定律的拟合。然后,该研究使用已发现的方程重新拟合未观察到的(相对)天体质量,并找到了与天体真实质量几乎完美的拟合。之后研究者可以使用发现的方程和重新学习的质量来模拟太阳系动力学,并获得与真实观察到的轨迹非常接近的对应关系。
![]()
推荐:
给 GNN 一堆数据,它自己发现了万有引力定律。
论文 4:End-to-End Referring Video Object Segmentation with Multimodal Transformers
摘要:
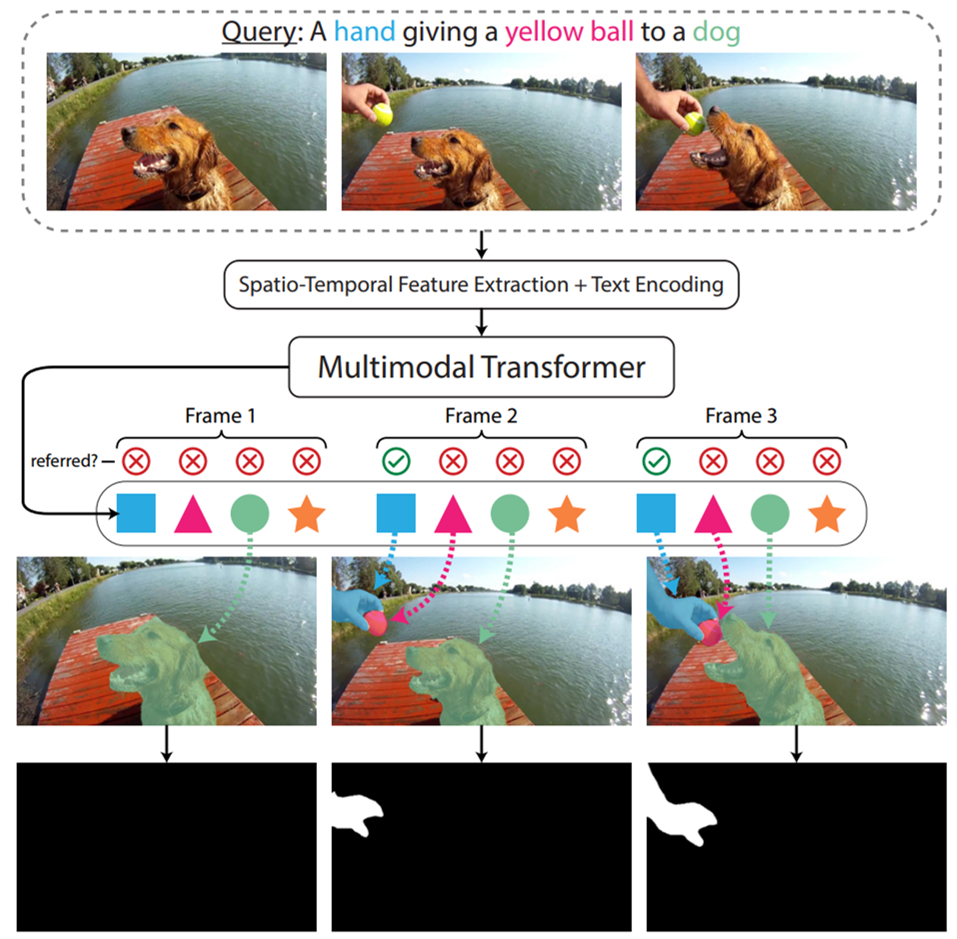
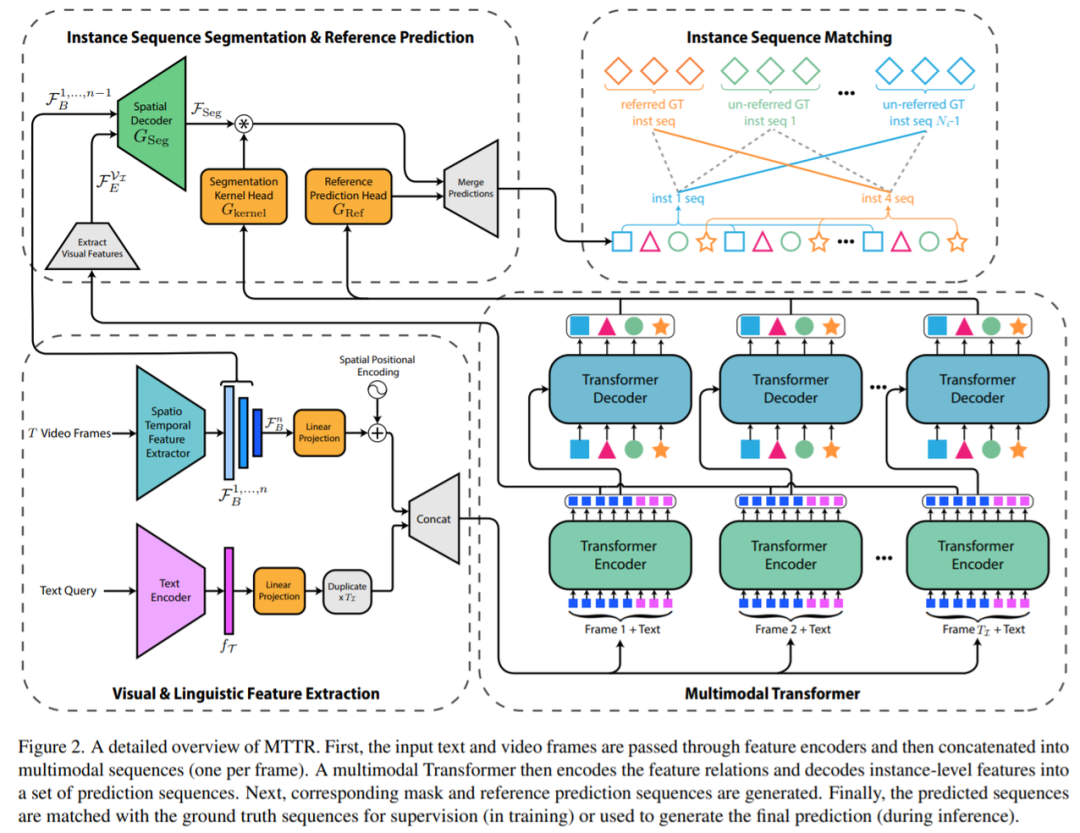
在被 CVPR 2022 接收的一篇论文《End-to-End Referring Video Object Segmentation with Multimodal Transformers》中,来自以色列理工学院的研究者提出了一种简单的、基于 Transformer 的端到端 RVOS 方法——Multimodal Tracking Transformer(MTTR )。
具体地,他们使用 MTTR 将任务建模成序列预测问题。给定一个视频和文本查询,该模型在确定文本参考的对象之前为视频中所有对象生成预测序列。并且,他们的方法不需要与文本相关的归纳偏置模块,利用简单的交叉熵损失对齐视频和文本。因此,该方法相比以往简单的多。
研究者提出的 pipeline 示意图如下所示。首先使用标准的 Transformer 文本编码器从文本查询中提取语言特征,使用时空编码器从视频帧中提取视觉特征。接着将这些特征传递给多模态 Transformer 以输出几个对象预测序列。然后为了确定哪个预测序列能够最好地对应参考对象,研究者计算了每个序列的文本参考分数。为此,他们还提出了一种时序分割 voting 方案,使模型在做出决策时专注于最相关的部分。
![]()
从实验结果来看,MTTR 在 A2D-Sentences 和 JHMDB-Sentences 数据集上分别实现了 + 5.7 和 + 5.0 的 mAP 增益,同时每秒能够处理 76 帧。
研究者还展示了一系列不同对象之间的实际分割效果,如下穿白色 T 恤和蓝色短裤的冲浪者(淡黄色冲浪板)。
![]()
![]()
推荐:
单 GPU 每秒 76 帧,重叠对象也能完美分割,多模态 Transformer 用于视频分割效果惊艳。
论文 5:Do We Really Need Deep Learning Models for Time Series Forecasting?
摘要:
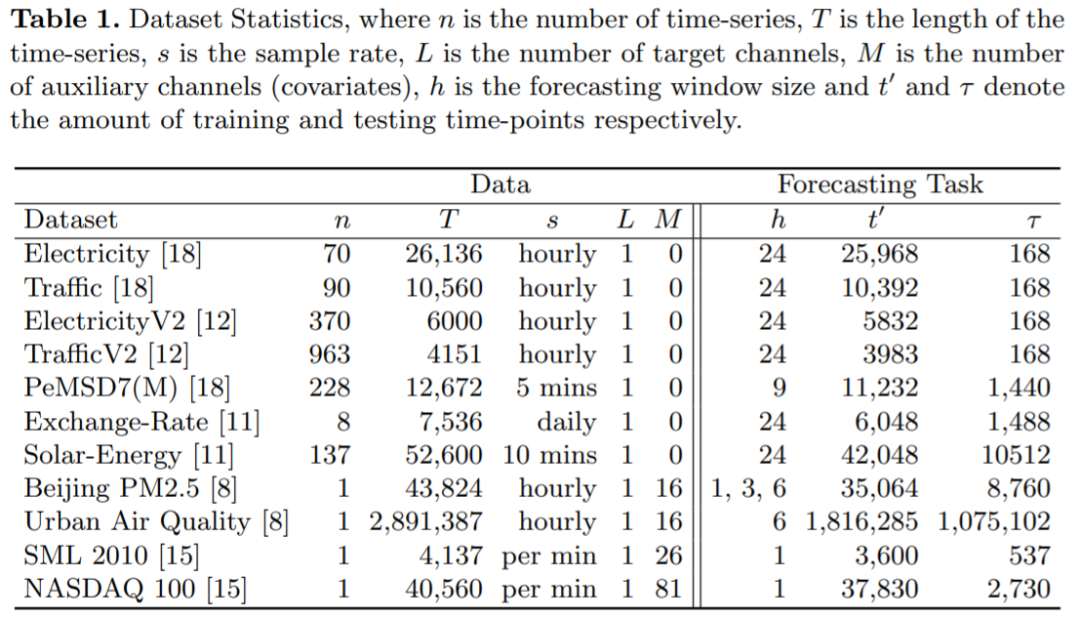
来自德国希尔德斯海姆大学计算机科学系的研究者展示了通过精心配置的输入处理结构,GBRT 等简单但强大的集成模型在时间序列预测领域能够媲美甚至超越很多 DNN 模型。
研究者对特征工程多输出 GBRT 模型进行了评估,并提出了以下两个研究问题:
对于用于时间序列预测的基于窗口的学习框架来说,精心配置 GBRT 模型的输入和输出结构有什么效果?
一个虽简单但配置良好的 GBRT 模型与 SOTA 深度学习时间序列预测框架相比如何?
为了回答这两个问题,研究者选择了双重实验设置,分别解决两类预测任务,即系统化方式中的单变量和多变量预测。目的是评估 GBRT 模型以及在顶会(NeurIPS、KDD、SIGIR、ECML、ICML、CIKM、IJCAI、ICLR 等)中出现的 SOTA 深度学习方法。这项研究的整体贡献可以总结如下:
一,研究者将一个简单的机器学习方法 GBRT 提升了竞品 DNN 时间序列预测模型的标准。首先将 GBRT 转换成一个基于窗口的回归框架,接着对它的输入和输出结构进行特征工程,如此便能从额外上下文信息中获益最多;
二,为了突出输入处理对时间序列预测模型的重要性,研究者通过实证证明了为什么基于窗口的 GBRT 输入设置可以在时间序列预测领域提高 ARIMA 和原版 GBRT 等精心配置的模型所产生的预测性能;
三,研究者比较了 GBRT 与各种 SOTA 深度学习时间序列预测模型的性能,并验证了它在单变量和双变量时间序列预测任务中的竞争力。
这种基于窗口的 GBRT 模型输入设置如图 1 所示:
为了使所选的深度学习基线和 GBRT 之间具有显著的可比性,该研究在相同的数据集上评估了所有模型,数据集如下表 1 所示:左边提供了关于用来评估模型数据集,而右边则列出了各自的实验规范:
推荐:
梯度提升回归树媲美甚至超越多个 DNN 模型。
论文 6:HCSC: Hierarchical Contrastive Selective Coding
摘要:
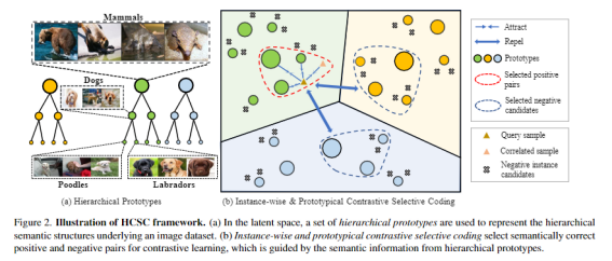
来自上海交通大学、Mila 魁北克人工智能研究所和字节跳动的研究者提出了一种基于层级语义结构的选择性对比学习框架(Hiearchical Contrastive Selective Coding,HCSC)。
这一框架通过将图像表征进行层级聚类,构造具有层级结构的原型向量 (hierarhcical prototypes),并通过这些原型向量选择更加符合语义结构的负样本进行对比学习, 由此将层级化的语义信息融入到图像表征中。该自监督学习框架在多个下游任务中达到卷积神经网络自监督预训练方法的 SOTA 性能。
该工作的方法论框架包含两个重要的模块: 一个是层级语义结构的构建与维护, 另一个是基于层级语义结构的选择性对比学习。
在实现过程中, 该研究采用了简单有效的自底向上层级 K-means 算法, 具体算法流程如下:
推荐:
CVPR 2022,CNN 自监督预训练新 SOTA:上交、Mila、字节联合提出具有层级结构的图像表征自学习新框架。
论文 7:Exploring Endogenous Shift for Cross-domain Detection: A Large-scale Benchmark and Perturbation Suppression Network
摘要:
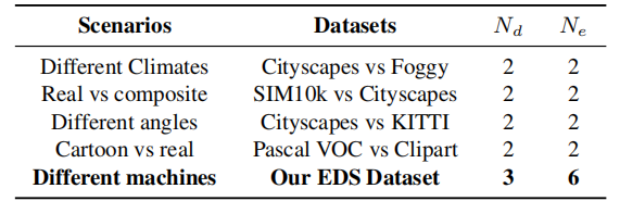
近日,计算机视觉顶级会议 CVPR 2022 接收论文结果已经正式公布,会议接收了一篇由北京航空航天大学、科大讯飞研究院共同完成的工作,论文题目为《Exploring Endogenous Shift for Cross-domain Detection: A Large-scale Benchmark and Perturbation Suppression Network》(之后公布论文链接)。这项工作以 X 光安检场景为例,首先从域间偏移产生原因入手,分析由机器硬件参数等原因造成的域间内生偏移和常见的天气等外部原因造成的域间内生偏移的异同点。此外,该工作还构建了内生偏移自适应能力评估基准,并提出了噪声抑制网络,为跨域检测带来新的思考。
在本文中,研究者们以 X 光安检场景为例,首先从域间偏移产生原因入手,结合常见的自然场景变化,分析外生和内生域间偏移的异同点。然后展示研究者们构建的内生偏移自适应能力评估基准,以及噪声抑制网络,探索目标检测模型在复杂环境下由于感知设备变化导致的脆弱性问题,寻找不同类别物体的领域无关特征的最佳表征。
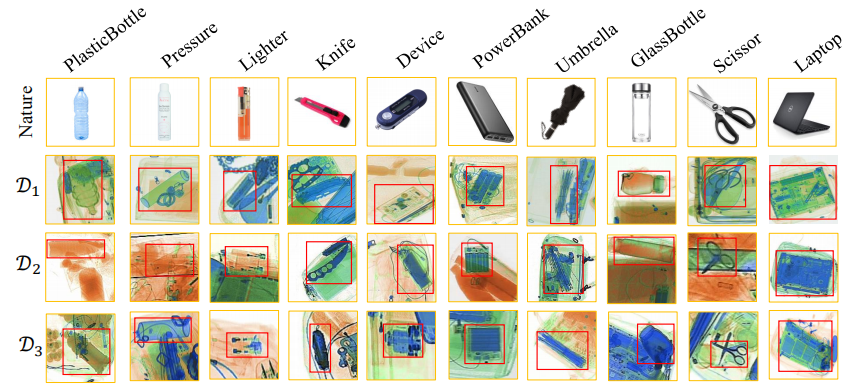
在表 1 中,研究者们从不同场景、领域数量和支持的实验组数分别把 EDS 数据集和跨域检测任务下各种类型的数据集进行了对比。
图 1 EDS 数据集中物品实物图和不同 X 光机器下的成像图
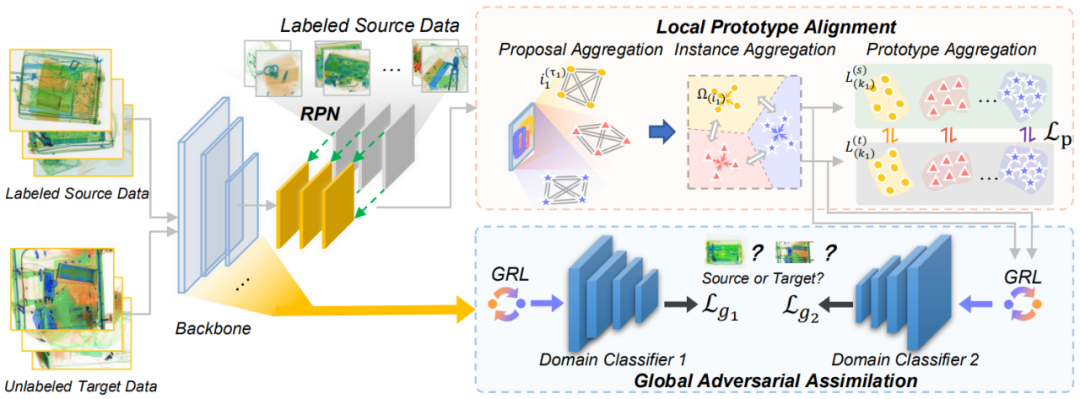
噪声抑制网络的框架图如图 4 所示,它包括两个重要的子模块,分别是局部原型对齐和全局对抗同化。局部原型对齐模块主要针对类别相关噪声,全局对抗同化主要针对类别无关噪声。以下分别展开叙述。
推荐:
CVPR 2022,跨域检测新任务,北航、讯飞提出内生偏移自适应基准和噪声抑制网络。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. Focus on the Target's Vocabulary: Masked Label Smoothing for Machine Translation. (from Liang Chen)
2. Faking Fake News for Real Fake News Detection: Propaganda-loaded Training Data Generation. (from Kathleen McKeown)
3. Sentence-Select: Large-Scale Language Model Data Selection for Rare-Word Speech Recognition. (from Tara N. Sainath)
4. Input-Tuning: Adapting Unfamiliar Inputs to Frozen Pretrained Models. (from Nanning Zheng)
5. DUAL: Textless Spoken Question Answering with Speech Discrete Unit Adaptive Learning. (from Abdelrahman Mohamed)
6. Training language models to follow instructions with human feedback. (from John Schulman)
7. Conditional Bilingual Mutual Information Based Adaptive Training for Neural Machine Translation. (from Jian Liu)
8. Look Backward and Forward: Self-Knowledge Distillation with Bidirectional Decoder for Neural Machine Translation. (from Liang Wang)
9. SimKGC: Simple Contrastive Knowledge Graph Completion with Pre-trained Language Models. (from Liang Wang)
10. Adaptive Discounting of Implicit Language Models in RNN-Transducers. (from Sunita Sarawagi)
1. Leveling Down in Computer Vision: Pareto Inefficiencies in Fair Deep Classifiers. (from Bernhard Schölkopf)
2. Towards Self-Supervised Category-Level Object Pose and Size Estimation. (from Jian Sun)
3. Membership Privacy Protection for Image Translation Models via Adversarial Knowledge Distillation. (from Jian Pei)
4. Building 3D Generative Models from Minimal Data. (from Joshua Tenenbaum)
5. Didn't see that coming: a survey on non-verbal social human behavior forecasting. (from Isabelle Guyon)
6. Fast Neural Architecture Search for Lightweight Dense Prediction Networks. (from Jiri Matas, Janne Heikkila)
7. Contrastive Boundary Learning for Point Cloud Segmentation. (from Dacheng Tao)
8. ART-Point: Improving Rotation Robustness of Point Cloud Classifiers via Adversarial Rotation. (from Dacheng Tao)
9. The Familiarity Hypothesis: Explaining the Behavior of Deep Open Set Methods. (from Thomas G. Dietterich)
10. SelfTune: Metrically Scaled Monocular Depth Estimation through Self-Supervised Learning. (from Dinesh Manocha)
1. Learn to Match with No Regret: Reinforcement Learning in Markov Matching Markets. (from Michael I. Jordan)
2. Score matching enables causal discovery of nonlinear additive noise models. (from Bernhard Schölkopf)
3. Interventions, Where and How? Experimental Design for Causal Models at Scale. (from Bernhard Schölkopf)
4. Zero-shot Domain Adaptation of Heterogeneous Graphs via Knowledge Transfer Networks. (from Ruslan Salakhutdinov)
5. DIME: Fine-grained Interpretations of Multimodal Models via Disentangled Local Explanations. (from Ruslan Salakhutdinov, Louis-Philippe Morency)
6. On the influence of over-parameterization in manifold based surrogates and deep neural operators. (from George Em Karniadakis)
7. A Neuro-vector-symbolic Architecture for Solving Raven's Progressive Matrices. (from Luca Benini)
8. New Insights on Reducing Abrupt Representation Change in Online Continual Learning. (from Tinne Tuytelaars, Joelle Pineau)
9. How to Train Unstable Looped Tensor Network. (from Andrzej Cichocki)
10. Matrix Completion via Non-Convex Relaxation and Adaptive Correlation Learning. (from Xuelong Li)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com