5400亿!谷歌「Pathways语言模型」发布,能理解做推理生成代码
谷歌的下一代架构 Pathways 已经用来训练大模型了。

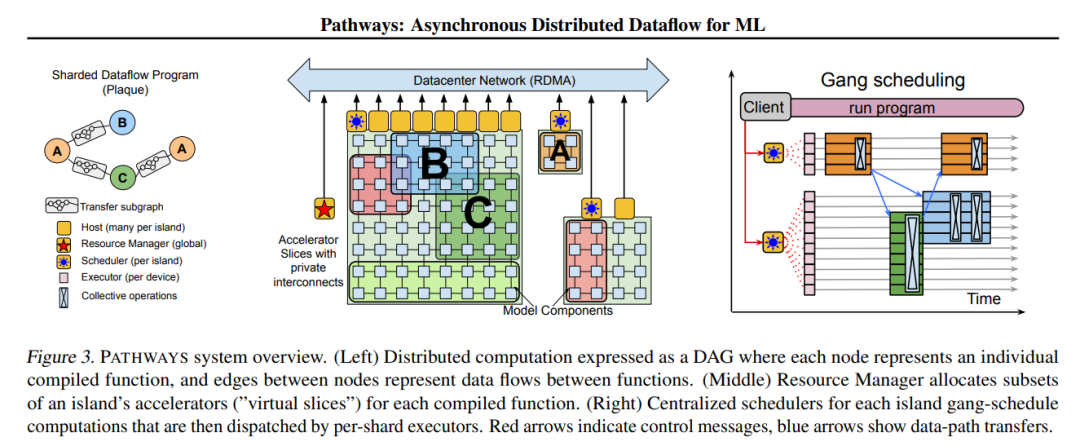

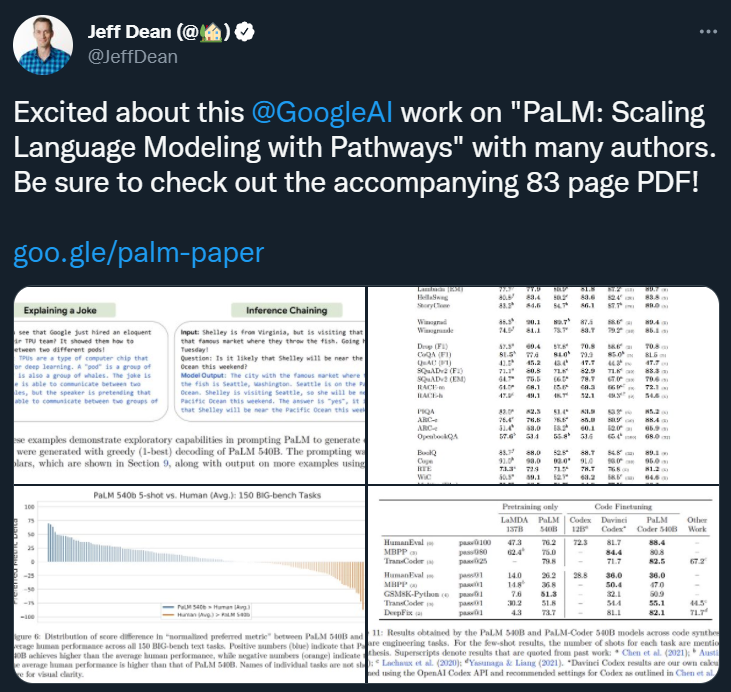

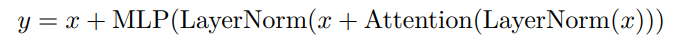
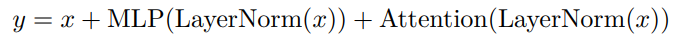
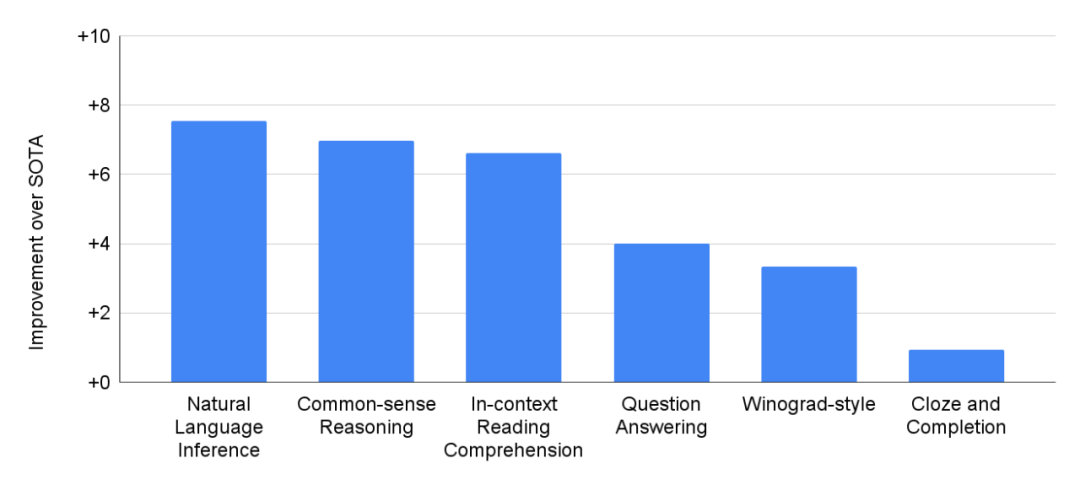
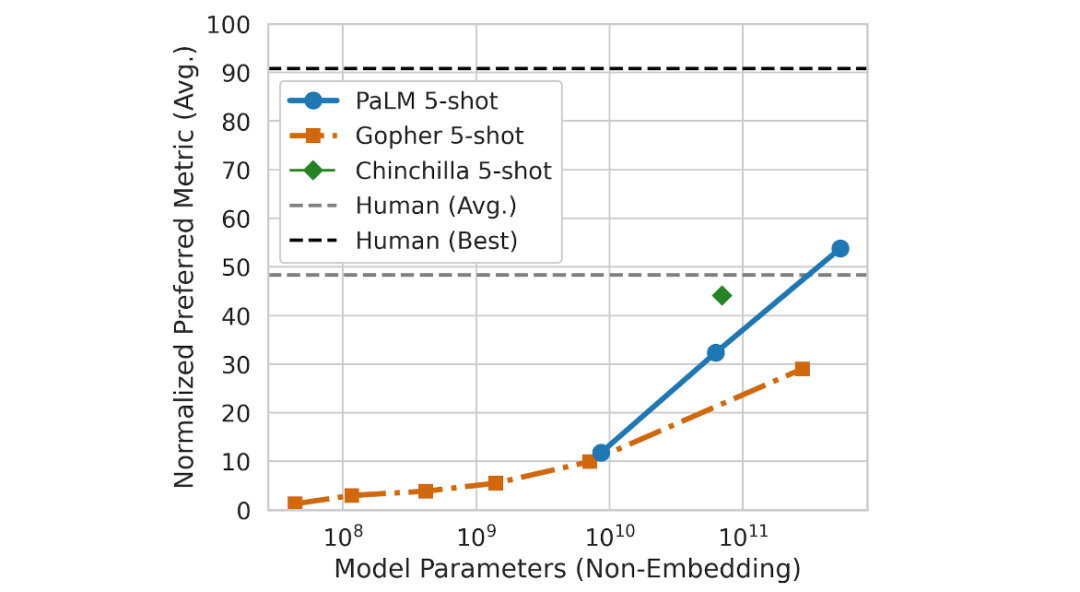


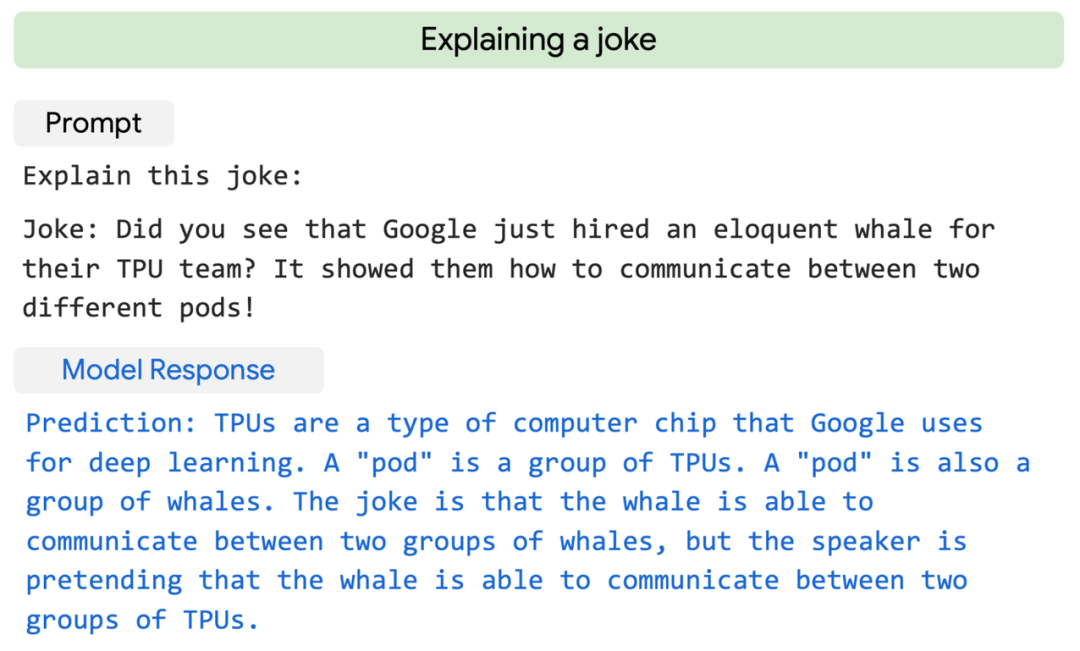

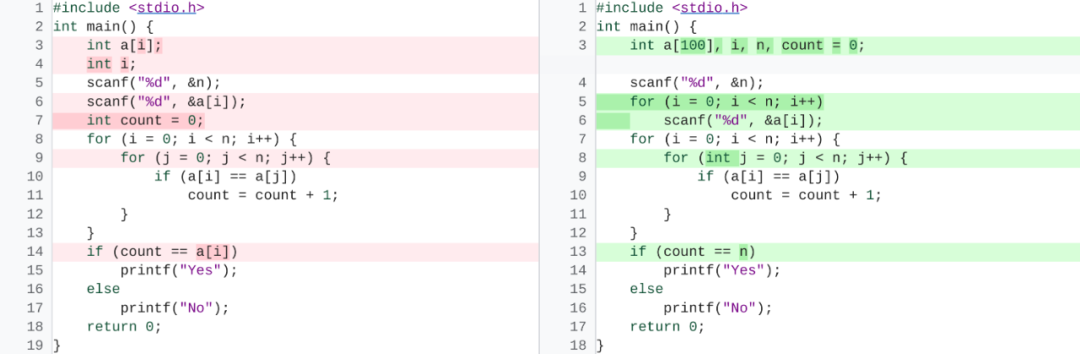
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“PALM” 就可以获取《5400亿!谷歌「Pathways语言模型」发布,能理解做推理生成代码》专知下载链接



登录查看更多
相关内容

Arxiv
12+阅读 · 2018年3月9日



相关VIP内容
相关资讯
相关论文
Arxiv
12+阅读 · 2018年3月9日