【自监督学习机器人】谷歌大脑首次实现机器人端到端模仿人类动作 | 视频
新智元报道
来源: arXiv
编译报道:弗格森 刘小芹 张易
新智元启动 2017 最新一轮大招聘: COO、总编、主笔、运营总监、视觉总监等8大职位全面开放。
新智元为COO和执行总编提供最高超百万的年薪激励;为骨干员工提供最完整的培训体系、高于业界平均水平的工资和奖金。加盟新智元,与人工智能业界领袖携手改变世界。
简历投递:jobs@aiera.com.cn HR 微信:13552313024
【新智元导读】 机器人仅需观察人类行为就能模仿出一模一样的动作,这一机器人领域发展的长期目标最近被谷歌大脑“解锁”。在新发布的一项研究中,谷歌大脑团队介绍了他们使用自监督式学习的方法,通过多视角的时间对比网络(TCN)来实现机器人端到端模仿人类动作。另外,他们所提出的TCN模型,在图像分类上的错误率也大大地低于ImageNet-Inception。

谷歌大脑近日公布了一项新的研究成果,让机器人(机械臂)仅仅通过观察就能模仿人类动作。通过模仿人类行为来学习如何执行新的任务一直都是机器人技术的长期目标,如果凭借深度学习,特别是自监督式的自学习机制,让机器自己掌握模仿人类行为的能力,从而减少甚至省去对机器人动作每一个细节的预编程,这对机器人的发展来说会是飞跃式的进步。
在研究中,谷歌大脑团队称,他们所发布的是一种一种端到端的自监督式(无人类监督)模仿行为,简单表示如下:

图1 左:人类演示动作;中:计算机中对动作的模拟;右:真实的机器人模仿人类动作
但是要想成功地实现“模仿”,机器人必须要弄清楚自己的行为是否与人类展示的行为一致,尽管机器人和人类之间的视角(viewpoint)有很大的不同。比如,在倒饮料这一任务中,机器人必须要理解的概念包括,手与容器的接触,容器的倾斜角度,以及容器内是否有液体在流动。
本研究中,研究者提出了一种方法,让机器人可以仅仅通过观察人类与现实世界的互动来学习表达。在这个视频中,左边是嵌入空间里每个帧的最近邻(nearest neighbors),模型从中学习。模型使用 triplet loss,在多视点观察(multi viewpoint observation)中训练。在嵌入空间中,多个视点共同出现(cooccurring)的帧会彼此吸引,而相同视频中邻近时间步长的视觉上相似的帧会被拉开。这样,嵌入会对不同的视点保持不变,但对表示时间的语义线索敏感,例如液体是否正在被倒入杯子里。
谷歌大脑团队在研究中提出了一个名为TNC的模型,可以从任何测试视频中选择相邻帧,包括液体倾倒的相邻帧。模型能够识别倾倒容器的角度,以及是否流动的液体。
作者在论文中说:“在这种方法下,机器的自我监督学习能力胜过了纯粹的人力监督”。
虽然监督学习在一系列人类很容易就能标注数据的任务,比如物体分类中,已经获得了成功,但是,在许多交互式的应用,比如机器人领域内还有许多难题,被认为对于监督学习来说是非常难的。比如,在一个倒饮料的任务中,要想对每一个细节都进行标签化,以让机器人理解与任务相关的各个方面,这显然是不切实际的。倒饮料的展示,可能会根据容器背景、视角而有所不同,另外,在每一帧的图像中,可能会有许多突出的属性。例如,手是否接触了容器,容器的倾斜度或者目标容器和原容器中的液体量。
理想状态下,现实世界中的机器人应该掌握两种能力:第一,仅仅通过观察就能学会一种互动行为的相关属性;第二,解决人类和机器之间协调的难题,并且通过第三者视角的观察,来模仿人类的行为。
在本研究中,研究者提出了一个自监督式的方法,同时解决了上述两个难题。在学习能够理解物体交互行为的适当的表征的同时,也能让机器人模仿人类的行为。他们从未标签的视频资料(同一个视频,多个视角)中获得学习信号(见下图),并且证明了,在这种情况下学习到的表征,可以有效地区分功能属性,比如,从不同的视角和不同智能体看到的姿势。

图2:无标签的倒饮料模仿,对每一个参照图像(左)最近邻(右),面向不同的模型(多视角TCN,Shuffle & Learn 和 ImageNet-Inception)。这些倒饮料的照片显示,TCN 模型能仅通过自监督观察来区分不同的手势动作以及倾倒的饮料量,同时,模型不会受到视角、北京、物体和主题以及动态模糊和规模的影响。

图3:无标签的姿势模仿:对每一个参照图像(左)最近邻(右)。虽然只经过自监督式的训练(无人类标注),多视角的TCN 能同时连接人类和机器之间的姿势,比如,挤压、抬手等等,同时,在视角、背景和主题和规模变化的情况下保持不变。
模仿者(机器臂)能够通过自监督的回归分析,把这些视觉上的表征与相应的动作表征联系起来,最后在无需人类标签的情况下,实现了端到端的模仿。
和此前绝大多数在自监督式表征学习上的研究相比,这一研究的目的不仅是获得更好的表征来完成词义分类、探测或者分割任务。研究者基于既有表征(比如,经过训练用于ImageNet 分类项目中的特征网络)来提高机器区分物体、人类和环境之间的交互行为的能力,同时,在其他变量,比如视角和外观加入时,也保持稳定性。
这是此项研究的另一个亮点:多视角的TCN模型的表征效果在图像分类上的错误率已经远远低于著名的ImageNet-Inception。
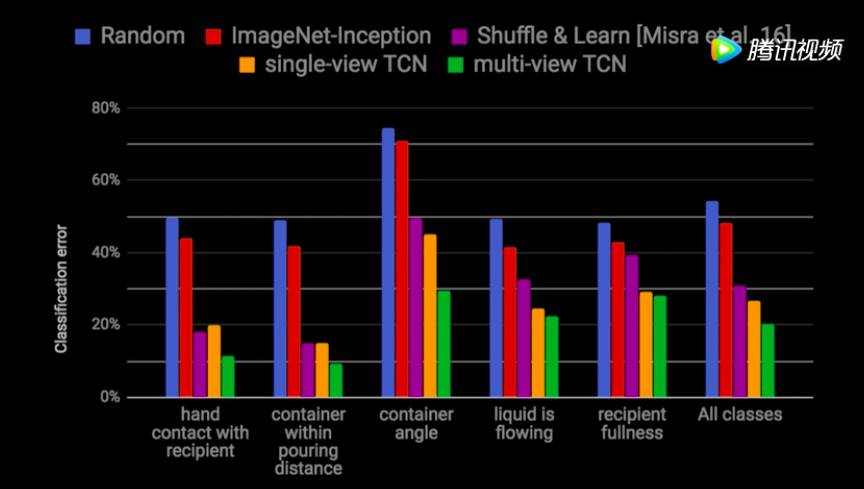
图:属性分类错误率:TCN模型优于基线模型,multi-view TCN表现最好。
最后,研究者称,他们的表征超越了ImageNet 分类项目的著名模型,比如Inception model。鉴于这些模型都已经有了词意相关的特征,以语义类的任务,比如识别来对本研究的方法进行评估并不是一个有意义的标准。所以,研究者通过一些强调理解交互行为和动作的任务来对这些表征进行评估:比如,对展示的倒水动作进行分类、理解操作任务中的各个阶段、让机器人模拟人类动作。
总结起来,这一研究的贡献可以总结如下:
介绍了一个非监督式的学习模型,能够对人或者物体间的交互行为进行表征,同时,也可以学习视角、开关、运动模糊、光线和背景灯变量。
通过实验证明了多视角协作相比单视角信号的优越性。
首个实现了自学习式端到端机器对人类动作的模仿(不需要任何的标签或者关于人类动作的具体表征)
多视角时间对比监督
研究所使用的方法称为时间对比(Time-Contrastive,TC)监督,如图4所示。该方法通过 triplet loss 使用多视角度量进行学习。 核心思想是将来自同一时间但不同视角(或模态)的两帧(anchor 和正图像)拉在一起,而来自时间相邻者的视觉相似帧被放到一边。TC 信号可用于多种用途。首先,跨视角通信能够促进学习视角、尺度、遮挡,运动模糊,光照和背景的不变性,因为正面和主体帧呈现了带有上述这些因素的变体的事物。下图显示了除了遮挡之外,顶部和底部序列之间的所有变化。
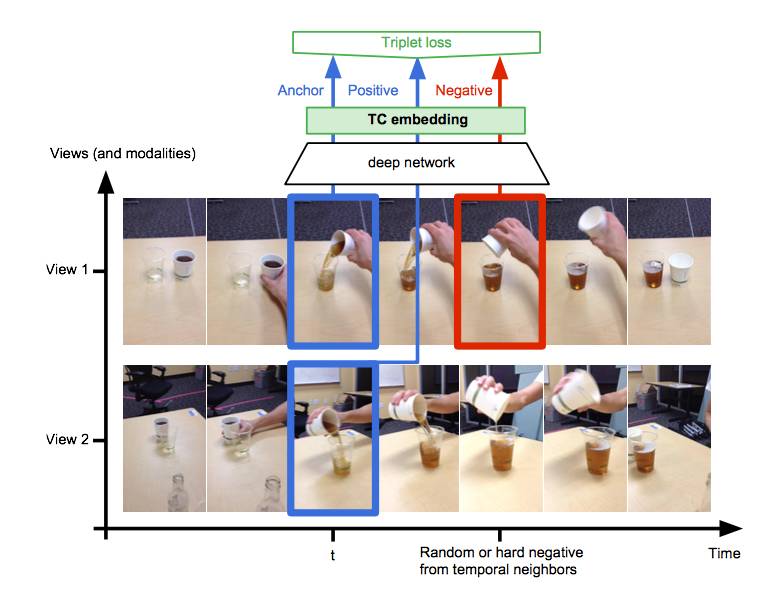
图4,时间对比网络,Time-Contrastive Networks (TCN)在嵌入空间中,从相同时间点上不同视角获得的Anchor 和正图像之间的距离会更近,同时,它们与从相同序列但是时间点上不同的负图像之间的距离要远一些。这会迫使模型去捕获哪些随着时间变化但是在视角上有连贯性的属性,比如手势。同时,这也能保证,在背景或者关系变化时,模型能保持稳定。
单视角TCN
作者在文中介绍,还可以考虑在单视图视频上训练的时间对比模型,如图5所示。在这种情况下,正图像帧在 anchor 帧的一定范围内随机选择。然后在正图像范围内计算边际范围。 在边际范围之外随机选择负图像,并如前所述训练模型。
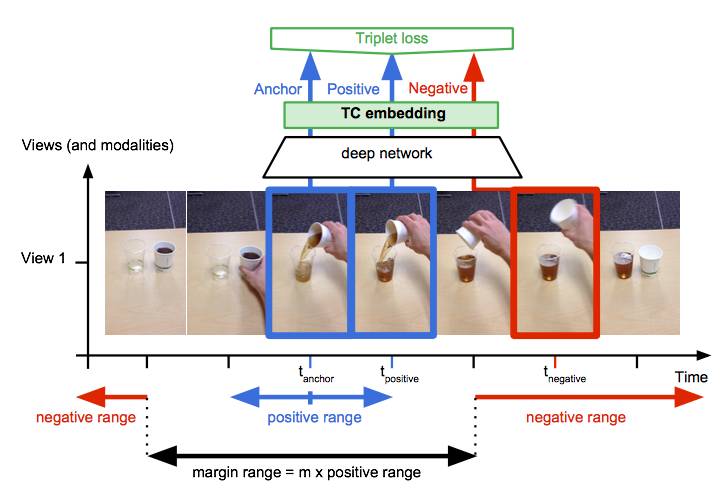
图5 单视角TCN:正图像在anchor周边的小窗中被选择,负图像在同样序列的不同时间步中被选择。

我们提出了一种用自我监督来学习表征的方法,可以完全从多个视点记录的未标注视频中进行学习。这一研究与机器人模仿学习尤其相关,机器人模仿学习要求系统对人与自然环境之间的关系有所理解(视角不变),包括对象交互、属性以及身体姿态。我们使用 triplet loss 来训练表征,其中同一个观测的多个同时视角被吸引在嵌入空间中,同时被从视觉上相似但功能上不同的时间相邻者排斥。这一信号鼓励我们的模型去发现不随视角变化而随时间变化的属性,同时忽略掉如遮挡、运动模糊、光和背景这样的有干扰性的变量。
我们的实验表明,这样的表征甚至要求对象实例某种程度上的不变性。研究表明我们的模型可以正确地识别复杂对象交互中的相应步骤,例如在带有不同实例的不同视频之间倒水。 据我们所知,我们的研究首次显示了真实机器人对人类运动进行端对端模拟学习的自我监督的结果。
论文地址:https://arxiv.org/pdf/1704.06888.pdf
新智元招聘
职位:客户总监
职位年薪:30 - 60万(工资+奖金)
工作地点:北京-海淀区
所属部门:客户部
汇报对象:COO
下属人数:8 人
工作年限:5 年
语 言:英语 + 普通话
学历要求:全日制统招本科
职位描述:
热爱人工智能,在行业内有一定的人脉资源和影响力;
为客户制定媒体关系策略和公关活动策划,达成客户的市场或传播目标;
负责监督公关项目的计划和实施,使项目能按期在预算内完成;
积极拓展客户资源,开发公司业务,与既有客户保持紧密的业务联络和沟通;
监督、管理及考核客户服务团队,全面提升公司客户服务质量;
理工科背景优先,有知名企业或知名媒体机构工作经验者优先。
应聘邮箱:jobs@aiera.com.cn
HR微信:13552313024
新智元欢迎有志之士前来面试,更多招聘岗位请点击【新智元招聘】查看。





