
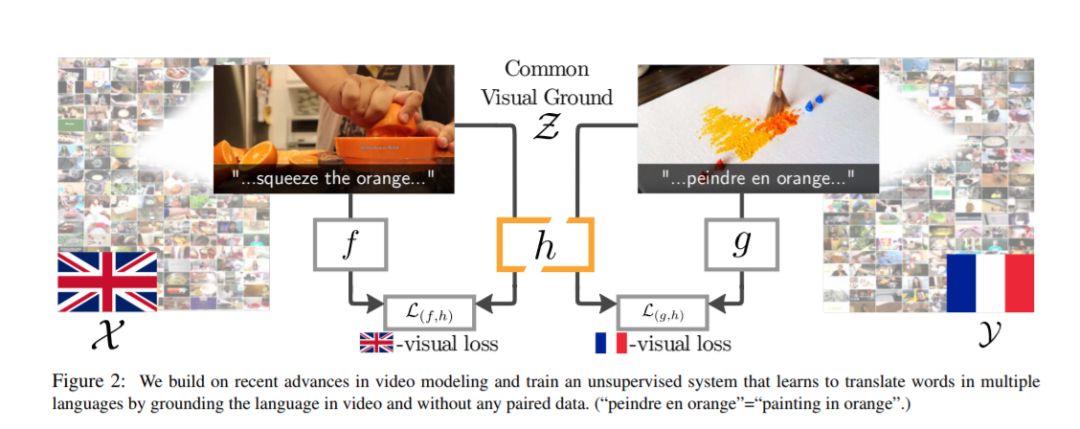
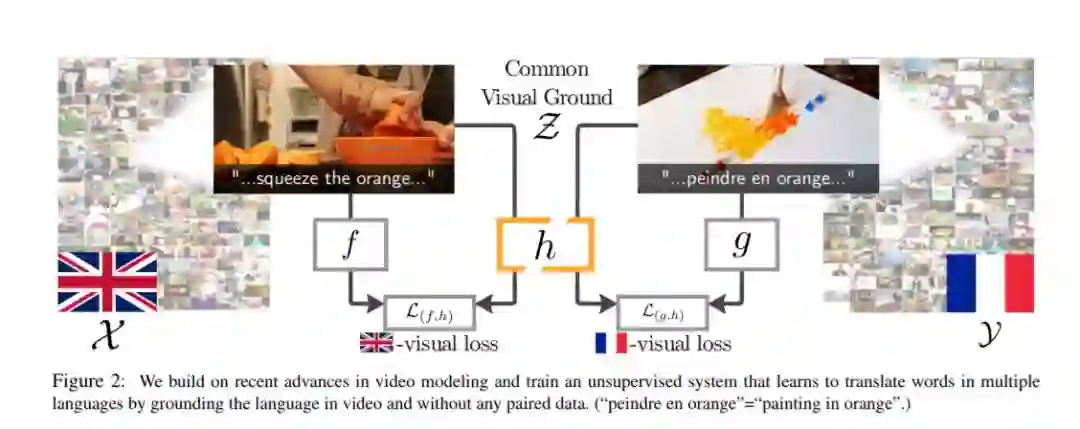
地球上有成千上万种活跃的语言,但只有一个单一的视觉世界。根植于这个视觉世界,有可能弥合所有这些语言之间的鸿沟。我们的目标是使用视觉基准来改进语言之间的非监督词映射。其核心思想是通过学习母语教学视频中未配对的嵌入语,在两种语言之间建立一种共同的视觉表达。考虑到这种共享嵌入,我们证明(i)我们可以在语言之间映射单词,特别是“可视化”单词;(ii)共享嵌入为现有的基于文本的无监督单词翻译技术提供了良好的初始化,为我们提出的混合可视文本映射算法MUVE奠定了基础;(iii)我们的方法通过解决基于文本的方法的缺点来获得更好的性能——它更健壮,处理通用性更低的数据集,并且适用于低资源的语言。我们将这些方法应用于将英语单词翻译成法语、韩语和日语——所有这些都不需要任何平行语料库,而只是通过观看许多人边做边说的视频。
成为VIP会员查看完整内容
相关内容

专知会员服务
36+阅读 · 2020年3月12日
专知会员服务
13+阅读 · 2020年3月12日
Arxiv
6+阅读 · 2018年1月28日

相关VIP内容
专知会员服务
36+阅读 · 2020年3月12日
专知会员服务
13+阅读 · 2020年3月12日
相关资讯
相关论文
Arxiv
6+阅读 · 2018年1月28日