Google提出Grasp2Vec模型:利用自监督方法学习物体表示

更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
在年龄很小很小的时候,我们就能够识别自己喜欢的物品并将它们捡起来——尽管从未有人明确地教过我们如何这样做。根据认知发展研究(详见:https://www.ncbi.nlm.nih.gov/pubmed/8542971),与世界中的物体相互作用的能力(例如有针对性的抓取),在人类感知和操纵物体的能力形成的过程中起着至关重要的作用。通过与周围世界的互动,人们能够进行自监督学习:我们知道自己采取了什么行动,并能够从结果中学习。在机器人技术领域,人们正在积极研究这种类型的自监督学习,因为它使机器人系统能够在缺少大量训练数据或无人工监督的情况下进行学习。
受“客体永久性(object permanence)”概念的启发,我们提出了 Grasp2Vec(详见:https://sites.google.com/site/grasp2vec/)——一种用于获取物体表示的简单而高效的算法。Grasp2Vec 基于这样的直觉:尝试抓取任何东西都会提供以下几条信息—— 如果机器人抓住一个物体并将其抬起,则物体必须在抓取前进入场景。此外,若机器人知道它抓住的物体当前处于其抓取器中,就会将其从场景中移除。通过使用这种形式的自监督,机器人可以利用抓取前后的场景视觉变化来学习识别物体。

基于我们之前与 X Robotics(详见:https://ai.googleblog.com/2018/06/scalable-deep-reinforcement-learning.html)的合作项目(该项目的任务是让一系列机器人同时学习使用单目相机输入来抓取家用物品),我们让机械臂“无意地”抓住物体,这种经验可以帮助机器人学到更丰富的物体种类。然后,可以利用这些表示来获取“有意识地抓取”能力,即机械臂可以抓取用户指定的物体。
在强化学习的框架中,任务的成功与否是通过“奖励函数(reward function)”来衡量的。通过最大化奖励函数,机器人可以从头开始自学各种各样的技能(详见:http://ai.googleblog.com/2018/06/scalable-deep-reinforcement-learning.html)。如果任务的成功与否可以通过简单的传感器测量来衡量,设计奖励函数就很容易。一个简单的例子是,给定一个按钮,当它被推动时,机器人便可直接获取奖励(详见:https://en.wikipedia.org/wiki/Operant_conditioning_chamber)。
然而,当我们的成功标准取决于对当前任务的“感性理解”时,设计奖励函数就要困难得多。考虑实例抓取的任务,其中机器人看到的是被保持在抓手中的期望物体的图片。机器人试图抓住该物体后,它会检查抓取器的内容。此任务的奖励函数可以看作物体识别问题:抓住的物体是想要的吗?

左图:抓手握住刷子,背景中有一些物体(黄色杯子,蓝色塑料块)。右图:抓手握住黄色杯子,刷子在背景中。如果左图是期望的结果,则一个好的奖励函数应该“理解”上面的两个图像中抓手抓到的是不同的物体。
为了解决这种识别问题,我们需要一种感知系统:该系统能从非结构化图像数据中提取有意义的物体概念(没有任何人类注释),以无监督的方式学习物体的视觉感知。无监督学习算法起作用的核心是其对数据做出的结构性假设。通常假设图像可以被压缩到低维空间中(详见:https://en.wikipedia.org/wiki/Autoencoder),并且可以从视频中之前的帧预测当前的帧(详见:https://papers.nips.cc/paper/6161-unsupervised-learning-for-physical-interaction-through-video-prediction.pdf)。不过,如果没有对数据内容的进一步假设,这些信息通常不足以学习出被分解开的多个物体的表示。
如果我们在数据收集过程中用一个机器人将物体彼此物理地分开,会怎么样呢?机器人领域为表示学习提供了一个令人兴奋的机会,因为机器人可以操纵物体,从而提供数据所需的变化因素。我们的方法基于这样一种观察:物体一旦被抓取,就被从场景中移除了。这样,我们可以获得:1)抓取前的场景图像,2)抓取后的场景图像和 3)抓握物体本身的孤立视图。

左:抓取前的物体;中:抓取后的物体;右:被抓取的物体
如果我们考虑一个从图像中提取“物体集合”的嵌入函数,那么此函数应该满足以下减法关系:

抓取前的物体 - 抓取后的物体 = 被抓取的物体
我们使用了全卷积架构和简单的度量学习算法来实现这种等式关系。训练时,下图中的架构将预抓图像和后抓图像嵌入密集的空间特征图(详见:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn.pdf)中。特征图经过平均池化保存到向量中,而“先掌握”和“后掌握”向量的差表示一组物体。该向量和对应的被抓取物体的向量表示之间的等价约束是通过 N-Pairs 目标函数(详见:http://www.nec-labs.com/uploads/images/Department-Images/MediaAnalytics/papers/nips16_npairmetriclearning.pdf)实现的。
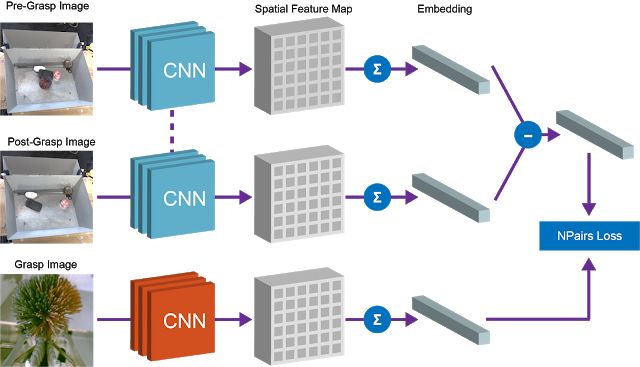
训练过后,我们的模型中自然而然地会出现两个有用的属性。
第一个属性是,我们可以利用向量嵌入之间的余弦距离对物体进行比较,并确定它们是否相同。这个属性可以用于实现强化学习的奖励函数,并允许机器人在没有人工提供的标签的情况下学习实例抓取。
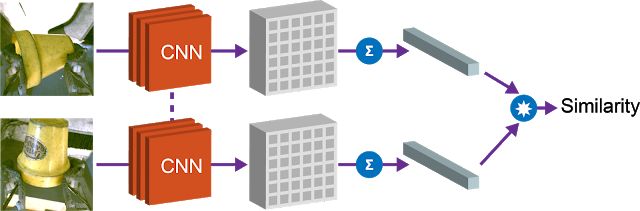
第二个属性是,我们可以组合场景空间映射和物体嵌入来本地化图像空间中的“查询对象”。通过对空间特征图和对应的查询对象向量进行逐元素相乘,我们可以找到空间映射中与查询对象“匹配”的所有像素。
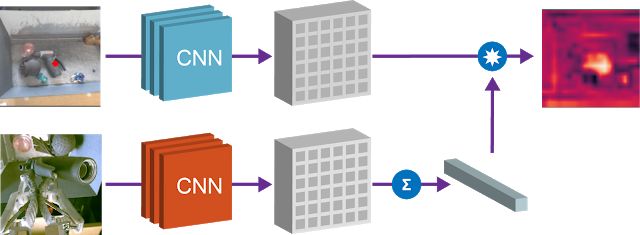
图:使用 Grasp2Vec 嵌入来本地化场景中的物体。左上角的图像显示了桶中的物体。左下角是我们想要抓取的查询对象。通过将查询对象矢量与场景图像的空间特征做点乘,我们得到每像素“激活图”(右上图像)。该图像表示两张图像的各区域相似度。该响应图可用于接近物体,从而进行抓取。
当有多个对象与查询对象匹配时,或甚至查询包含多个对象(两个向量的平均值)时,我们的方法也有效。例如下图中的场景,我们的模型可以检测出场景中的多个橙色块。

点乘操作得到的“热图(heatmap)”可用于规划机器人接近目标物体的方法。我们将 Grasp2Vec 的本地化和实例识别功能与我们的“抓取一切”策略相结合,在数据收集过程中所看到的物体上获得了 80% 的成功率,在机器人以前未遇到的新对象上获得了 59%的成功率。
在我们的论文中(详见:https://arxiv.org/abs/1811.06964),我们展示了机器人抓取技能如何生成用于学习以物体为中心的表示的数据。然后,我们可以使用表示学习来“引导”更复杂的技能,例如实例抓取,同时保留我们的自主抓取系统的自监督学习属性。
除了我们自己的工作,最近的一些论文还研究了如何通过抓取(详见:https://arxiv.org/abs/1806.08756)、推动(详见:https://arxiv.org/abs/1606.07419)和以其他方式操纵(详见:https://arxiv.org/abs/1806.08354)环境中的物体、获得自监督交互,从中学习物体表示。展望未来,我们很兴奋,这种兴奋不仅来自机器学习通过优化机器人的理解、控制能力,可以为机器人技术带来怎样的进步,也来自机器人技术在新的自监督范式方面能为机器学习注入怎样的新鲜血液。
这项研究由 Eric Jang,Coline Devin,Vincent Vanhoucke 和 Sergey Levine 完成。我们要感谢 Adrian Li,Alex Irpan,Anthony Brohan,Chelsea Finn,Christian Howard,Corey Lynch,Dmitry Kalashnikov,Ian Wilkes,Ivonne Fajardo,Julian Ibarz,Ming Zhao,Peter Pastor,Pierre Sermanet,Stephen James,Tsung-Yi Lin,Yunfei Bai,和 Google、X 公司和中的许多其他员工,以及更广阔的机器人社区中的许多其他研究者为改进这项工作做出的贡献。
原文链接:
https://ai.googleblog.com/2018/12/grasp2vec-learning-object.html

喜欢这篇文章吗?记得点一下「好看」再走👇


