
【导读】如何利用未标记数据进行机器学习是当下研究的热点。最近自监督学习、对比学习等提出用于解决该问题。最近来自Google大脑团队的Luong博士介绍了无标记数据学习的进展,半监督学习以及他们最近重要的两个工作:无监督数据增强和自训练学习,是非常好的前沿材料。
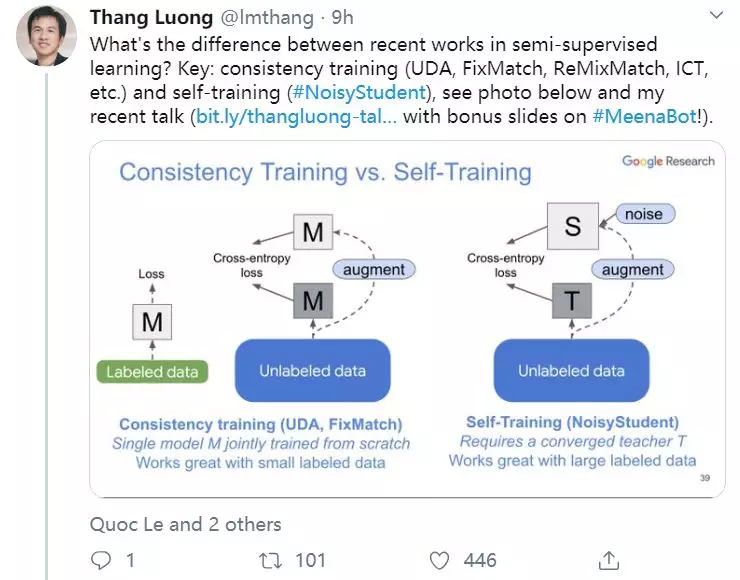
深度学习尽管取得了很大成功,但通常在小标签训练集中表现不佳。利用未标记数据改善深度学习一直是一个重要的研究方向,其中半监督学习是最有前途的方法之一。在本次演讲中,Luong博士将介绍无监督数据增强(UDA),这是我们最近的半监督学习技术,适用于语言和视觉任务。使用UDA,我们仅使用一个或两个数量级标记较少的数据即可获得最先进的性能。
在本次演讲中,Luong博士首先解释了基本的监督机器学习。在机器学习中,计算机视觉的基本功能是利用图像分类来识别和标记图像数据。监督学习需要输入和标签才能与输入相关联。通过这样做,您可以教AI识别图像是什么,无论是对象,人类,动物等。Luong博士继续进一步解释神经网络是什么,以及它们如何用于深度学习。这些网络旨在模仿人类大脑的功能,并允许AI自己学习和解决问题。

成为VIP会员查看完整内容

相关内容
Arxiv
7+阅读 · 2019年2月8日


相关VIP内容
相关资讯