使用强化学习训练机械臂完成人类任务

本文为 AI 研习社编译的技术博客,原标题 :
Training a Robotic Arm to do Human-Like Tasks using RL
作者 | Alishba Imran
翻译 | 吕鑫灿
校对 | 约翰逊·李加薪 审核 | 酱番梨 整理 | 立鱼王
原文链接:
https://medium.com/datadriveninvestor/training-a-robotic-arm-to-do-human-like-tasks-using-rl-8d3106c87aaf
注:本文的相关链接请访问文末二维码

今天在各行业部署的工业机器人大多是在执行重复的任务。基本上是在预定好的轨迹中移动或者放置物体。但事实上,机器人在如今的制造业中处理不同或者复杂任务环境的能是非常有限的。
我们必须克服的主要挑战是设计适应性强的控制算法,以便于更好更快地适应新的环境。
对我们而言幸运的是,我们可以使用人工智能中被称为强化学习的领域来攻克这些挑战。
强化学习(RL)
强化学习(RL)是机器学习的一类,我们可以通过执行操作和查看结果来教授代理在环境中如何表现。
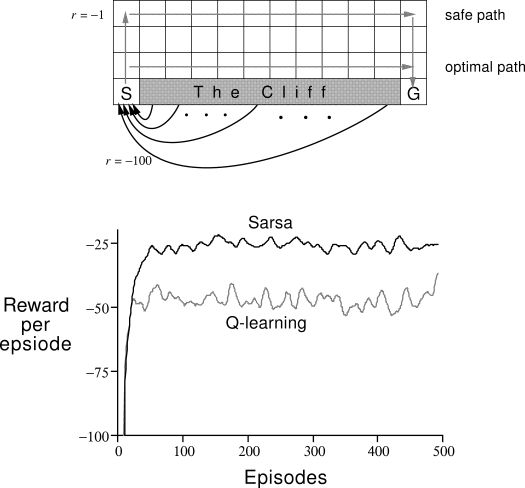
强化学习的概念已经存在一段时间了,但算法的适应性不强,无法完成连续的任务。下面是Richard Sutton的书中的一个经典的示例。
在Deep Q-Networks开始变得越来越流行之后,人们意识到深度学习方法可以用来解决高维度问题。
直到最近纪念,我们才看到这方面有很多改进。我们在2014有像DeepMind and the Deep Q learning architecture这样的炫酷的公司,在2016年有击败了世界围棋冠军的AlphaGo,在2017年有OpenAI and the PPO以及更多即将涌现的企业。
我的仿真:OpenAi的机器人环境
去年,OpenAi发布了八个新的仿真机器人环境。我是用了Fetch并训练它来执行以下操作:
1.FetchReach-v0:移动它的末端到设定的目标位置。

2. FetchSlide-v0:在长桌上击打冰球,使其滑向设定好的目标点,目标点每次都会改变。
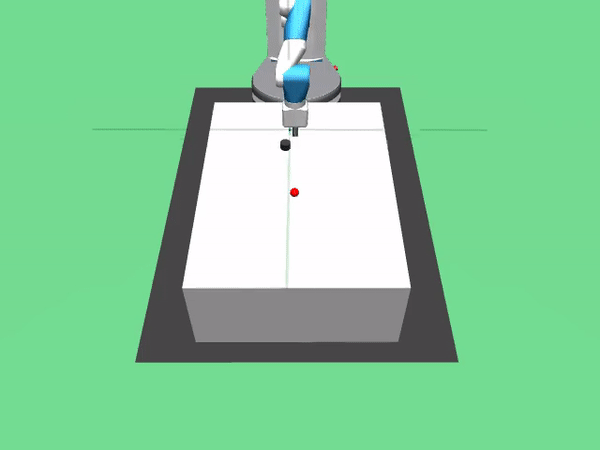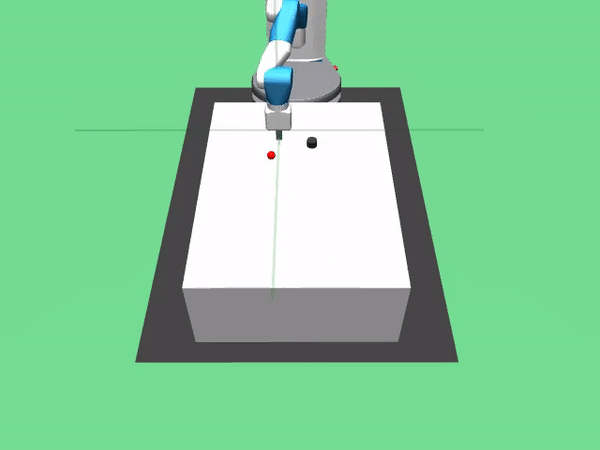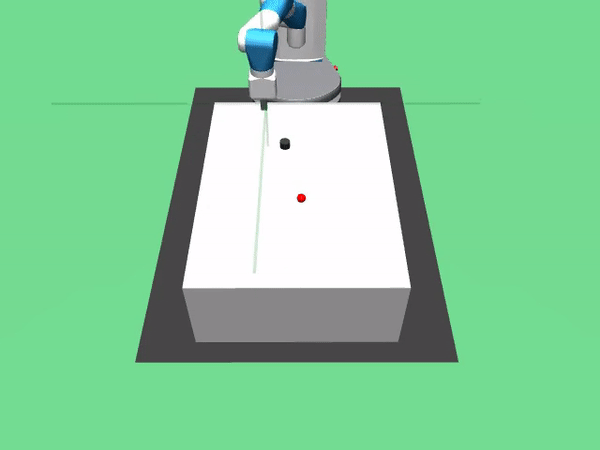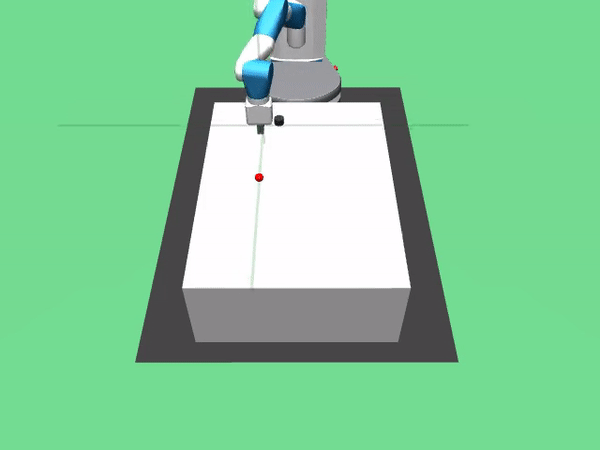
3. FetchPush-v0:通过推动方块来移动方块直到木块到大设定的目标点。
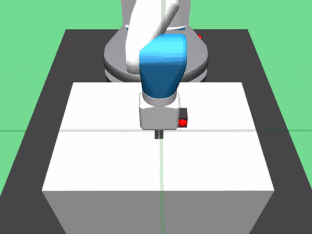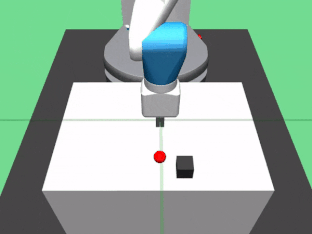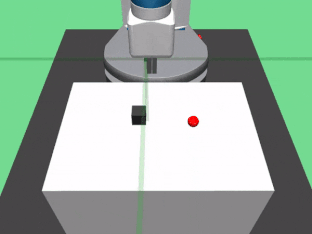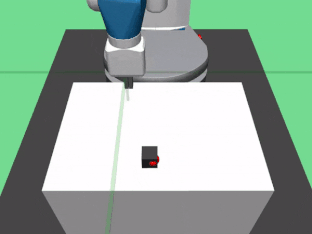
4. FetchPickAndPlace-v0:使用它的夹持器拿起木块并将其移动到目标点。

本文中,我将解释这项工作背后的一些理论。以下是我主要涉及到的几个部分:
强化学习基础
Q-Learning
Deep-Q Network(DQN)
Deep Deterministic Policy Gradients(DDPG)
Hindsight Experience Reply: HER
代码
强化学习基础
马尔可夫决策过程(MDP)——代理,行动,奖励
对于强化学习,我们使用一个成为马尔可夫决策过程(MDP)的框架,它为非常复杂的问题提供了一个简单的框架。代理(例如机器人手臂)将首先观察其所处的环境并采取相应的行动。根据结果给出奖励。
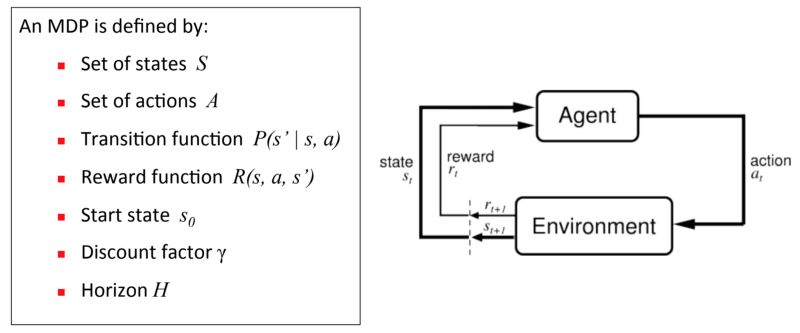
对于机器人控制,状态是通过测量关节角度,速度和末端执行器姿态的传感器来测得的:
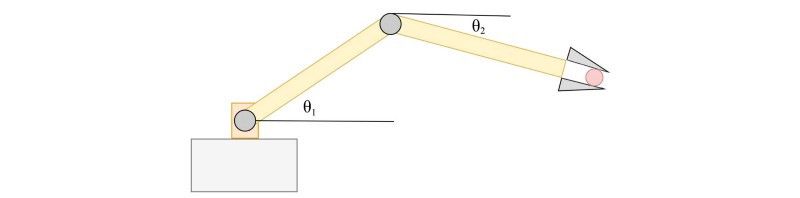
Policy
主要目标是找到一项策略。策略是告诉我们在特定状态下如何采取行动的。目标是找到一个能够做出最有价值决策的策略:
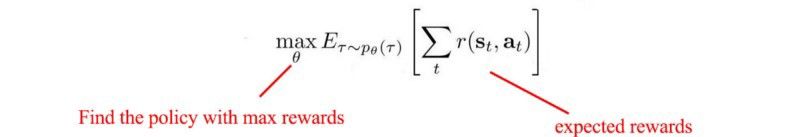
现在,你把目标放在一起。我们希望找到最大化预期回报或最小化成本的行动。
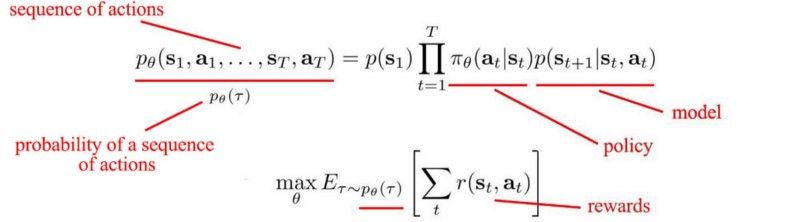
这是强化学习的整体思路,如果你想了解强化学习中的更多细节,请查阅这篇文章(点击原文查看)或观看我对于Alp的评论。
Q-Leaning
Q-learning是一种无模型强化学习算法,这意味着它不需要环境模型。它特别有效,因为它可以处理伴随有随机转换和奖励的问题,而无需进行调整。
大多数Q-learning方法由以下几步组成:
采取行动
观察奖励和下一个状态
采取最高Q的行动。
Q-表
Q表只是一个简单的观测表,我们可以计算每个状态下的最佳的行动。
您可以在Q表中为您的环境建模,列表示行动,行表示状态。
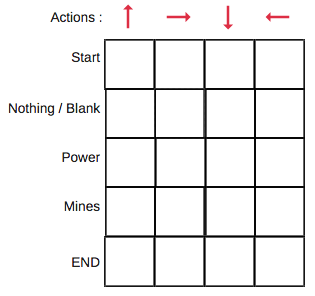
每个Q表得分将是机器人在该状态下采取该行动时将活得的最大预期未来奖励。您将迭代这个直到你找到最佳的答案。
为了学习Q表的每个值,我们使用Q-learning算法。
Q-Learning算法:Q函数
Q函数使用Bellman方程并采用两个输入:状态(s)和动作(a)。
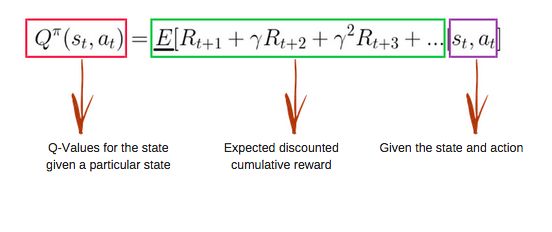
在大多数情况下,因为Q表中的所有值都以0开始,我们可以获得表中每一单元格的Q值。
当我们开始探索环境时,通过不断更新表中的Q值,Q函数为我们提供了越来越好的拟合效果。
现在,让我们了解更新是如何进行的。
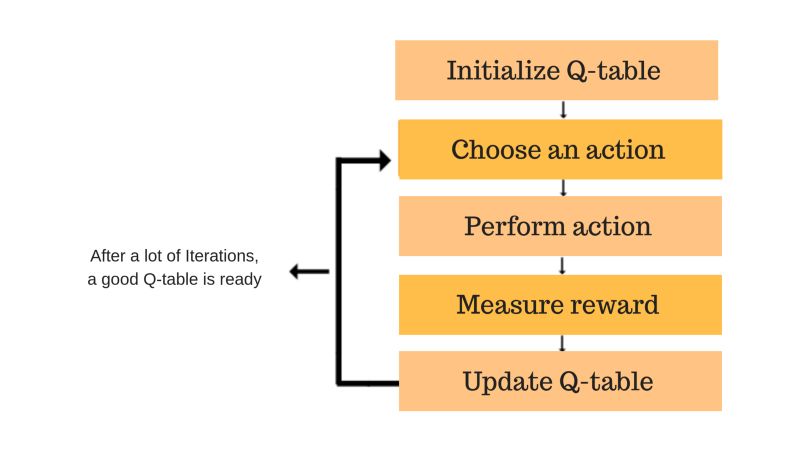
Q-learning 算法过程
第一步:初始化Q表
首先,必须构建一个Q表。有n列m行,其中n表示动作数,m表示状态数。所有值均从0开始。
第二部和第三步:选择并执行动作
根据Q表选择状态(s)中的动作(a)。Q初始化为零。这意味着尚未执行任何具体的操作。具体的话这部分可以使用勘探和开发的概念(具体可以查阅此处:https://medium.freecodecamp.org/a-brief-introduction-to-reinforcement-learning-7799af5840db?gi=85e2b6738bc8)。
现在,我们可以使用一种叫做epsilon-greedy的策略。在游戏开始时,epsilon率会更高因为机器人不太了解环境,因此需要花更多的时间来了解它。随着机器人探索环境,epsilon率降低,机器人开始利用环境。
现在,更新q值并执行动作。
第四和第五步:评估
现在我们已经执行动作并观测产出/奖励。我们需要更新函数Q(s,a)。

大多数情况下,我们只是一次又一次地重复这个操作,直到机器人学会了并且Q表将被更新。这些是我们所做的所有步骤:
Deep Q-networl(DQN)
DQN对于Q-learning非常中啊哟,它通过使用深度神经网络来拟合Q。在强化学习中,随着机器探索更多它会搜索得更好,但这很糟糕,因为输入空间和动作不断变化,这也是我们更新Q的目标值的方式。
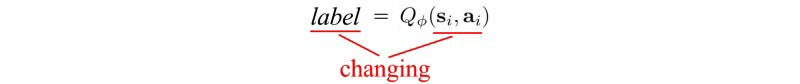
策略梯度
三种强化学习方法:
基于模型的强化学习使用模型和成本函数来找到最佳路径。
值学习使用V或Q值来推导最优策略。
策略梯度方法侧重于策略。
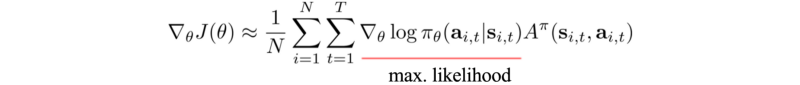
我们使用下面这个差值结合梯度上升来更新策略。

Actor-critic方法
每次更新策略时,我们都需要重新采样。计算模型需要多次迭代。
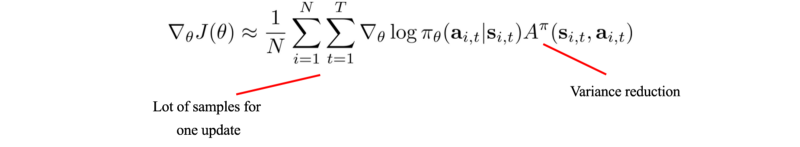
在Actor-critic方法中,我们使用actor来简历策略和评价模型V。通过引入一个评价,我们较少了为每次策略更新收集的样本数量。并且直到一次迭代的结束时才搜集所有的样本。
actor-critic算法与策略梯度法非常类似:
第二步:拟合V值函数(critic)。
第三步:TD计算A。
第五步:更新我们的策略(actor)。
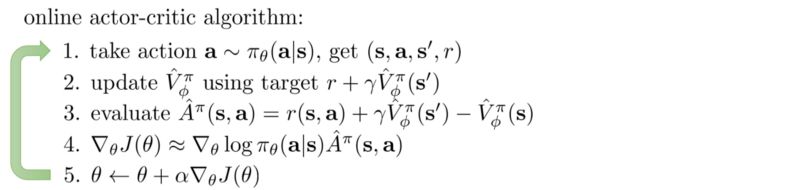
深度确定性策略梯度(DDPG)
Google DeepMind设计一种可靠的算法来解决连续动作空间问题。他们制定了一种被称为深度确定性策略(DDPG)的策略梯度actor-critic算法,该算法是离线的和无模型的,并且使用深度Q网络(DDPG)中的一些相同方法。
离线与在线
强化学习算法是离线的,这只是意味着它们有一个来自于正在改进的单独的行为策略(用于模拟轨迹)。Q-learning是一种离线算法,因为它更新Q值而不必对所遵循的实际策略做出任何假设。Q-learning算法简单地规定使用使得在下一状态s(t+1)s(t+1)的Q值最大的s(t+1)s(t+1)和行为a(t+1)a(t+1)的Q值更新对应于状态s(t)s(t)和动作a(t)a(t)的Q值。
无模型算法
无模型强化学习算法是不使用任何其他外界事物来确定代理如何与环境交互的算法。
无模型算法通过策略迭代或值迭代等算法直接估计最优策略或值函数。这在计算方面更加有效,但也需要更多的训练样例。
Hindsight Experience Replay: HER 算法
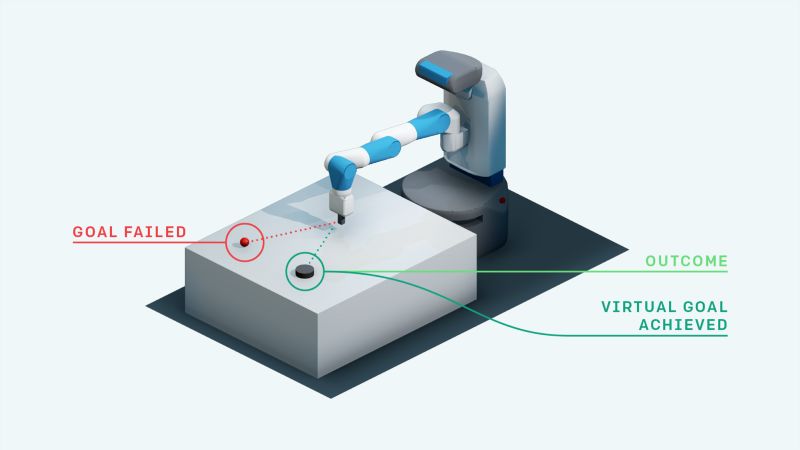
Hindsight Experience Replay (HER算法),是一种新的强化学习算法,该算法可以从失败中学习。它也可以从稀疏奖励中学习成功的策略。
我们可以看到FetchSlide(在桌子上滑动冰球并击中目标)来理解这一点。前几次尝试将不会很成功。典型的强化学习算法不会从这种经验中学到任何东西,因为它们只是获得了不包含任何学习信号的恒定奖励(在这种情况下:-1)。
HER算法做了人类直觉的做法:即使我们没有达到特定的目标,我们假装已经达到了冰球的目标。通过这样做,强化学习算法获得一些学习信号,因为他已经实现了某些目标。
Hindsight Experience Replay(通常用于DQN和DDPG等离线强化学习算法)。HER可与任何离线强化学习算法(DDPG+HER)结合使用,这使得该算法更加准确。
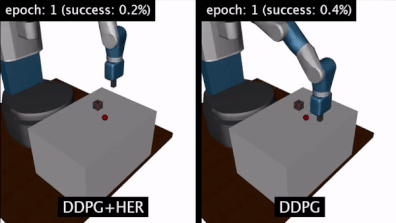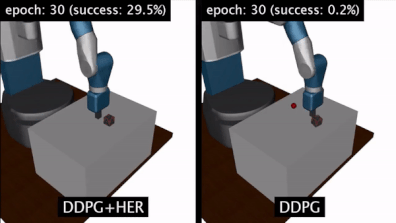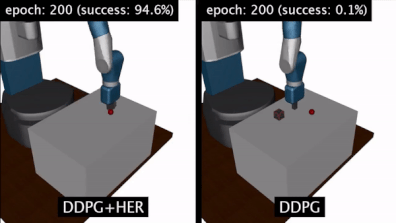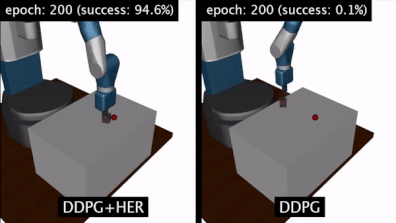
HER 算法:结果
做了以上操作之后,我测试了HER+DDPG算法和DDPG算法。我发现HER+DDPG算法在实现目标方面要快得多。
代码
这是我在OpenAI gym使用Pendulum环境下的示例代码。目标是通过简单的实现来了解一切应该如何协同工作。以下是主要的步骤:
1.设置数据结构以表示重放缓冲区。当被问及时,重放缓冲区返回随机选择的一批经验。
以下是一些示例代码:
from collections import deque
import random
import numpy as np
class ReplayBuffer(object):
def __init__(self, buffer_size):
self.buffer_size = buffer_size
self.count = 0
self.buffer = deque()
def add(self, s, a, r, t, s2):
experience = (s, a, r, t, s2)
if self.count < self.buffer_size:
self.buffer.append(experience)
self.count += 1
else:
self.buffer.popleft()
self.buffer.append(experience)
def size(self):
return self.count
def sample_batch(self, batch_size):
'''
batch_size specifies the number of experiences to add
to the batch. If the replay buffer has less than batch_size
elements, simply return all of the elements within the buffer.
Generally, you'll want to wait until the buffer has at least
batch_size elements before beginning to sample from it.
'''
batch = []
if self.count < batch_size:
batch = random.sample(self.buffer, self.count)
else:
batch = random.sample(self.buffer, batch_size)
s_batch = np.array([_[0] for _ in batch])
a_batch = np.array([_[1] for _ in batch])
r_batch = np.array([_[2] for _ in batch])
t_batch = np.array([_[3] for _ in batch])
s2_batch = np.array([_[4] for _ in batch])
return s_batch, a_batch, r_batch, t_batch, s2_batch
def clear(self):
self.buffer.clear()
self.count = 02.定义actor和critic网络
class ActorNetwork(object):
...
def create_actor_network(self):
inputs = tflearn.input_data(shape=[None, self.s_dim])
net = tflearn.fully_connected(inputs, 400)
net = tflearn.layers.normalization.batch_normalization(net)
net = tflearn.activations.relu(net)
net = tflearn.fully_connected(net, 300)
net = tflearn.layers.normalization.batch_normalization(net)
net = tflearn.activations.relu(net)
# Final layer weights are init to Uniform[-3e-3, 3e-3]
w_init = tflearn.initializations.uniform(minval=-0.003, maxval=0.003)
out = tflearn.fully_connected(
net, self.a_dim, activation='tanh', weights_init=w_init)
# Scale output to -action_bound to action_bound
scaled_out = tf.multiply(out, self.action_bound)
return inputs, out, scaled_out
class CriticNetwork(object):
...
def create_critic_network(self):
inputs = tflearn.input_data(shape=[None, self.s_dim])
action = tflearn.input_data(shape=[None, self.a_dim])
net = tflearn.fully_connected(inputs, 400)
net = tflearn.layers.normalization.batch_normalization(net)
net = tflearn.activations.relu(net)
# Add the action tensor in the 2nd hidden layer
# Use two temp layers to get the corresponding weights and biases
t1 = tflearn.fully_connected(net, 300)
t2 = tflearn.fully_connected(action, 300)
net = tflearn.activation(
tf.matmul(net, t1.W) + tf.matmul(action, t2.W) + t2.b, activation='relu')
# linear layer connected to 1 output representing Q(s,a)
# Weights are init to Uniform[-3e-3, 3e-3]
w_init = tflearn.initializations.uniform(minval=-0.003, maxval=0.003)
out = tflearn.fully_connected(net, 1, weights_init=w_init)
return inputs, action, outActor网络:
# This gradient will be provided by the critic network
self.action_gradient = tf.placeholder(tf.float32, [None, self.a_dim])
# Combine the gradients, dividing by the batch size to
# account for the fact that the gradients are summed over the
# batch by tf.gradients
self.unnormalized_actor_gradients = tf.gradients(
self.scaled_out, self.network_params, -self.action_gradient)
self.actor_gradients = list(map(lambda x: tf.div(x, self.batch_size), self.unnormalized_actor_gradients))
# Optimization Op
self.optimize = tf.train.AdamOptimizer(self.learning_rate).\
apply_gradients(zip(self.actor_gradients, self.network_params))Critic网络:
# Network target (y_i) # Obtained from the target networks self.predicted_q_value = tf.placeholder(tf.float32, [None, 1]) # Define loss and optimization Op self.loss = tflearn.mean_square(self.predicted_q_value, self.out) self.optimize = tf.train.AdamOptimizer(self.learning_rate).minimize(self.loss) # Get the gradient of the net w.r.t. the action self.action_grads = tf.gradients(self.out, self.action)我的完整项目Github代码可以在哪里找到。
期待
强化学习目前可能不是100%可部署使用的,但是像HER这样的方法每天都在进行研究,我很乐观我们将使用强化学习来优化工业机器人以更快地抵达未来。
想要继续查看该篇文章相关链接和参考文献?
点击底部【阅读原文】或长按下方地址/二维码访问:
https://ai.yanxishe.com/page/TextTranslation/1542


点击阅读原文,查看更多内容↙



