让智能体主动交互,DeepMind提出用元强化学习实现因果推理
选自arXiv
作者:Ishita Dasgupta等
机器之心编译
参与:Panda
因果推理能力可能是自然智能的重要组成部分,如何让机器具备这样的能力也一直是个重要的研究方向。不久之前,DeepMind、伦敦大学学院和哈佛大学的研究者探索了通过元强化学习实现因果推理的方法。

论文:https://arxiv.org/pdf/1901.08162.pdf
发现和利用环境中的因果结构是智能体面临的一大关键挑战。这里我们探索了是否可通过元强化学习来实现因果推理(cause reasoning)。我们使用无模型强化学习训练了一个循环网络来求解一系列包含因果结构的问题。我们发现,训练后的智能体能够在全新的场景中执行因果推理,从而获得奖励。智能体可以选择信息干预、根据观察数据得出因果推论以及做出反事实的预测。尽管也存在已有的形式因果推理算法,但我们在这篇论文中表明这样的推理可以由无模型强化学习产生,并提出这里给出的更多端到端的基于学习的方法也许有助于在复杂环境中的因果推理。通过让智能体具备执行——以及解释——实验的能力,本研究也能为强化学习中的结构化探索提供新的策略。
1 引言
很多机器学习算法的根基都是发现数据中的相关模式。尽管这种方法足以应对许多领域(Krizhevsky et al., 2012; Cho et al., 2014),但有时候我们感兴趣的问题具有固有的因果性质。在回答「吸烟是否导致癌症?」或「这个人工作被拒的原因是种族歧视吗?」或「是这个营销活动导致了销量上涨吗?」这些问题时,需要有推理因果的能力。因果推理可能是自然智能的一大关键组件,在人类婴儿、大鼠甚至鸟类身上都有体现(Leslie, 1982; Gopnik et al., 2001; 2004; Blaisdell et al., 2006; Lagnado et al., 2013)。
有关定义和执行因果推理的形式方法的文献很丰富(Pearl, 2000; Spirtes et al., 2000; Dawid, 2007; Pearl et al., 2016)。我们研究了能否通过元学习实现这样的推理。元学习方法是指直接从数据中学习「学习(或推断/估计)过程」自身。人类智能也与类比模型(Grant et al., 2018)有密切联系(Goodman et al., 2011),这种模型是直接从环境中学习因果结构,而没有一个预先设计的形式理论。
我们特别采用了之前的研究(Duan et al., 2016; Wang et al., 2016)引入的「元强化学习」,其中使用无模型强化学习(RL)方法训练了一个基于循环神经网络(RNN)的智能体。通过在多种类别的结构化任务上进行训练,这个 RNN 变成了一个能泛化到取自类似分布的新任务上的学习算法。在我们的案例中,我们在一个任务分布上进行了训练,其中每一个任务都有一个不同的因果结构作为支撑。我们关注的是能最好地隔离相关问题的抽象任务:当不向智能体明确提供因果概念时,元学习可否产生能执行因果推理的智能体。
元学习能端到端地学习,通过分摊计算而提供可扩展性的优势,该算法有望找到最适用于所需因果推理类型的因果结构的内部表征(Andrychowicz et al., 2016; Wang et al., 2016; Finn et al., 2017)。我们重点关注强化学习的原因是我们感兴趣的不仅是让智能体根据被动观察学习因果,而且也能通过与环境的主动交互来学习(Hyttinen et al., 2013; Shanmugam et al., 2015)。
2 问题说明与方法
我们研究了三种明显不同的数据设定——观察的、有干预的和反事实的。这些不同设定测试的是不同类型的推理。
在观察式设定中(实验 1),智能体仅能从环境中获取被动的观察数据。这种类型的数据可让智能体推断相关性(关联性推理/associative reasoning),并且还能根据环境的结构推断因果关系(因果性推理/cause-effect reasoning)。
在有干预的设定中(实验 2),智能体可通过设置某些变量的值以及观察对其它变量的影响而在环境中采取行动。这种类型的数据有助于对因果关系的估计。
在反事实的设定中(实验 3),智能体首先有机会通过交互来了解环境的因果结构。在 episode 的最后一步,它必须回答一个反事实的问题,该问题的形式为「如果在之前的时间步骤进行不同的干预会怎样?」
接下来我们将使用图模型框架(Pearl, 2000; Spirtes et al., 2000; Dawid, 2007)对这些设定以及每种设定中可能的推理模式进行形式化。随机变量用大写字母标注,它们的值用小写字母标注。
2.1 因果推理
随机变量之间的因果关系可以使用因果贝叶斯网络(CBN,详见补充材料)表示。CBN 是一种有向无环图模型,既能表示独立关系,也能表示因果关系。每个节点 X_i 对应于一个随机变量,并且联合分布 p(X_1,...,X_N) 是根据每个节点 X_i 的父节点 pa(X_i) 通过求每个节点 X_i 的条件分布的积而得到的,即:
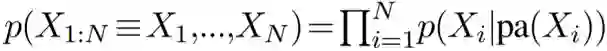
边带有因果语义信息:如果存在一条从 X_i 指向 X_j 的路径,则 X_i 就是 X_j 的一个潜在原因。有向路径也被称为因果路径。X_i 对 X_j 的因果影响是给定限定在仅有因果路径的 X_i 时 X_j 的条件分布。
图 1a 给出了一个 CBN 示例,其中 E 表示一周的锻炼小时数,H 表示心脏健康情况,A 表示年龄。E 对 H 的因果影响是限定在路径 E→H 的条件分布,即不包括路径 E←A→H。变量 A 被称为混杂变量(confounder),因为它将因果影响与非因果的统计影响混杂到了一起。只是通过 p(H|E) 基于锻炼水平观察心脏健康状况(关联性推理)不能解答锻炼水平改变是否会造成心脏健康变化的问题(因果性推理),因为总是存在这样的可能性:这两者之间的关联源自共有的年龄混杂变量。
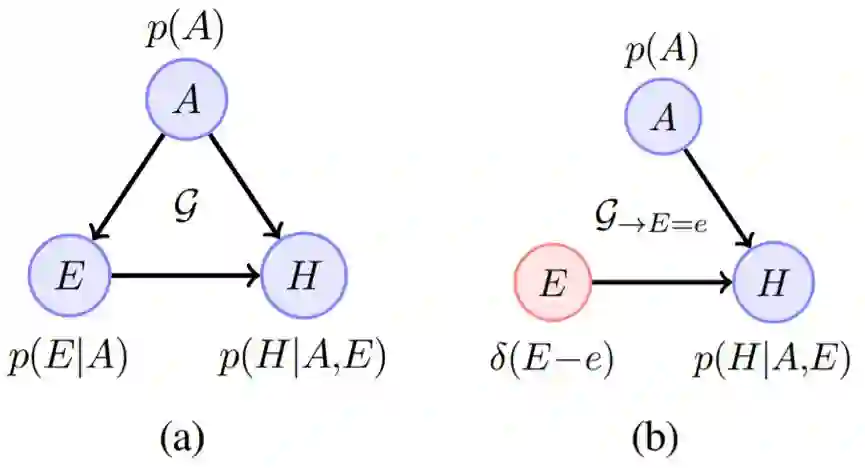
图 1:(a)有一个混杂变量的因果贝叶斯网络(CBN):年龄(A)和锻炼身体(E)对健康(H)的影响。(b)受干预 CBN,通过将 p(E|A) 替换成一个 δ 分布 δ(E−e) 而对前面的 CBN 进行了修改,条件分布 p(H|E,A) 和 p(A) 保持不变。
2.2 元学习
元学习是一类范围广泛的方法,其从数据中学习的是学习算法本身的各个方面。深度学习算法的很多单个组件都可通过元学习成功得到,包括优化器(Andrychowicz et al., 2016)、初始参数设置(Finn et al., 2017)、度量空间(Vinyals et al., 2016)、外部记忆的使用(Santoro et al., 2016)。
按照(Duan et al., 2016; Wang et al., 2016)的方法,我们将整个学习算法参数化为了一个循环神经网络(RNN),然后我们使用无模型强化学习来训练这个 RNN 的权重。这个 RNN 是在一个宽广的问题分布上训练的,其中每个问题都需要学习。当以这种方式训练时,RNN 可以实现能有效求解训练分布的同分布或相近分布中全新的学习问题(更多细节请参阅补充材料)。
通过无模型强化学习学习 RNN 的权重可被视为学习的「外环(outer loop)」。外环将 RNN 的权重整合进一个「内环」学习算法中。这个内环算法会在 RNN 的激活动态中一直执行,即使当该网络的权重被冻结时也能继续学习。这个内环算法也可以与用于训练它的外环算法有非常不同的性质。比如,在之前的工作中,这种方法曾被用于协调多臂赌博机问题中的探索-利用权衡(Duan et al., 2016),也曾被用于学习能动态调整自身学习率的算法(Wang et al., 2016; 2018)。我们在本研究中探索了获取可感知因果的内环学习算法的可能性。
3 任务设置和智能体架构
在我们的实验中,智能体在每个 episode 中都会和一个不同的 CBN 交互,这些 CBN 由 N 个变量定义。CBN 的结构是从可能的无环图空间中随机取出的,其取出方式的限定条件将在后续小节说明。
每个 episode 包含 T 个步骤,可分为两个阶段:信息阶段和测验阶段。信息阶段对应于前 T-1 个步骤,让智能体可通过与 CBN 交互或被动观察 CBN 的样本来收集信息。智能体有望使用这些信息来推断 CBN 的连接方式和权重。测验阶段对应于最后一个步骤,要求智能体利用其在信息阶段收集到的因果信息,从而在存在随机外部干预时选择出值最高的节点。
智能体架构和训练
我们使用了一个长短期记忆(LSTM)网络(Hochreiter and Schmidhuber, 1997)(有 192 个隐藏单元)。在每个时间步骤 t,该网络都接收一个包含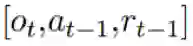
其输出是作为 LSTM 的隐藏状态的线性投射而计算的,是一组策略 logits(其维度等于可用动作的数量),加上一个标量基线。这个策略 logits 会由一个 softmax 函数变换,然后再被采样以给出一个所选的动作。
学习使用了异步优势 actor-critic(Mnih et al., 2016),其损失函数包含三项——策略梯度、基线成本和一个熵成本。基线成本由相对于策略梯度成本 0.05 进行加权。熵成本的权重是在训练过程中从 0.25 到 0 退火式衰减。优化由 RMSProp 完成,其 ε=10^-5,动量=0.9,衰减率=0.95。学习率从 9×10^−6 到 0 退火式衰减,折扣因子为 0.93。除非另有说明,训练完成要执行 1×10^7 步,使用了批大小为 1024 的分批式环境。
对于所有实验,在训练完成之后,都在一个留存测试集上对智能体进行测试,学习率设为零。
4 实验

图 2:实验 1。智能体根据观察数据执行因果性推理。a)实验中测试的智能体得到的平均奖励。b)在有外部干预的节点上根据至少存在或不存在一个父节点(分别表示为 Parent 和 Orphan)而划分的表现。c)一个测试 CBN 的测验阶段。绿色和红色边分别表示 +1 和 -1 的权重。黑色表示被干预的节点,绿色和红色节点分别表示该节点的值为正和负,白色表示为零。蓝色圆圈表示该智能体的选择。

图 3:实验 2。智能体根据干预数据执行因果性推理。a)实验中测试的智能体得到的平均奖励。b)在有外部干预的节点上根据存在或不存在未被观察的混杂变量(分别表示为 Conf. 和 Unconf.)而划分的表现。c)一个测试 CBN 的测验阶段。
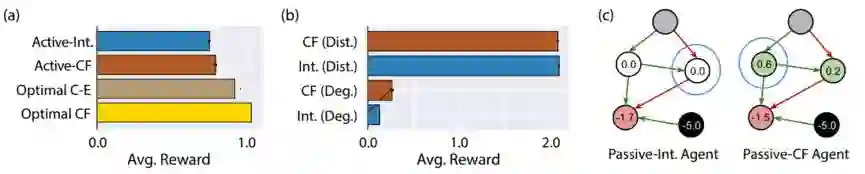
图 6:实验 3。智能体执行反事实推理。a)实验中测试的智能体得到的平均奖励。b)根据测验阶段中最大节点值是退化的(Deg.)或明显不同的(Dist.)而划分的表现。c)一个测试 CBN 的测验阶段。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


