这个高仿真框架AI2-THOR,想让让强化学习快速走进现实世界
夏乙 编译整理
量子位 出品 | 公众号 QbitAI
AlphaGo的节节胜利,向人们展示了强化学习的强大能力。但要是想让这种方法作用于现实世界,指挥机器人完成开门、拿东西、放东西等等对人类来说轻而易举的任务,还需要解决一个问题:
一个强化学习模型要经历多次试错过程才能收敛,可是让它在现实世界中一次一次地试错显然有些不切实际。

为了填平这道虚拟和现实世界中的鸿沟,一个名叫AI2-THOR的新框架产生了。
AI2-THOR是由艾伦人工智能研究所(AI2)、斯坦福大学、卡耐基梅隆大学、华盛顿大学、南加州大学合作完成的。它为人工智能Agent提供了一个室内装修效果图画风的世界,高度仿真,Agent可以和里面的各种家具家电交互——比如说打开冰箱、推倒椅子、把电脑放在桌子上等等。


为了让Agent与场景的交互尽可能接近真实,AI2-THOR除了包含表面上能看到的高质量3D场景之外,背后还有Unity 3D引擎,能让其中的物体遵循现实世界的物理规则来运动,也就是让交互动作尽可能真实。
另外,AI2-THOR还提供Python API。
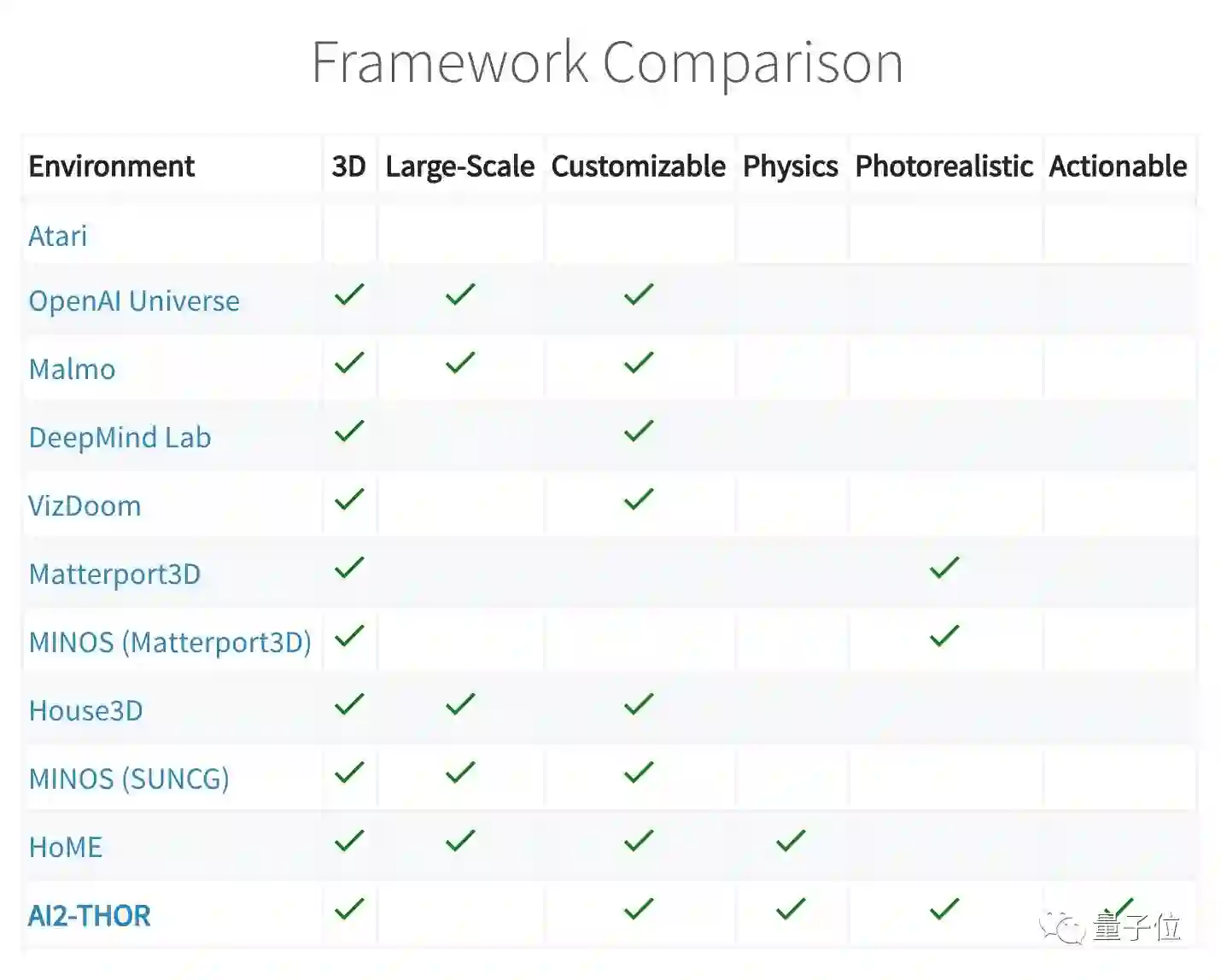
与同类框架相比,Agent可以操作场景中的物体,是AI2-THOR的一大亮点。它的真实性和对物理规则的整合,也是很少有框架具备的。
在提出这个框架的同时,这些研究人员还为了提高强化学习模型对新目标的泛化能力,提出了一个以当前状态和目标的函数为策略的演员-评论家模型。
这二者结合起来,达到了比最先进的深度强化学习方法更快的收敛速度,还能够泛化到各种目标和场景。
在模拟场景中训练的模型在经过少量微调后,甚至能泛化到真实的机器人活动场景。另外,他们的模型可以端到端地训练,不需要特征工程、图像之间的特征匹配和环境的3D重建。
项目主页:
http://ai2thor.allenai.org/
开源代码:
https://github.com/allenai/ai2thor
相关论文:
Visual Semantic Planning using Deep Successor Representations
Yuke Zhu, Daniel Gordon, Eric Kolve, Dieter Fox, Li Fei-Fei, Abhinav Gupta, Roozbeh Mottaghi, Ali Farhadi · ICCV 2017
https://arxiv.org/pdf/1705.08080.pdf
Target-driven visual navigation in indoor scenes using deep reinforcement learning
Yuke Zhu, Roozbeh Mottaghi, Eric Kolve, Joseph Lim, Abhinav Gupta, Fei-Fei Li, and Ali Farhadi · ICRA 2017
http://ai2-website.s3.amazonaws.com/publications/target_driven_visual.pdf
— 完 —
活动报名
加入社群
量子位AI社群12群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot4入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot4,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态




