【泡泡图灵智库】VoxelNet:基于点云的端到端3D物体检测网络(CVPR)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection
作者:Yin Zhou, Oncel Tuzel
来源:CVPR 2018
编译:黄文超
审核:刘小亮
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——VoxelNet:基于点云的端到端 3D 物体检测网络。
准确检测 3D 点云中的物体是许多应用中的核心问题,例如自主导航,管家机器人和 AR/VR。为了将高度稀疏的LiDAR点云与区域提议网络(RPN)连接起来,大多数现有的工作都集中在手工特征表示上,例如鸟瞰视图投影。在本文中,作者提出了 VoxelNet,该方法不再需要 3D 点云的手动特征工程,而是一种通用的 3D 检测网络,可将特征提取和边界框预测统一到一个单阶段、端到端的可训练深度网络中。具体而言,VoxelNet 将点云划分为等间隔的3D体素(Voxel),并通过新引入的体素特征编码(VFE)层将每个体素内的一组点转换为单一特征表示。通过这种方式,点云被编码为具有描述性的体积表示,然后将其连接到 RPN 以生成检测结果。KITTI 数据集上车辆检测的实验表明,VoxelNet 优于当前最先进的基于LiDAR 的 3D 检测方法。此外,该网络学习到了具有各种几何形状的、能够有效区别物体的特征描述,从而在仅基于 LiDAR的行人和骑车者的3D检测中产生良好的结果。
主要贡献
1、提出了端到端、可训练的深度网络架构 VoxelNet,用于 3D 检测,可以直接处理稀疏的 3D 点云,避免了由人工设计的特征引入的信息瓶颈(information bottlenecks)。
2、提出了该网络的高效实现方法,主要得益于稀疏的点云结构和体素网格的高效并行处理。
3、在 KITTI 数据集上进行了实验,展示了 VoxelNet 的 state-of-the-art 性能。
算法流程
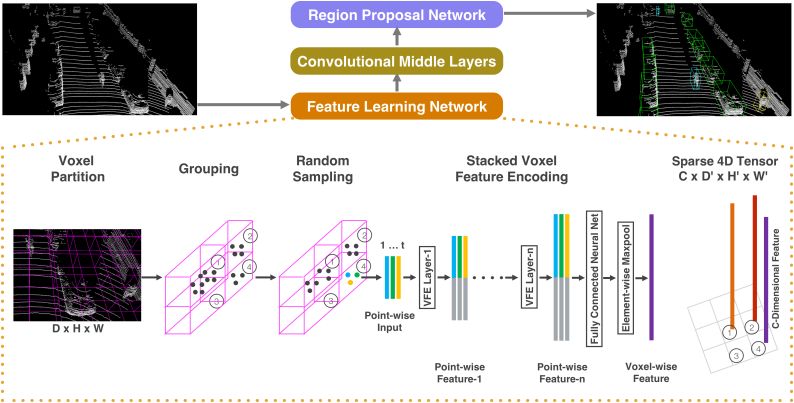
图1 VoxelNet网络架构
VoxelNet 由三个功能模块组成:1) 特征学习网络;2) 卷积中间层;3) 区域提议网络(RPN),如上图所示。
特征学习网络
首先对点云空间进行体素划分,得到 3 维的网格。随后根据各个点所在的网格进行分组,再对每个体素内的点进行随机采样,最多采样 T 个点。这里随机采样是由于 LiDAR 产生的点云通常点的数目很大且分布不均,采样后可以减小计算量,并且在一定程度上平衡点的分布。
在划分完之后有一步很重要的操作是体素特征编码 (VFE, Voxel Feature Encoding),VFE层对每一个非空体素进行特征提取和编码。对体素内的每个点连接一个全连接网络(注:原文中以 FCN 代指全连接网络,但一般 FCN 指的是全卷积神经网络)提取逐点的特征,接着对这些特征进行元素级的池化形成局部聚合特征,最后将局部聚合特征串接到每个点的特征上,这就完成了一次特征提取,如下图所示。依次堆叠VFE层可以获得更高层次的特征。
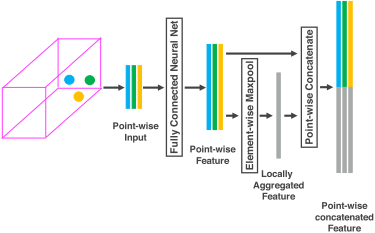
图2 VFE层
卷积中间层
与通常的 2 维卷积不同的是这里执行的是 3 维的卷积。在每个卷积层后依次是 BN 层和 ReLU 层。
区域提议网络(RPN)
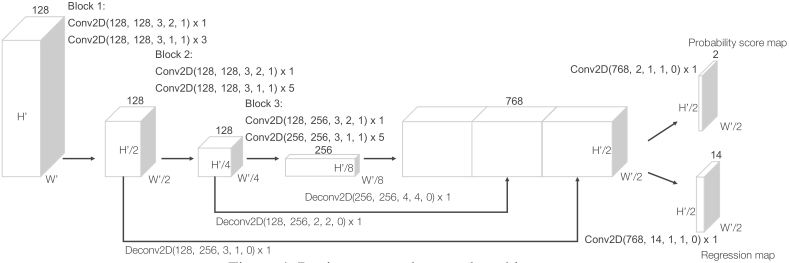
图3 RPN
RPN 由任少卿等人在 Faster R-CNN 中提出,现已是众多顶尖目标检测算法的重要组成模块。特征输入到 RPN 后经过降采样和上采样,再映射到两个期望的学习目标:分类概率得分图和回归图。网络的损失函数如下,包含分类误差和回归误差:
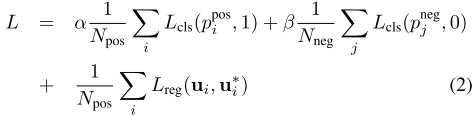
主要结果
作者在 KITTI 数据集上对算法进行了测试,结果如下:
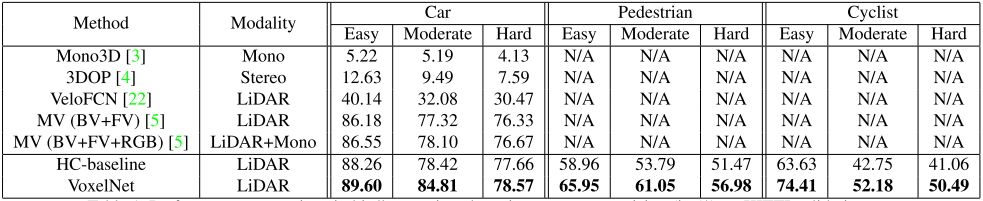
表1 鸟瞰视图下的检测性能对比
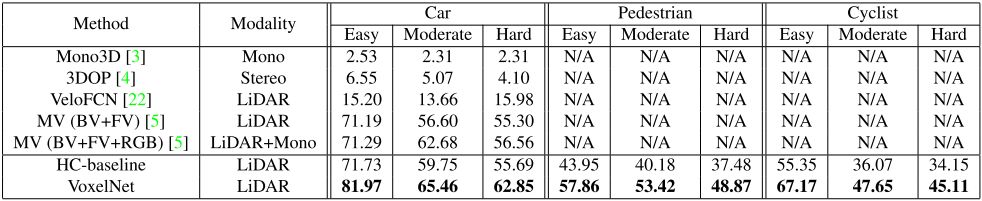
表2 3D检测性能对比

图4 检测结果

Abstract
Accurate detection of objects in 3D point clouds is a central problem in many applications, such as autonomous navigation, housekeeping robots, and augmented/virtual reality. To interface a highly sparse LiDAR point cloud with a region proposal network (RPN), most existing efforts have focused on hand-crafted feature representations, for example, a bird’s eye view projection. In this work, we remove the need of manual feature engineering for 3D point clouds and propose VoxelNet, a generic 3D detection network that unifies feature extraction and bounding box prediction into a single stage, end-to-end trainable deep network. Specifically, VoxelNet divides a point cloud into equally spaced 3D voxels and transforms a group of points within each voxel into a unified feature representation through the newly introduced voxel feature encoding (VFE) layer. In this way, the point cloud is encoded as a descriptive volumetric representation, which is then connected to a RPN to generate detections. Experiments on the KITTI car detection benchmark show that VoxelNet outperforms the state of the art LiDAR based 3D detection methods by a large margin. Furthermore, our network learns an effective discriminative representation of objects with various geometries, leading to encouraging results in 3D detection of pedestrians and cyclists, based on only LiDAR.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



