【泡泡图灵智库】Complex-YOLO:一个用于实时点云3D目标检测的欧拉区域提议网络(arXiv)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Complex-YOLO: An Euler-Region-Proposal for Real-time 3D Object Detection on Point Clouds
作者:Martin Simon, Stefan Milz, Karl Amende, Horst-Michael Gross
来源:arXiv:1803.06199v2 [cs.CV] 24 Sep 2018
编译:黄文超
审核:刘小亮
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——Complex-YOLO:一个用于实时点云3D目标检测的欧拉区域提议网络,该文章发表于arXiv[cs.CV] 2018。
基于激光雷达的3D目标检测对于自动驾驶来说不可避免,因为它与环境理解直接相关并且建立了预测和运动规划的基础。除了自动驾驶车辆,其他方面如增强现实、类人机器人和工业自动化中,在非常稀疏的3D数据中进行实时推断的能力是一个不适定问题。本文提出了Complex-YOLO,一个具有最先进性能的、只在点云上进行实时3D目标检测的网络。在这项工作中,作者通过特定的复数回归策略扩展了YOLOv2(一个用于RGB图像的快速2D目标检测网络),来在笛卡尔空间中估计多类别3D包围框。为此,作者提出了欧拉区域提议网络Euler-Region Proposal Network (E-RPN)来估计目标的位姿,添加虚函数和实函数到回归网络中。这样做的结果是能够有封闭的复数空间,避免了在单个角度估计中具有的奇异性。E-RPN泛化性能不错。作者在KITTI数据集上的实验显示,该方法胜过了当前最优秀的3D目标检测算法,尤其是效率。对应车、行人和骑自行车的人的检测结果,该方法达到了当前最优,但是速度提升比最快的算法还要超过五倍。
主要贡献
1、通过E-RPN的可靠角度回归估计3D包围框,提出了Complex-YOLO
2、在KITTI数据集上展示了Complex-YOLO的实时性能以及高准确率
3、使用e-RPN能够为每个3D包围框估计精确的朝向,由此可以估计该对象的轨迹
4、与其他基于激光雷达的方法相比,本文的方法能通过一次前向传递估计所有的类别
算法流程
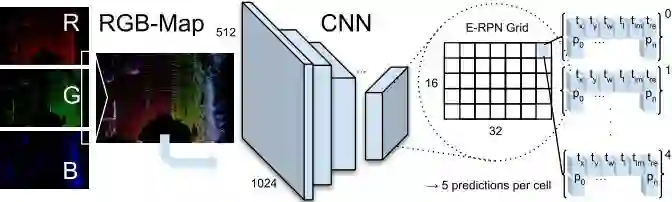
图2 Complex-YOLO总体流程
1、点云预处理

图4
每一帧由Velodyne HDL64获取的3D点云都转化成一张俯视图的RGB图像,包括80m x 40m的传感器前方范围(见图4)。RGB图像由高度、强度、密度编码。最后3D点云投影到2D网格中具有8cm的精度。范围内点的集合为PΩ,如下所示

考虑到 z 的范围是因为激光雷达的摆放高度为1.73m,这样大概可以包括进地面以上3m的区域。利用KITTI数据集给出的标定数据,可以定义将每个点云中的点映射到RGB图像中一个网格的映射函数Sj,描述这个映射的集合为:
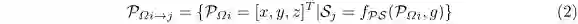
于是就可以计算每个像素的3个通道,其中zg代表了最大高度,zb为最大强度,zr为该网格内归一化的密度。
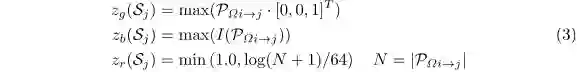
2、网络架构
Complex-YOLO网络接收上述RGB俯视图,使用简化的YOLOv2架构(见表1),并且使用E-RPN进行扩展。
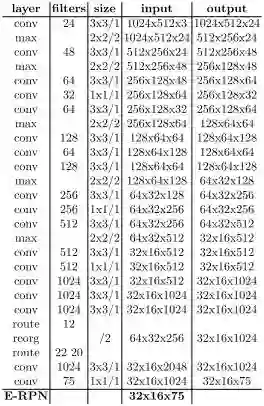
表1 Complex-YOLO网络结构
1. Euler-Region-Proposal,该网络接收CNN提取的特征图像,输出目标的3D位置,大小,类别概率和朝向。各参数定义如下
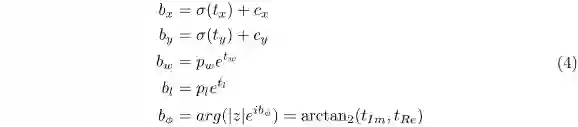
2. Anchor Box,作者根据尺寸和朝向定义了6种,尺寸分别是车辆、自行车、行人,朝向分别是正前和正后方。
3. 复角度回归,角度由atan2(im, re)得到。这样一方面可以避免奇异性,另一方面计算会有封闭的数学空间,从而对模型泛化有优势。
3、损失函数
扩展YOLO的损失函数为:

其中欧拉部分的损失函数定义为:
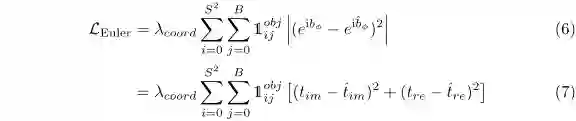
主要结果
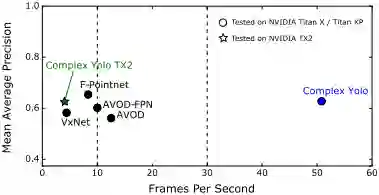
图5 性能比较
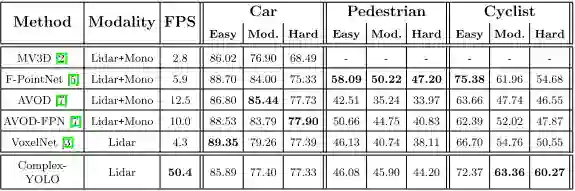
表2 俯视图检测的性能比较
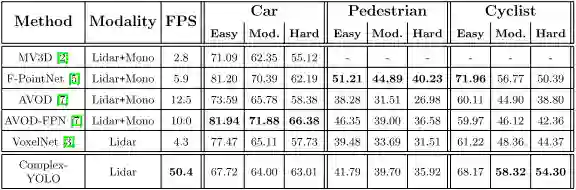
表3 3D目标检测的性能比较


图6 结果可视化

Abstract
Recently, 3D understanding research pays more attention to extracting the feature from point cloud [17, 19] directly. Therefore, exploring shape pattern description in points is essential. Inspired by SIFT [11] that is an outstanding 2D shape representation, we design a PointSIFT module that encodes information of different orientations and is adaptive to scale of shape. Specifically, an orientation-encoding unit is designed to describe eight crucial orientations. Thus, by stacking several orientation-encoding units, we can get the multi-scale representation. Extensive experiments show our PointSIFT-based framework outperform state-of-the-art method on standard benchmarking datasets. The code and trained model will be published accompanied by this paper.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



