机器之心 & ArXiv Weekly Radiostation
本周重要论文包括 DeepMind 从头开始构建、用伪代码详解 Transformer 的新研究,以及用于任意分辨率、长度和维度数据的通用 CNN 架构——CCNN。
-
Face2Faceρ : Real-Time High-Resolution One-Shot Face Reenactment
-
Formal Algorithms for Transformers
-
Next-ViT: Next Generation Vision Transformer for Efficient Deployment in Realistic Industrial Scenarios
-
Towards a General Purpose CNN for Long Range Dependencies in ND
-
Beyond neural scaling laws: beating power law scaling via data pruning
-
Greedy when Sure and Conservative when Uncertain about the Opponents
-
Few-shot X-ray Prohibited Item Detection: A Benchmark and Weak-feature Enhancement Network
-
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Face2Face^ρ : Real-Time High-Resolution One-Shot Face Reenactment
-
-
项目地址:https://github.com/NetEase-GameAI/Face2FaceRHO
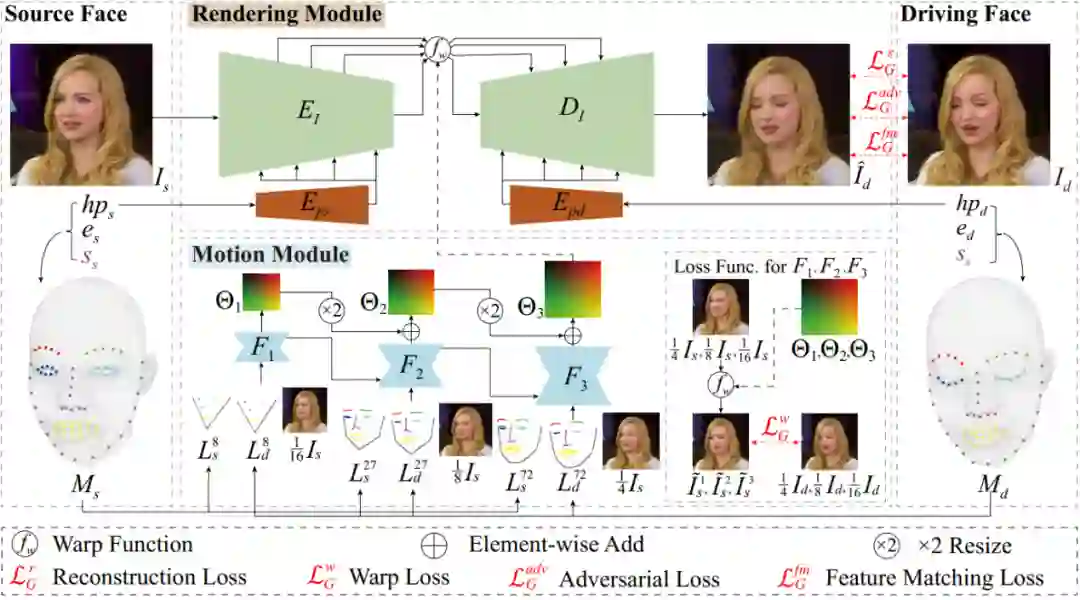
摘要:近年来,面部重演 (Face Reenactment) 技术因其在媒体、娱乐、虚拟现实等方面的应用前景而备受关注,其最直接的帮助就是能够帮助提升音视频的制作效率。面部重演算法是一类以源人脸图像作为输入,可以将驱动人脸的面部表情和头部姿态迁移到源图像中,同时保证在迁移过程中源人脸的身份不变。相关技术在虚拟主播、视频会议等媒体和娱乐应用方面都具有巨大潜力。但现有算法往往计算复杂度较高,性能无法满足实时应用环境的要求。
针对这一痛点,
网易互娱 AI Lab 提出了一种基于单幅图片的实时高分辨率人脸重演算法
,与已有 SOTA 方法相比,算法可以在保证结果质量的同时,最高可将算法速度提升至原来的 9 倍,
分别在台式机 GPU 和手机端 CPU 上支持以实时帧率生成 1440x1440 和 256×256 分辨率的人脸重演图像
。
![]()
推荐:
网易互娱 AI Lab 提出首个基于单幅图片的实时高分辨率人脸重演算法。
论文 2:Formal Algorithms for Transformers
-
-
论文地址:https://arxiv.org/pdf/2207.09238.pdf
摘要:DeepMind 的研究者认为提供伪代码有很多用途,与阅读文章或滚动 1000 行实际代码相比,伪代码将所有重要的内容浓缩在一页纸上,更容易开发新的变体。他们最近发表的一篇论文《 Formal Algorithms for Transformers 》,
文章以完备的、数学上精确的方式来描述 Transformer 架构
。
![]()
推荐:
从头开始构建,DeepMind 新论文用伪代码详解 Transformer。
论文 3:Next-ViT: Next Generation Vision Transformer for Efficient Deployment in Realistic Industrial Scenarios
-
-
论文地址:https://arxiv.org/pdf/2207.05501.pdf
摘要:
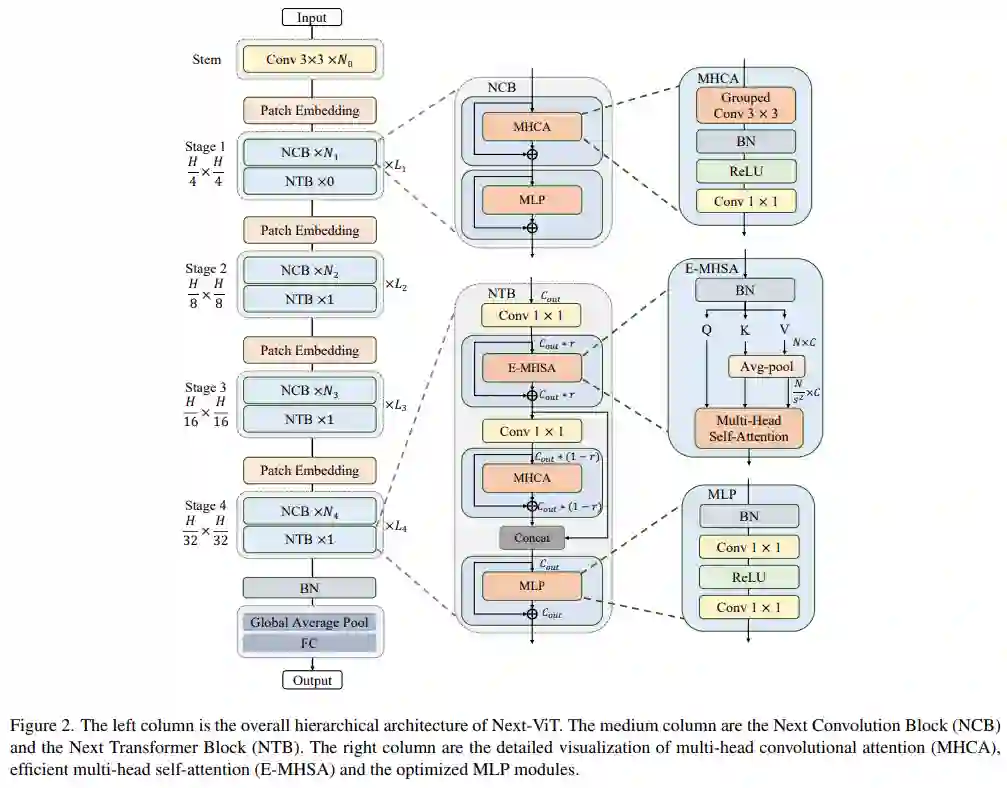
由于复杂的注意力机制和模型设计,大多数现有的视觉 Transformer(ViT)在现实的工业部署场景中不能像卷积神经网络那样高效执行。这就带来了一个问题:视觉神经网络能否像 CNN 一样快速推断并像 ViT 一样强大?近期一些工作试图设计 CNN-Transformer 混合架构来解决这个问题,但这些工作的整体性能远不能令人满意。
基于此,来自
字节跳动的研究者提出了一种能在现实工业场景中有效部署的下一代视觉 Transformer——Next-ViT
。从延迟 / 准确性权衡的角度看,Next-ViT 的性能可以媲美优秀的 CNN 和 ViT。
![]()
推荐:
解锁 CNN 和 Transformer 正确结合方法,字节跳动提出有效的下一代视觉 Transformer。
论文 4:Towards a General Purpose CNN for Long Range Dependencies in ND
-
-
论文地址:https://arxiv.org/pdf/2206.03398.pdf
摘要:
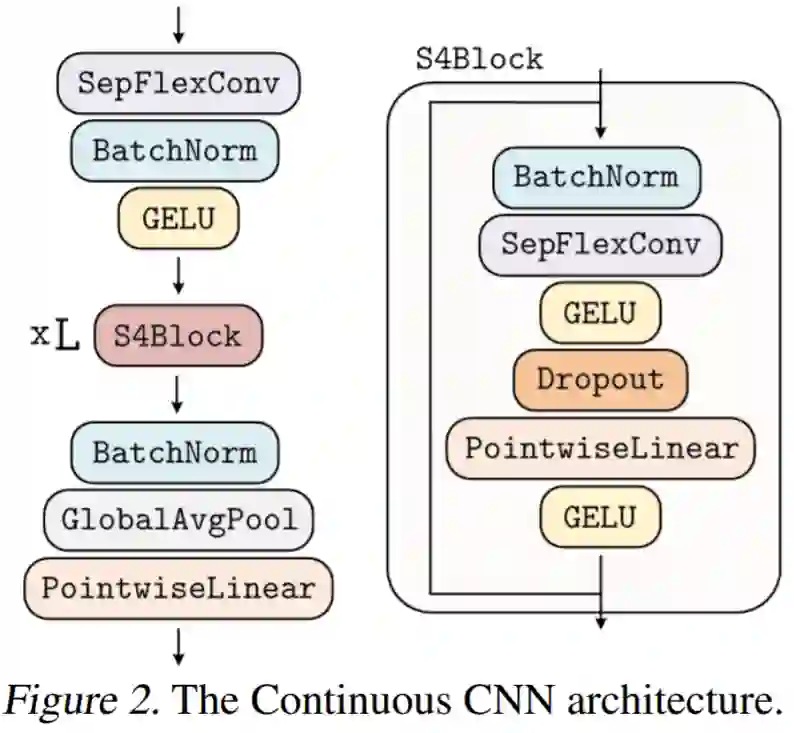
在 VGG、U-Net、TCN 网络中... CNN 虽然功能强大,但必须针对特定问题、数据类型、长度和分辨率进行定制,才能发挥其作用。我们不禁会问,可以设计出一个在所有这些网络中都运行良好的单一 CNN 吗?
本文中,
阿姆斯特丹自由大学、阿姆斯特丹大学、斯坦福大学的研究者提出了 CCNN,单个 CNN 就能够在多个数据集(例如 LRA)上实现 SOTA
。
![]()
推荐:
解决 CNN 固有缺陷, CCNN 凭借单一架构,实现多项 SOTA。
论文 5:Beyond neural scaling laws: beating power law scaling via data pruning
-
-
论文地址:https://arxiv.org/pdf/2206.14486.pdf
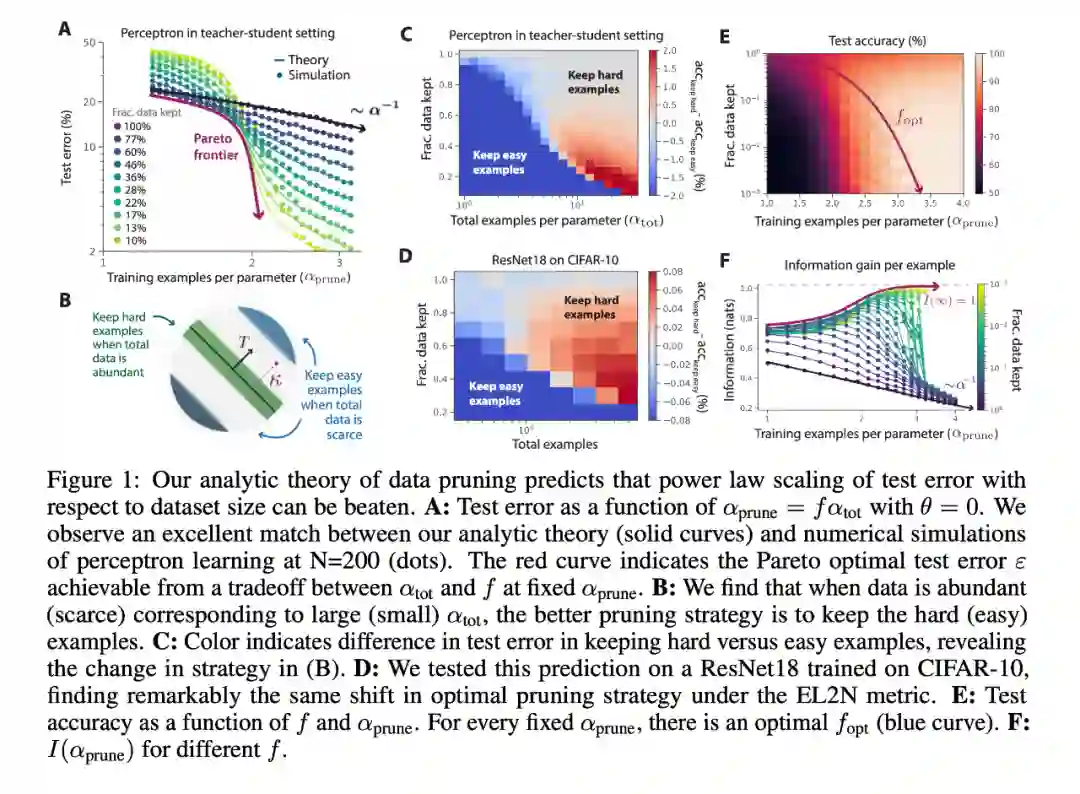
摘要:在视觉、语言和语音在内的机器学习诸多领域中,神经标度律表明,测试误差通常随着训练数据、模型大小或计算数量而下降。这种成比例提升已经推动深度学习实现了实质性的性能增长。然而,这些仅通过缩放实现的提升在计算和能源方面带来了相当高的成本。这种成比例的缩放是不可持续的。例如,想要误差从 3% 下降到 2% 需要的数据、计算或能量会指数级增长。此前的一些研究表明,在大型 Transformer 的语言建模中,交叉熵损失从 3.4 下降到 2.8 需要 10 倍以上的训练数据。
对于大型视觉 Transformer,额外的 20 亿预训练数据点 (从 10 亿开始) 在 ImageNet 上仅能带来几个百分点的准确率增长。所有这些结果都揭示了深度学习中数据的本质,同时表明收集巨大数据集的实践可能是很低效的。此处要讨论的是,我们是否可以做得更好。例如,我们是否可以用一个选择训练样本的良好策略来实现指数缩放呢?
在最近的一篇文章中,研究者们发现,
只增加一些精心选择的训练样本,可以将误差从 3% 降到 2% ,而无需收集 10 倍以上的随机样本
。简而言之,「Sale is not all you need」。
![]()
推荐:
斯坦福、Meta AI 新研究:实现 AGI 之路,数据剪枝比我们想象得更重要。
论文 6:Greedy when Sure and Conservative when Uncertain about the Opponents
-
-
论文地址:https://proceedings.mlr.press/v162/fu22b.html
摘要:当前业内知名的竞技游戏 AI,在与人对抗过程中往往采取固定的策略,这可能会带来两方面的性能损耗:[1] 如果这个 “固定” 策略有漏洞并且一旦被人发现,那么这个漏洞就可以被一直复现。换句话说,采取固定策略的 AI 容易被人 “套路”。[2] 采取固定策略的 AI 不能针对不同对手采取不同策略来获取更高的收益。例如,在二人石头 - 剪刀 - 布游戏中,如 AI 能针对有出剪刀倾向的对手多出石头,针对有出石头倾向的对手多出布,那么理论上 AI 能有更高的性能上限。
对此,
腾讯 AI Lab「绝艺」团队提出了一套 “对手建模” 算法框架,在游戏场景中可针对当前对手动态智能切换策略,实现见招拆招
。该方法在理论上和实际针对不同对手的实验中都能取得更高的收益,相关工作已被机器学习顶会 ICML 2022 收录。
![]()
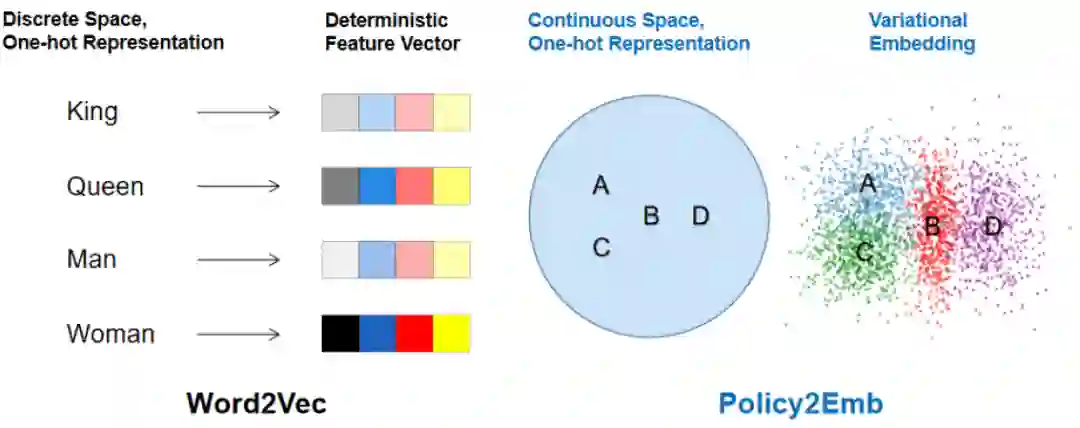
本文策略 embedding 学习方法 Policy2Emb 与经典词向量方法 Word2Vec 的一个对照。
推荐:
游戏 AI 学会见招拆招,腾讯 AI Lab 提出「对手建模」算法框架 GSCU。
论文 7:Few-shot X-ray Prohibited Item Detection: A Benchmark and Weak-feature Enhancement Network
-
-
开源链接:https://github.com/wytbwytb/WEN
摘要:近日,计算机多媒体顶级会议 ACM Multimedia 2022 接收论文结果已经正式公布,会议接收了一篇由北京航空航天大学、科大讯飞研究院共同完成的工作。这项工作以 X 光安检场景为例,针对一些危险品类别出现频率较低导致样本难以获取的现实情况,
构建了 X-ray FSOD 数据集,为 X 光下小样本检测任务提供模型检测能力评估基准
。
研究者在构建评估基准的基础上提出了微弱特征增强网络,利用原型学习和特征调和的思想缓解微弱特征带来的性能损失,为小样本检测带来新的思考。
![]()
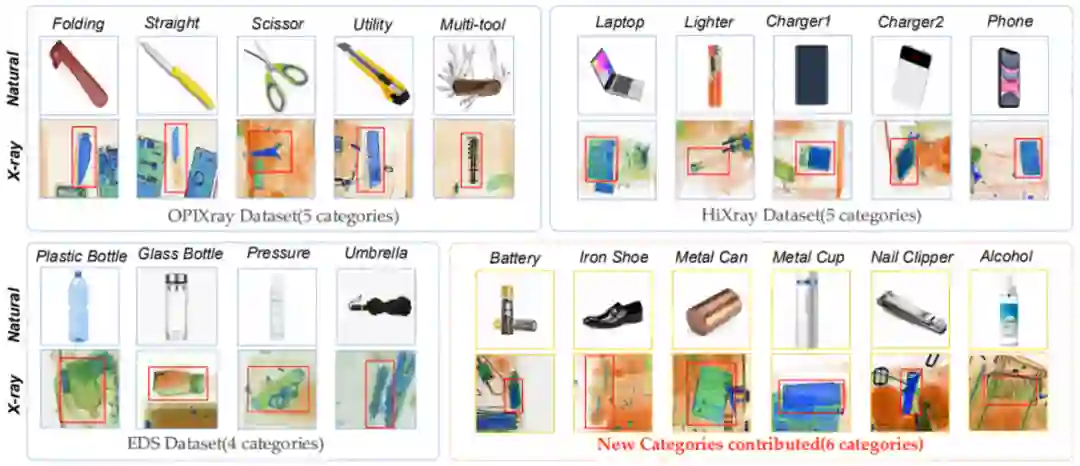
X-ray FSOD 数据集中不同类别的自然光和 X 光样例示意图。
推荐:首个 X 光下的小样本检测基准和弱特征增强网络,北航、讯飞新研究入选 ACM MM 2022。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. Language Model Cascades. (from Kevin Murphy)
2. Predicting Word Learning in Children from the Performance of Computer Vision Systems. (from Olga Russakovsky, Thomas L. Griffiths)
3. MRCLens: an MRC Dataset Bias Detection Toolkit. (from Eric P. Xing)
4. STOP: A dataset for Spoken Task Oriented Semantic Parsing. (from Emmanuel Dupoux, Abdelrahman Mohamed)
5. Doge Tickets: Uncovering Domain-general Language Models by Playing Lottery Tickets. (from Yi Yang)
6. LIP: Lightweight Intelligent Preprocessor for meaningful text-to-speech. (from Sumit Kumar)
7. CTL-MTNet: A Novel CapsNet and Transfer Learning-Based Mixed Task Net for the Single-Corpus and Cross-Corpus Speech Emotion Recognition. (from Yong Xu)
8. Reasoning about Actions over Visual and Linguistic Modalities: A Survey. (from Chitta Baral)
9. MoEC: Mixture of Expert Clusters. (from Furu Wei)
10. Automatic Context Pattern Generation for Entity Set Expansion. (from Yunbo Cao)
1. Is an Object-Centric Video Representation Beneficial for Transfer?. (from Andrew Zisserman)
2. StreamYOLO: Real-time Object Detection for Streaming Perception. (from Jian Sun)
3. Telepresence Video Quality Assessment. (from Alan Bovik)
4. The Caltech Fish Counting Dataset: A Benchmark for Multiple-Object Tracking and Counting. (from Pietro Perona)
5. Visual Knowledge Tracing. (from Pietro Perona)
6. On Label Granularity and Object Localization. (from Pietro Perona, Serge Belongie)
7. USegScene: Unsupervised Learning of Depth, Optical Flow and Ego-Motion with Semantic Guidance and Coupled Networks. (from Wolfram Burgard)
8. NeuForm: Adaptive Overfitting for Neural Shape Editing. (from Niloy J. Mitra, Leonidas Guibas)
9. LAVA: Language Audio Vision Alignment for Contrastive Video Pre-Training. (from John Canny)
10. SSMTL++: Revisiting Self-Supervised Multi-Task Learning for Video Anomaly Detection. (from Thomas B. Moeslund, Mubarak Shah)
1. DataPerf: Benchmarks for Data-Centric AI Development. (from Andrew Ng)
2. Assaying Out-Of-Distribution Generalization in Transfer Learning. (from Thomas Brox, Bernt Schiele, Bernhard Schölkopf)
3. Structural Causal 3D Reconstruction. (from Bernhard Schölkopf)
4. The MABe22 Benchmarks for Representation Learning of Multi-Agent Behavior. (from Pietro Perona)
5. Plex: Towards Reliability using Pretrained Large Model Extensions. (from Kevin Murphy, Zoubin Ghahramani)
6. Feasible Adversarial Robust Reinforcement Learning for Underspecified Environments. (from Pierre Baldi)
7. Why do tree-based models still outperform deep learning on tabular data?. (from Gaël Varoquaux)
8. Deep Learning and Its Applications to WiFi Human Sensing: A Benchmark and A Tutorial. (from Lihua Xie)
9. Subgroup Discovery in Unstructured Data. (from Martin Ester)
10. Neural Greedy Pursuit for Feature Selection. (from Yonina C. Eldar)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com